
- 분류 전체보기 (347)

- 프로젝트, 개발 공부 회고 (4)
- 인프런 - 스프링 완전정복 코스 로드맵 (98)
- 인프런 - 스프링부트와 JPA실무 로드맵 (30)
- 인프런 - 실전 자바 로드맵 (10)
- 책 공부 (3)
- 유튜브 공부 (75)
- 2024정보처리기사 준비 정리(필기 - 시나공, 실기 - 수제비) (127)
- 필기 1강 - 소프트웨어 설계 (17)
- 필기 2강 - 소프트웨어 개발 (16)
- 필기 3강 - 데이터베이스 구축 (13)
- 필기 4강 - 프로그래밍 언어 활용 (8)
- 필기 5강 - 정보시스템 구축 관리 (13)
- 실기 6강 - 프로그래밍 언어 활용 (22)
- 실기 1강 - 요구사항 확인(일부분), 2강 - 화면설계(일부분) (3)
- 실기 3강 - 데이터 입출력 구현 (5)
- 실기 7강 - SQL 응용 (7)
- 실기 9강 - 소프트웨어 개발 보안 구축 (8)
- 실기 10강 - 애플리케이션 테스트 관리 (5)
- 실기 11강 - 응용 SW 기초 기술 활용 (10)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 스프링 mvc2 - 로그인 처리
- 2024 정보처리기사 수제비 실기
- 자바의 정석 기초편 ch3
- 자바의 정석 기초편 ch6
- 자바의 정석 기초편 ch8
- jpa 활용2 - api 개발 고급
- 자바의 정석 기초편 ch12
- jpa - 객체지향 쿼리 언어
- @Aspect
- 스프링 고급 - 스프링 aop
- 스프링 mvc2 - 검증
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch1
- 타임리프 - 기본기능
- 스프링 db2 - 데이터 접근 기술
- 자바의 정석 기초편 ch11
- 2024 정보처리기사 시나공 필기
- 코드로 시작하는 자바 첫걸음
- 자바의 정석 기초편 ch13
- 스프링 입문(무료)
- 자바의 정석 기초편 ch2
- 자바의 정석 기초편 ch9
- 자바의 정석 기초편 ch14
- 자바의 정석 기초편 ch7
- 스프링 mvc1 - 서블릿
- 스프링 mvc2 - 타임리프
- 자바의 정석 기초편 ch4
- 게시글 목록 api
- 스프링 db1 - 스프링과 문제 해결
- Today
- Total
나구리의 개발공부기록
Chapter 01 - 데이터 저장소(2) 본문
Chapter 01 - 데이터 저장소(2)
소소한나구리 2024. 6. 27. 17:042024년도 수제비 실기책(6판) 내용 정리
6) 정규화
(1) 이상 현상(Anomaly)
- 데이터의 중복성으로 인해 릴레이션(열과 행으로 구성된 테이블)을 조작할 때 발생하는 비합리적인 현상
- 삽입 이상 : 정보 저장 시 해당 정보의 불필요한 세부 정보를 입력해야 하는 경우
- 삭제 이상 : 정보 삭제 시 원치 않는 다른 정보가 같이 삭제 되는 경우
- 갱신 이상 : 중복 데이터 중에서 특정 부분만 수정되어 중복된 값이 모순을 일으키는 경우
< 이상 현상 발생 테이블 >
| 학번 | 이름 | 교수번호 | 지도교수 |
| 202001 | 홍길동 | 1 | 김 교수 |
| 202002 | 김영희 | 2 | 이 교수 |
1. 삽입 이상 발생 : 202003학번을 가진 이철수라는 학생을 등록할 경우, 지도교수가 정해지지 않으면 삽입할 수 없음
| 학번 | 이름 | 교수번호 | 지도교수 |
| 202001 | 홍길동 | 1 | 김 교수 |
| 202002 | 김영희 | 2 | 이 교수 |
| 202003 | 이철수 | ? | ? |
2. 삭제 이상 : 이 교수가 퇴사를 하여 이 교수를 삭제 하였는데, 김영희라는 학생 정보가 함께 삭제 됨
| 학번 | 이름 | 교수번호 | 지도교수 |
| 202001 | 홍길동 | 1 | 김 교수 |
3. 갱신 이상 : 홍길동 이라는 학생의 지도교수를 이 교수로 변경할 경우 이 교수의 교수번호가 2, 3 모두 있게 되어 중복된 값이 모순을 일으킴
| 학번 | 이름 | 교수번호 | 지도교수 |
| 202001 | 홍길동 | 3 | 이 교수 |
| 202002 | 김영희 | 2 | 이 교수 |
(2) 함수 종속
[1] 함수 종속(FD: Function Dependency) 개념
- 릴레이션에서 속성의 의미와 속성 간 상호 관계로부터 발생하는 제약조건
[2] 결정자/종속자
- X ➝ Y 관계일 때 X는 결정자(Determinant), Y는 종속자(Dependency)
[3] 함수 종속 종류
| 종류 | 설명 |
| 부분 함수 종속 (Partial Functional Dependency) |
릴레이션에서 기본 키가 복합 키일 경우 기본 키를 구성하는 속성 중 일부에게 종속 된 경우 |
| 완전 함수 종속 (Full Functional Dependency) |
릴레이션에서 X ➝ Y 관계가 있을 때, Y는 X의 전체 속성에 대해 종속하고, 부분 집합 속성에 종속하지 않는 경우 |
| 이행 함수 종속 (Transitive Fucntional Dependency) |
릴레이션에서 X ➝ Y ➝ Z 종속 관계가 있을 때 X ➝ Z 가 성립되는 경우 |
(3) 정규화(Normalization)의 개념
- 관계형 데이터 모델에서 데이터의 중복성을 제거하여 이상 현상을 방지하고 데이터의 일관성과 정확성을 유지하기 위해 무손실 분해하는 과정
| 단계 | 조건 |
| 1정규형(1NF) | 도메인이 원자값 |
| 2정규형(2NF) | 부분 함수 종속 제거(완전 함수적 종속 관계) |
| 3정규형(3NF) | 이행 함수 종속 제거 |
| 보이스-코드 정규형(BCNF) | 결정자 후보 키가 아닌 함수 종속 제거(결정자가 후보키) |
| 4정규형(4NF) | 다치(다중 키) 종속 제거 |
| 5정규형(5NF) | 조인 종속 제거 |
[1] 1차 정규화(1NF; 1 Normal Form)
- 원자값으로 구성, 반복 속성/ 중복 제거가 필요한 정규화 과정
- 테이블 내의 속성은 원자값을 가지고 있어야 함
- 이메일 주소가 속성에 2개이상 가지고 있는 경우 원자값이 아니기 때문에 속성 1개만 가지도록 저장하면 1차 정규화를 만족함

