
- 분류 전체보기 (439)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch13
- 자바의 정석 기초편 ch14
- 2024 정보처리기사 수제비 실기
- 자바 고급2편 - io
- @Aspect
- 자바 중급1편 - 날짜와 시간
- 자바의 정석 기초편 ch7
- 자바의 정석 기초편 ch1
- 2024 정보처리기사 시나공 필기
- 데이터 접근 기술
- 스프링 mvc2 - 검증
- 자바 고급2편 - 네트워크 프로그램
- 자바 기초
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch2
- 람다
- 자바의 정석 기초편 ch6
- 자바 중급2편 - 컬렉션 프레임워크
- 스프링 mvc2 - 로그인 처리
- 자바로 계산기 만들기
- 스프링 입문(무료)
- 스프링 고급 - 스프링 aop
- 자바의 정석 기초편 ch12
- 자바로 키오스크 만들기
- 스프링 트랜잭션
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch4
- 스프링 mvc2 - 타임리프
- 자바의 정석 기초편 ch9
- Today
- Total
개발공부기록
Chapter 02 - 데이터베이스 기초 활용 본문
2024년도 수제비 실기책(6판) 내용 정리
1. 데이터베이스 종류
1) 데이터베이스
(1) 데이터베이스(Database)개념
- 다수의 인원, 시스템 또는 프로그램에 사용할 목적으로 통합 하여 관리되는 데이터의 집합
- 데이터에 대한 효과적인 관리를 위해 자료의 중복성 제거, 무결성 확보, 일관성 유지, 유용성 보장이 중요함
- 데이터 베이스 정의
| 정의 | 설명 |
| 통합된 데이터(Integrated Data) | 자료의 중복을 배제한 데이터의 모임 |
| 저장된 데이터(Stored Data) | 저장 매체에 저장된 데이터 |
| 운영 데이터(Operational Data) | 조직의 업무를 수행하는 데 필요한 데이터 |
| 공용 데이터(Shared Data) | 여러 애플리케이션, 시스템들이 공동으로 사용하는 데이터 |
(2) 데이터 베이스 특성
| 특성 | 설명 |
| 실시간 접근성(Real-Time Accessibility) | 쿼리에 대하여 실시간 응답이 가능해야 한다는 특성 |
| 계속적인 변화(Continuous Evolution) | 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로 항상 최신의 데이터를 유지한다는 특성 |
| 동시 공용(Concurrent Sharing) | 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 한다는 특성 |
| 내용 참조(Content Reference) | 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라, 사용자가 요구하는 데이터 내용으로 데이터를 찾아야 한다는 특성 |
(3) DBMS(Database Management System) 개념
- 데이터 관리의 복잡성을 해결하는 동시에 데이터 추가, 변경, 검색, 삭제 및 백업, 복구, 보안 등의 기능을 지원하는 소프트웨어
- 저장되는 정보는 텍스트, 이미지, 음악 파일, 지도 데이터 등 매우 다양하며 SNS의 발달과 빅데이터의 폭넓은 활용으로 인해 데이터의 종류와 양은 급격히 증가 중임
2) 데이터베이스 저장 기술
(1) 데이터 웨어 하우스(DW; Data Warehouse)
[1] 개념 : 사용자의 의사결정에 도움을 주기 위하여, 기간 시스템의 데이터베이스에 축적된 데이터를 공통 형식으로 변환해서 관리하는 데이터베이스
[2] 특징
| 특성 | 설명 |
| 주제 지향적(Subject Oriented) | 기능이나 업무가 아닌 주체 중심적으로 구성되는 특징 |
| 통합적(Integrated) | 데이터의 일관성을 유지하면서 전사적 관점에서 하나로 통합되는 특징 |
| 시 계열적(Timevariant) | 시간에 따른 변경을 항상 반영하고 있다는 특징 |
| 비휘발적(Non-Volatile) | 적재가 완료되면 읽기 전용 형태의 스냅 샷 형태로 존재한다는 특징 |
(2) 데이터 마트(DM; Data Mart)
[1] 개념 : 전사적으로 구축된 데이터 속의 특정 주제, 부서 중심으로 구축된 소규모 단위 주제의 데이터 웨어하우스
