
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 자바 기초
- 자바의 정석 기초편 ch9
- 2024 정보처리기사 수제비 실기
- 자바 중급1편 - 날짜와 시간
- 2024 정보처리기사 시나공 필기
- 스프링 mvc2 - 타임리프
- 스프링 mvc2 - 검증
- 자바의 정석 기초편 ch14
- 자바의 정석 기초편 ch6
- 스프링 mvc2 - 로그인 처리
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch13
- 자바로 키오스크 만들기
- 스프링 mvc1 - 스프링 mvc
- 스프링 입문(무료)
- 람다
- 스프링 고급 - 스프링 aop
- 자바 중급2편 - 컬렉션 프레임워크
- 자바의 정석 기초편 ch12
- 자바 고급2편 - 네트워크 프로그램
- 자바로 계산기 만들기
- 자바의 정석 기초편 ch4
- 자바의 정석 기초편 ch7
- 데이터 접근 기술
- 자바의 정석 기초편 ch2
- @Aspect
- 자바 고급2편 - io
- 스프링 트랜잭션
- 자바의 정석 기초편 ch1
- 자바의 정석 기초편 ch11
Archives
- Today
- Total
개발공부기록
Java - 두 개 뽑아서 더하기, 가장 가까운 같은 글자 / SQL(MySQL) - 조건에 맞는 사용자와 총 거래금액 조회, 가격대 별 상품 개수 구하기, 즐겨찾기가 가장 많은 식당 정보 출력하기 본문
기타 개발 공부/온라인 코딩 테스트 회고
Java - 두 개 뽑아서 더하기, 가장 가까운 같은 글자 / SQL(MySQL) - 조건에 맞는 사용자와 총 거래금액 조회, 가격대 별 상품 개수 구하기, 즐겨찾기가 가장 많은 식당 정보 출력하기
소소한나구리 2025. 3. 18. 14:45728x90
JAVA
두 개 뽑아서 더하기
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/68644
- 정수 배열 numbers가 주어졌을 때 numbers에서 서로 다른 인덱스에 있는 두 개의 수를 뽑아 더해서 만들 수 있는 모든 수를 배열에 오름차순으로 담아 return 하는 함수를 완성
제한조건
- numbers의 길이는 2 이상 100이하이며 numbers의 모든 수는 0 이상 100 이하
입출력 예시
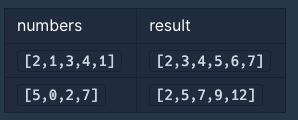
나의 풀이
import java.util.Arrays;
import java.util.Set;
import java.util.HashSet;
class Solution {
public int[] solution(int[] numbers) {
Set<Integer> set = new HashSet<>();
for (int i = 0; i < numbers.length; i++) {
for (int j = i; j < numbers.length; j++) {
if (i == j) {
continue;
}
set.add(numbers[i] + numbers[j]);
}
}
int[] answer = new int[set.size()];
int index = 0;
for (Integer i : set) {
answer[index++] = i;
}
Arrays.sort(answer);
return answer;
}
}- 우선 같은 배열에서 서로 다른 index의 요소를 각각 하나씩 뽑아야 했으므로 이중 반복문을 활용했다.
그러나 여기서 2번째 반복문의 j의 값을 i + 1로 하면 마지막 반복에서 인덱스를 벗어나 에러가 발생할 것으로 예상되어 어떤 것으로 할당해야 할지 고민을 하다가 int i = 0; int j = i;로 반복을 하기로 결정했다.- 전혀 아니다. 의미 없는 고민이였다
- j의 값을 i + 1로 설정하여 반복을 돌려도 어차피 j < numbers.length 까지 반복하기 때문에.. index 에러가 발생할 여지가 애초에 없었는데 잘못생각하고 문제를 풀었다.