[2] 특징 : 데이터 웨어 하우스 환경에서 정의된 접근계층으로 데이터 웨어하우스에서 데이터를 꺼내 사용자에게 제공하는 역할을 하고, 대개 특정한 조직 혹은 팀에서 사용하는 것을 목적으로 함,
[3] 빅데이터 특성
| 특성 | 설명 |
| 데이터의 양 (Volume) |
페타바이트 수준의 대규모 데이터 빅데이터 분석 규모에 관련된 특성 디지털 정보량이 기하급수적으로 폭증하는 것을 의미 |
| 데이터의 다양성 (Variety) |
정형, 비정형, 반정형의 다양한 데이터 빅데이터 자원 유형에 관련된 특성 로그, 소셜, 위치 등 데이터 유형이 다양해지는 것을 의미 |
| 데이터의 속도 (Velocity) |
빠르게 증가하고 수집되며, 처리되는 데이터 빅데이터 수집, 분석, 활용 속도와 관련된 특성 가치 있는 정보 활용을 위해 실시간 분석이 중요해지는 것을 의미 |
3) 하둡(Hadoop)
(1) 하둡의 개념
- 오픈 소스를 기반으로 한 분산 컴퓨팅 플랫폼
- 일반 PC급 컴퓨터들로 가상화된 대형 스토지리를 형성하고 그 안에 보관된 거대한 데이터 세트를 병렬로 처리할 수 있도록 개발된 자바 소프트웨어 프레임워크
(2) 하둡 주요 기술
| 구분 | 기술 | 설명 |
| 데이터수집 | ETL (Extract Tranform Load) |
데이터 분석을 위한 데이터를 데이터 저장소인 DW(Data Warehouse) 및 DM(Data Mart)으로 이동시키기 위해 다양한 소스 시스템으로부터 필요한 원본 데이터를 추출(Extract)하고 변환(Transform)하여 적재(Load)하는 작업 및 기술 |
| 플럼 (Flume) |
많은 양의 로그 데이터를 효율적으로 수집, 집계 이동하기 위해 이벤트(Event)와 에이전트(Agent)를 활용하는 기술 | |
| 스쿱 (Sqoop) |
커넥터(Connector)를 사용하여 관계형 데이터베이스 시스템(RDBMS)에서 하둡 파일 시스템(HDFS)으로 데이터를 수집하거나, 하둡 파일 시스템에서 관계형 데이터 베이스로 데이터를 보내는 기술 | |
| 스크래파이(Scrapy) | 파이썬 언어 기반의 비정형 데이터 수집 기술 | |
| 분산 데이터 저장 |
HDFS(Hadoop Distributed File System) |
대용량 데이터의 집합을 처리하는 응용 프로그램에 적합하도록 설계된 하둡 분산 파일 시스템 |
| 분산 데이터 처리 |
맵 리듀스 (Map Reduce) |
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작하여 2004년에 발표한 소프트웨어 프레임워크 |
(3) NoSQL
[1] NoSQL(Not Only SQL)의 개념
- 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인(Join) 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS
[2] NoSQL특성(BASE)
| 특성 | 설명 |
| Basically Available | 언제든지 데이터는 접근할 수 있어야 하는 속성 분산 시스템이기 때문에 항상 가용성 중시 |
| Soft-State | 노드의 상태는 내부에 포함된 정보에 의해 결정되는 것이 아니라 외부에서 전송된 정보를 통해 결정되는 속성 특정 시점에서는 데이터의 일관성이 보장되지 않음 |
| Eventually Consistency | 일정 시간이 지나면 데이터의 일관성이 유지되는 속성 일관성을 중시하고 지향 |
[3] NoSQL유형
| 유형 | 설명 |
| Key-Value Store | Unique한 Key에 하나의 Value를 가지고 있는 형태 키 기반 Get / Put / Delete 제공하는 빅데이터 처리 가능 DB ex) Redis, DynamoDB |
| Column Family Data Store | Key안에(Column, Value) 조합으로 된 여러 개의 필드를 갖는 DB 테이블 기반, 조인 미지원, 컬럼 기반, 구굴의 BigTable 기반으로 구현 ex) HBase, Cassandra |
| Document Store | Value의 데이터 타입이 Document라는 타입을 사용하는 DB Document타입은 XML, JSON, YAML과 같이 구조화된 데이터 타입으로 복잡한 계층 구조를 표현할 수 있음 ex) MongoDB, Couchbase |
| Graph Store | 시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DB ex) Neo4j, AllegroGraph |
**시맨틱웹(Semantic Web) : 온톨로지를 활용하여 서비스를 기술하고 온톨로지의 의미적 상호 운용성을 이용해서 서비스 검색, 조합, 중재 기능을 자동화하는 웹
** 온톨로지(Ontology) : 실세계에 존재하는 모든 개념들과 개념들의 속성, 그리고 개념들 간의 관계 정보를 컴퓨터가 이해할 수 있도록 서술해 놓은 지식 베이스
4) 데이터 마이닝
(1) 데이터 마이닝(Data Mining) 개념
- 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 기술
- 대규모 데이터에서 의미있는 패턴을 파악하거나 예측하여 의사결정에 활용하는 기법
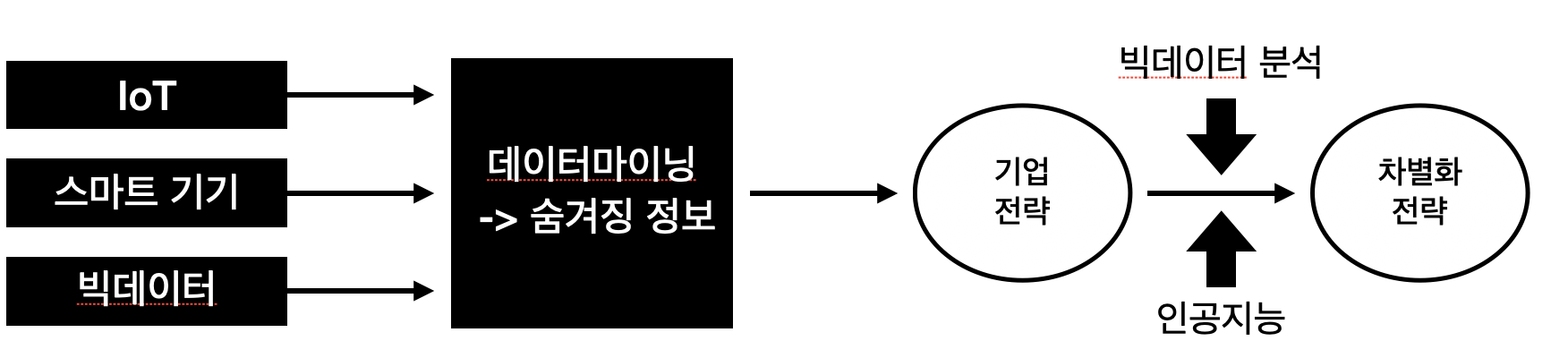
- 데이터의 숨겨진 정보를 찾아내어 이를 기반으로 서비스와 제품에 도익하는 과정
- 통계분석은 가설이나 가정에 따른 분석, 검증을 하지만 데이터 마이닝은 수리 알고리즘을 활용하여 대규모 데이터에서 의미 있는 정보를 찾아냄
(2) 데이터 마이닝 주요 기법
| 유형 | 설명 |
| 분류 규칙 (Classification) |
과거 데이터로부터 특성을 찾아내어 분류모형을 만들어 이를 토대로 새로운 레코드의 결과 값을 예측하는 기법 마케팅, 고객 신용평가 모형에 활용 ex) 우수 고객의 분류 모형 구축으로 마케팅 활용 |
| 연관 규칙 (Association) |
데이터 안에 존재하는 항목들 간의 종속관계를 찾아내는 기법 제품이나 서비스의 교차판매, 매장 진열, 사기 적발 등 다양한 분야에서 활용 ex) 넥타이 구매고객의 50% 이상이 셔츠를 구매한다는 정보 분석을 통해 매장의 상품 진열 |
| 연속 규칙 (Sequence) |
연관 규칙에 시간 관련 정보가 포함된 형태의 기법 개인별 트랜잭션 이력 데이터를 시계열적으로 분석하여 트랜잭션의 향후 발생 가능성 예측 ex) A 품목을 구매한 회원이 B품목을 구매할 확률은 75% |
| 데이터 군집화 (Clustering) |
대상 레코드들을 유사한 특성을 지닌 몇 개의 소그룹으로 분할하는 작업으로 작업의 특성이 분류규칙(Classification)과 유사 정보가 없는 상태에서 데이터를 분류하는 기법 분석대상에 결괏값이 없으며, 판촉활동이나 이벤트 대상을 선정하는 데 활용 ex) 고객의 지역/연령/성별에 따른 차별화 홍보 전략 |
5) 데이터 관련 용어
- 텍스트 마이닝(Text Mining) : 대량의 텍스트 데이터로부터 패턴 또는 관계를 추출하여 의미 있는 정보를 찾아내는 기법
- 웹 마이닝(Web Mining) : 웹으로부터 얻어지는 방대한 양의 정보로부터 유용한 정보를 찾아내기 위하여 분석하는 기법
- 다크 데이터(Dark Data) : 수집된 후 저장은 되어있지만, 분석에 활용되지는 않는 다량의 데이터
- 메타 데이터(Meta Data) : 데이터에 대한 구조적인 데이터로서, 일련의 데이터를 정의하고 설명해주는 데이터이고, 구축할 정보 자원을 기술하는 데이터
- 디지털 아카이빙(Digital Archiving) : 지속적으로 보존할 가치를 가진 디지털 객체를 장기간 관리하여 이후의 이용을 보장할 수 있도록 변환, 압축 저장하여 DB화 하는 작업
- 마이 데이터(My Data) : 정보 주체가 기관으로부터 자기 정보를 직접 내려받아 이용하거나 제3자 제공을 허용하는 방식으로 정보 주체 중심의 데이터활용 체계, 개인이 정보 관리의 주체가 되어 능동적으로 본인의 정보를 관리하고 본인의 의지에 따라 신용 및 자산관리 등에 정보를 활용하는 일련의 과정
'2024 정보처리기사 2차 합격 > 실기 3강 - 데이터 입출력 구현' 카테고리의 다른 글
| Chapter 02 - 데이터베이스 기초 활용(기출문제, 예상문제), Chapter 03 - 단원종합문제 (0) | 2024.06.29 |
|---|---|
| Chapter 01 - 데이터 저장소(기출문제,예상문제) (0) | 2024.06.27 |
| Chapter 01 - 데이터 저장소(2) (0) | 2024.06.27 |
| Chapter 01 - 데이터 저장소(1) (0) | 2024.06.27 |