- 여러번 더 고민하고 접근하자
여기서 문제는 i와 j가 같은 인덱스의 값을 꺼낸서 요구사항에 의미없는 계산을 한다는 것이였다손으로 일일히 풀어 보다가 여기서 j의 값을 i로 했을때 i와 j의 값이 같을때만 연산하지않고 넘기기만 하면 배열의 서로 다른 요소를 꺼낼 수 있다는 것을 알게 되어 if (i == j) continue;로 2중 반복문의 맨 처음을 건너뛰고 그 다음부터numbers[i] + numbers[j]를 연산했다.- 여기서 이 연산한 값이 중복이 되면 안되기 때문에 Set 자료 구조를 사용하여 연산한 값을 저장하고, 모든 반복이 끝난 후 set.size()만큼 새로 배열을 생성하여 set의 자료구조를 순회하여 새로 생성한 배열에 값을 하나씩 저장했다.
- 그 다음 오름차순으로 정렬한 후 반환하여 문제를 해결했다.
- 반복이 너무 많이 들어가서 효율적이진 않을 것 같은데 지금 단계에서 이 이상으로는 생각이 어려웠다.
다른 풀이
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] solution(int[] numbers) {
Set<Integer> set = new HashSet<>();
for(int i=0; i<numbers.length; i++) {
for(int j=i+1; j<numbers.length; j++) {
set.add(numbers[i] + numbers[j]);
}
}
return set.stream().sorted().mapToInt(Integer::intValue).toArray();
}
}- 이 풀이를 보고 에러가 나지 않기 위해 j의 값을 어떻게 할당할지 고민했던 것이 무의미한 고민이였다는 것을 알았다.
- set자료구조를 사용한 것은 나와 동일했으나 마지막에 set 자료구조를 stream()을 활용하여 정렬하고 mapToInt(Integer::intValue).toArray()를 통해서 int[]배열로 반환하는 스트림 코드가 가독성이 좋아 보여서 가져왔다.
import java.util.Set;
import java.util.TreeSet;
class Solution {
public int[] solution(int[] numbers) {
Set<Integer> set = new TreeSet<>();
for (int i = 0; i < numbers.length; i++) {
for (int j = i + 1; j < numbers.length; j++) {
set.add(numbers[i] + numbers[j]);
}
}
return set.stream().mapToInt(Integer::intValue).toArray();
}
}- 기본적으로 오름차순으로 정렬이 되는 TreeSet을 사용하면 중복값도 없고 오름차순도 적용되어 한번 더 정렬하는 로직을 제거할 수 있어서 조금 더 성능을 높일 수 있다
가장 가까운 같은 글자
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/142086
- 문자열 s가 주어졌을 때 s의 각 위치마다 자신보다 앞에 나왔으면서 자신과 가장 가까운 곳에 있는 같은 글자가 어디 있는지 찾는 함수를 작성
- s = "banana"라면 각 글자들을 왼쪽부터 오른쪽으로 읽어 나가면서 아래처럼 진행할 수 있음
- b가 처음 나옴, 자신의 앞에 같은 글자가 없음 => -1
- a가 처음 나옴, 자신의 앞에 같은 글자가 없음 => -1
- n이 처음 나옴, 자신의 앞에 같은 글자가 없음 => -1
- a가 자신보다 두 칸 앞에 먼저 나온 a가 있음 => 2
- n이 자신보다 2 칸 앞에 먼저 나온 n이 있음 => 2
- a가 자신보다 두 칸, 네 칸 앞에 먼저 나온 a가 있음, 둘 중 가까운 것은 두 칸 앞에 있음 => 2
- 최종 {-1, -1, -1, 2, 2, 2}
제한조건
- s의 길이는 1 이상 10,000 이하이며 s는 영어 소문자로만 이루어져있음
입출력 예시

나의 풀이
Map 자료구조 이용
import java.util.HashMap;
import java.util.Map;
class Solution {
public int[] solution(String s) {
Map<Character, Integer> lastCharIndex = new HashMap<>();
int[] answer = new int[s.length()];
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if(lastCharIndex.containsKey(c)) {
answer[i] = i - lastCharIndex.get(c);
} else {
answer[i] = -1;
}
lastCharIndex.put(c, i);
}
return answer;
}
}
- 먼저 주어진 문자열 s의 각 단어와 index번호를 저장할 Map<Character, Integer> lastCharIndex = new HashMap<>();을 선언했다
- Map 자료구조를 선택한 이유는 같은 key값으로 value가 들어오면 자동으로 나중에 온 값이 덮어쓰기 때문에 항상 마지막 위치를 유 지할 수 있게 된다.
- 그 이후 주어진 문자열만큼 반복을 하는데 s.charAt(i)로 문자열을 하나씩 뽑아서 lastCharIndex.containsKey()로 뽑아낸 문자열이 lastCharIndex에 저장되어있는지 확인한다.
- 만약 저장되어있다면 lastCharIndex.get(c)로 뽑은 문자열을 key값으로 하여 이미 저장되어있는 문자의 key값에 해당하는 index번호를 꺼낸다
- 그 다음 현재 문자의 index와 뺄셈 연산을 하면 현재 문자의 가장 가까운 문자가 얼마나 떨어져 있는지 알 수 있다
- 그게 아니라면 s.charAt(i)으로 뽑아낸 문자가 처음 나온것이므로 answer[i]에 기본값으로 -1을 입력한다.
- 반복이 1번씩 끝날 때마다 lastCharIndex.put(c, i)로 꺼낸 문자와 반복 횟수(현재 문자열의 index)를 저장해주면 한 번의 반복문으로 문제를 해결할 수 있다.
다른 풀이
getOrDefault() 이용
import java.util.*;
class Solution {
public int[] solution(String s) {
int[] answer = new int[s.length()];
HashMap<Character,Integer> map = new HashMap<>();
for(int i=0; i<s.length();i++){
char ch = s.charAt(i);
answer[i] = i-map.getOrDefault(ch,i+1);
map.put(ch,i);
}
return answer;
}
}- 내가 푼 풀이와 접근 방법은 동일한데, 꺼낼 값이 없다면 기본 값을 지정하여 반환하는 getOrDefault()함수를 사용한 풀이를 가져왔다.
- map에 이미 저장된 값이 있으면 해당 값을 꺼내서 반복된 회수(해당 문자의 index)와 이미 저장한 문자의 index위치를 뺄셈 연산하여 값을 반환하여 가까운 문자의 위치를 반환하고, 조회하는 key가 map에 없으면 i+1 을 반환하여 항상 -1이 저장되도록 작성했다.
- 조건을 분기하는 if문이 없어서 가독성이 더욱 좋다
IntStream 이용
import java.util.stream.IntStream;
class Solution {
public int[] solution(String s) {
return IntStream.range(0, s.length())
.map(i -> s.substring(0, i).lastIndexOf(s.charAt(i)) >
-1 ?
i - s.substring(0, i).lastIndexOf(s.charAt(i)) : -1)
.toArray();
}
}- 개인적으로 좀 과한 것 같긴해도 Stream을 활용하는 방법을 분석해보는 것이 좋을 것 같아서 가져왔다.
- IntStream.range(0, s.length())로 주어진 s,length -1 만큼 인덱스를 생성한다
- 그다음 .map을 사용하여 각 인덱스에서 요구사항을 만족하는 로직을 구현한다
- 삼항 연산자를 사용하기 위해 조건문을 작성할 때 먼저 i(스트림이 반복된 횟수)로 s.substring(0, i)을 통해 문자열을 자른다
- lastIndexOf(s.charAt(i))를 사용하여 문자열 s에서 i(현재 반복 회수)에 해당되는 문자를 가져온 다음 해당 문자가 잘라낸 문자열에서 마지막으로 등장한 위치를 찾아서 반환한다
- 만약 없으면 -1 을 반환하는데 이를 이용하여 s.substring(0, i).lastIndexOf(s.charAt(i)) > - 1 으로 삼항 연산자의 조건문을 완성한다
- 조건문이 true이면 잘라낸 문자열에 현재 반복의 인덱스에 해당하는 문자가 있다는 뜻이므로 'i - 조건문으로 찾은 index'를 계산한 결과를 반환한다
- 조건문이 false면 처음 꺼내진 값이므로 -1을 반환한다
- 다음 저장되는 값을 toArray()를 사용하여 배열로 최종 결과를 반환한다
SQL(MySQL)
조건에 맞는 사용자와 총 거래금액 조회하기
문제 및 테이블 예시
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/164668
- USED_GOODS_BOARD와 USED_GOODS_USER 테이블에서 완료된 중고 거래의 총금액이 70만 원 이상인 사람의 회원 ID, 닉네임, 총거래금액을 조회하는 SQL문을 작성
- 결과는 총거래금액을 기준으로 오름차순 정렬

입출력 예시

나의 풀이
SELECT
UGU.USER_ID, UGU.NICKNAME, SUM(UGB.PRICE) AS TOTAL_SALES
FROM
USED_GOODS_BOARD AS UGB
JOIN
USED_GOODS_USER AS UGU
ON
UGB.WRITER_ID = UGU.USER_ID
WHERE
UGB.STATUS = 'DONE'
GROUP BY
UGU.USER_ID
HAVING
TOTAL_SALES >= 700000
ORDER BY
TOTAL_SALES- 우선 게시글 작성자(USER_ID)정보와 닉네임, 그리고 거래 완료된 합계 금액을 구하기 위해선 두 테이블을 작성자와 USER_ID가 일치하는 정보로 두 테이블을 합칠 필요가 있어서 USED_GOODS_BOARD 테이블과 USED_GOODS_USER 테이블을 INNER JOIN 했다.
- 그 다음 거래 완료된 정보만 조회하기 위해 WHERE 절에 STATUS = 'DONE'으로 조건을 걸었다
- USER_ID의 거래 총 금액이 70만원 이상인 사람을 조회해야하기 때문에 USER_ID를 기준으로 GROUP BY를 하여 해당 유저가 올린 게시글의 총 금액이 얼마인지 그룹화를 진행했다
- 여기서 그룹화 조건을 700000 이상으로 설정하고 SELECT 절에 SUM(PRICE) AS TOTAL_SALES로 TOTAL_SALES라는 컬럼 이름으로 조건에 맞은 유저의 총 금액을 구했다
- 최종적으로 TOTAL_SALES를 오름차순으로 정렬하여 요구사항의 문제를 해결했다
가격대 별 상품 개수 구하기
문제 및 테이블 예시
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/131530
- PRODUCT 테이블에서 만원 단위의 가격대 별로 상품 개수를 출력하는 SQL문 작성
- 컬럼명은 PRICE_GROUP, PRODUCTS로 지정
- 가격대 정보는 각 구간의 최소금액으로 표시(10,000 ~ 20,000 구간인 경우 10,000으로 표시)
- 최종 결과는 가격대를 기준으로 오름차순 정렬

입출력 예시

나의 풀이
SELECT
FLOOR(PRICE / 10000) * 10000 AS PRICE_GROUP,
COUNT(FLOOR(PRICE / 10000)) AS PRODUCTS
FROM PRODUCT
GROUP BY PRICE_GROUP
ORDER BY PRICE_GROUP- 테이블이 하나라서 쉽게 구할 것 같았었는데 순간 멈칫했다, 가격대 별로 구하는 방법이 생각이 나질 않았기 때문이다.
- 처음에는 CASE 문으로 해야하나, IF 문으로 해야하나 조건을 여러개 줘야하나 이런식으로 조건문으로 밖에 생각이 나질 않아서 검색을 통해서 PRICE를 단위로 나눠서 1의 자리로 만들고 다시 그 단위로 곱하면 너무 쉽게 금액 단위를 구할 수 있다는 것을 알게되었다.
- 이런 알고리즘적인 사고를 떠올리는 것이 아직 쉽지 않다. 하지만 SQL 문법을 익히는 것뿐만 아니라 알고리즘 문제도 틈틈이 연습하며 사고력을 키울 필요가 있다고 느꼈다.
- 어쨋든 이 공식을 알고난 이후에는 일사 천리였다
- FLOOR(PRICE / 10000) * 10000 AS PRICE_GROUP 으로 각 가격대를 구했는데 여기서 FLOOR를 한 이유는 나눴을 때 소수점이 나오는 것을 모두 버리기 위해서이다.
- 그리고 각 가격대의 개수를 구하기 위해 COUNT(FLOOR(PRICE / 10000))를 사용하여 문제를 해결했다.
- 어차피 COUNT 함수는 NULL만 아니라면 그룹으로 나누어진 개수를 세는 것이 목적이기 때문에 COUNT(*)로 그룹화 된 개수를 세도 상관없으며 오히려 권장한다
- 그러므로 COUNT(PRICE / 10000)만으로도 당연히 통과되며 가장 명확하게 쿼리를 작성해야 해야한다면 개수를 쿼리문을 COUNT(FLOOR(PRICE / 10000) * 10000) AS PRODUCTS 이렇게 작성하는 것이 좋다.
즐겨찾기가 가장 많은 식당 정보 출력하기
문제 및 테이블 예시
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/131123
- REST_INFO 테이블에서 음식종류별로 즐겨찾기수가 가장 많은 식당의 음식 종류, ID, 식당 이름, 즐겨찾기수를 조회하는 SQL문을 작성
- 결과는 음식 종류를 기준으로 내림차순 정렬
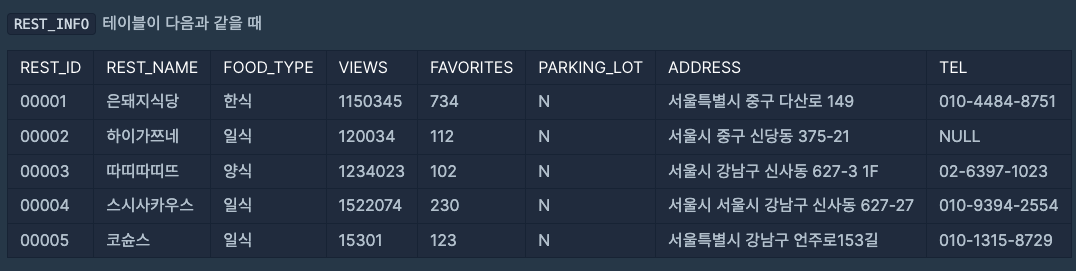
입출력 예시
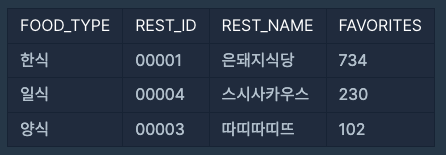
나의 풀이
WITH, JOIN 이용
WITH TYPE_MAX_FAVORITES AS (
SELECT FOOD_TYPE, MAX(FAVORITES) AS FAVORITES
FROM REST_INFO
GROUP BY FOOD_TYPE
)
SELECT
RI.FOOD_TYPE,
RI.REST_ID,
RI.REST_NAME,
RI.FAVORITES
FROM REST_INFO AS RI
JOIN TYPE_MAX_FAVORITES AS TMF
ON RI.FOOD_TYPE = TMF.FOOD_TYPE
AND RI.FAVORITES = TMF.FAVORITES
ORDER BY FOOD_TYPE DESC- 처음에는 TYPE_MAX를 GROUP BY로 그룹화 하여 MAX(FAVORITES)를 찾아보는 방법으로 시도 하였으나 제대로 결과가 나오지 않아서 검색과 AI툴을 활용해보니 GROUP BY를 잘못 사용하고 있다는 것을 알았다.
- 여기서는 GROUP BY를 이용하여 FOOD_TYPE을 하면 FOOD_TYPE별로 그룹을 묶었다
- 그리고 그룹화 하지 않은 다른 컬럼(여기에서는 REST_ID, REST_NAME 등)과 MAX(FAVORITES)를 사용했으므로 MAX(FAVORITES)로 가져온 값이 어떤 REST_ID, REST_NAME과 연결되는지 명확하지 않는다고 한다
- 즉 GROUP BY를 작성할 때 SELECT 절에 있는 컬럼들은 집계 함수(MAX(), MIN(), COUNT())로 감싸거나 GROUP BY에 포함되어야 하는데 다른 컬럼을 그룹화 하지 않았기 때문에 실패 한 것이다
- 그래서 이를 정상적으로 조회하기 위해서는 다른 방법이 필요한데 가장 먼저 WITH와 JOIN을 사용했다.
- 먼저 WITH문으로 REST_INFO 테이블에서 FOOD_TYPE으로 그룹화하여 FOOD_TYPE과 MAX(FAVORITES)를 조회하는 서브 쿼리를 만든다
- 그 다음 이 서브쿼리와 메인 쿼리를 INNER JOIN하는데 ON 조건을 기존 테이블의 FOOD_TYPE과 WITH의 그룹화된 FOOD_TYPE이 같고, 기존 테이블의 FAVORITES와 WITH의 FAVORITES가 같은값을 조건으로 주면 원하는 정보만 조회할 수 있다.
- 이 조건을 가지고 조회할 컬럼과 정렬 정보를 입력해주면 문제를 해결할 수 있다.
- JOIN 연산이 발생하여 테이블을 두 번 조회하는 단점이 있지만 대부분의 DB에서 JOIN은 최적화 되어있으므로 큰 성능저하도 없고 가독성도 좋은 풀이 방법이다
- 참고로 이 방법은 중복된 최대값을 포함하여 출력한다.
** WITH 설명
WITH 테이블_이름 AS (
SELECT 컬럼1, 컬럼2, ...
FROM 원본_테이블
WHERE 조건
)
SELECT *
FROM 테이블_이름;- WITH (Common Table Expression, CTE)는 일종의 임시 테이블(서브쿼리)을 만드는 역할을 한다
- WITH를 통해 만든 임시 테이블의 이름으로 쉽게 재사용을 할 수 있어 복잡한 쿼리에서 같은 서브 쿼리를 여러번 사용할 경우 성능이 향상되고 가독성도 좋아져 유용하다
윈도우 함수 활용 - ROW_NUMBER
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY FOOD_TYPE ORDER BY FAVORITES DESC) AS rn
FROM REST_INFO
) ranked
WHERE rn = 1
ORDER BY FOOD_TYPE DESC;- 인라인 뷰를 활용해 윈도우 함수인 ROW_NUMBER()를 사용하여 FOOD_TYPE 그룹에서 FAVORITES가 가장 높은 행을 rn = 1로 지정한다
- ROW_NUMBER()은 윈도우 함수의 대표적인 순위 매기기 함수이다.
- 이 한수는 각 행에 대해 순위를 매길 때 사용하며 PARTITION BY로 그룹을 나누고 ORDERY BY로 정렬 기준을 지정할 수 있다
- 행마다 고유한 순위를 부여하는데 같은 값이라도 다르게 순위를 매기기 때문에 중복된 순위를 가지지 않는다
- 같은 값이 있으면 같은 순위를 부여하는 함수로는 RANK(), DENSE_RANK()가 있는데 차이는 아래와 같다
- ROW_NUMBER(): 중복된 값이 있어도 무조건 순차 적용된다 -> 1, 2, 3, 4 ....
- RANK(): 1등이 동점이면 중복 1등을 표현하고 순위를 건너 뛴다 -> 1, 1, 3, 4 ....
- DENSE_RANK(): 1등이 동점이면 중복 1등이 있지만 순위를 건너 뛰지 않는다 -> 1, 1, 2, 3 ....
- 그 다음 메인 쿼리에서 rn = 1인 조건의 값만 가져오게 되면 FOOD_TYPE별로 가장 FAVORITES가 높은 값을 가져올 수 있다.
- JOIN이 없어서 가독성도 좋고 대량의 데이터에서 성능이 좋으나 일부 DB에서는 ROW_NUMBER()가 최적화 되지 않아 JOIN 보다 느릴 수 있고 윈도우 함수라는 것 자체를 알아야 사용할 수 있다
- 여기서는 ROW_NUMBER()를 사용했기 때문에 FAVORITES가 중복되어도 하나만 출력이 되며 위에서 설명한대로 중복된 내용을 포함하고 싶다면 RANK()나 DENSE_RANK()를 사용하면 된다
728x90
'기타 개발 공부 > 온라인 코딩 테스트 회고' 카테고리의 다른 글
'기타 개발 공부/온라인 코딩 테스트 회고' Related Articles
more