[2] 2차 정규화(2NF; 2 Normal Form)
- 부분함수 종속 제거(완전 함수적 종속 관계), 주식별자 아닌 속성을 분리하는 정규화 과정
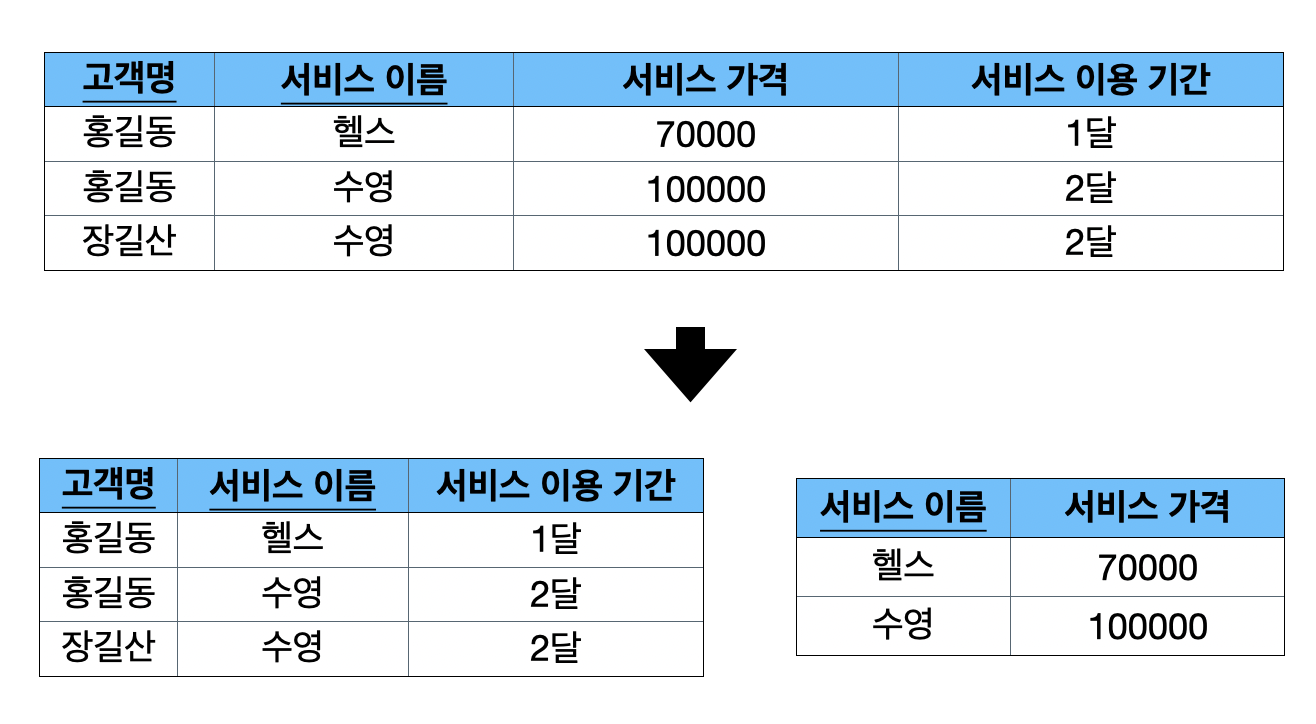
- <고객명, 서비스 이름> 이 <서비스 이용 기간>에 영향을 주고, <서비스 이름>이 <서비스 가격>에 영향을 주는 관계를 부분함수 종속관계 라고함
- <고객명, 서비스 이름, 서비스 가격, 서비스 이용 기간>을 한 테이블에 두는 것은 부분함수 종속성으로 인해 2차 정규화를 만족하지 못함
- 부분 관계인 <서비스 이름, 서비스 가격> 관계를 별도의 테이블로 두면 부분 함수 종속 관계가 제거되어 2차 정규화를 만족시킴

[3] 3차 정규화(3NF; 3 Normal Form)
- 이행함수 종속 제거, 속성에 종속적인 속성을 분리하는 정규화
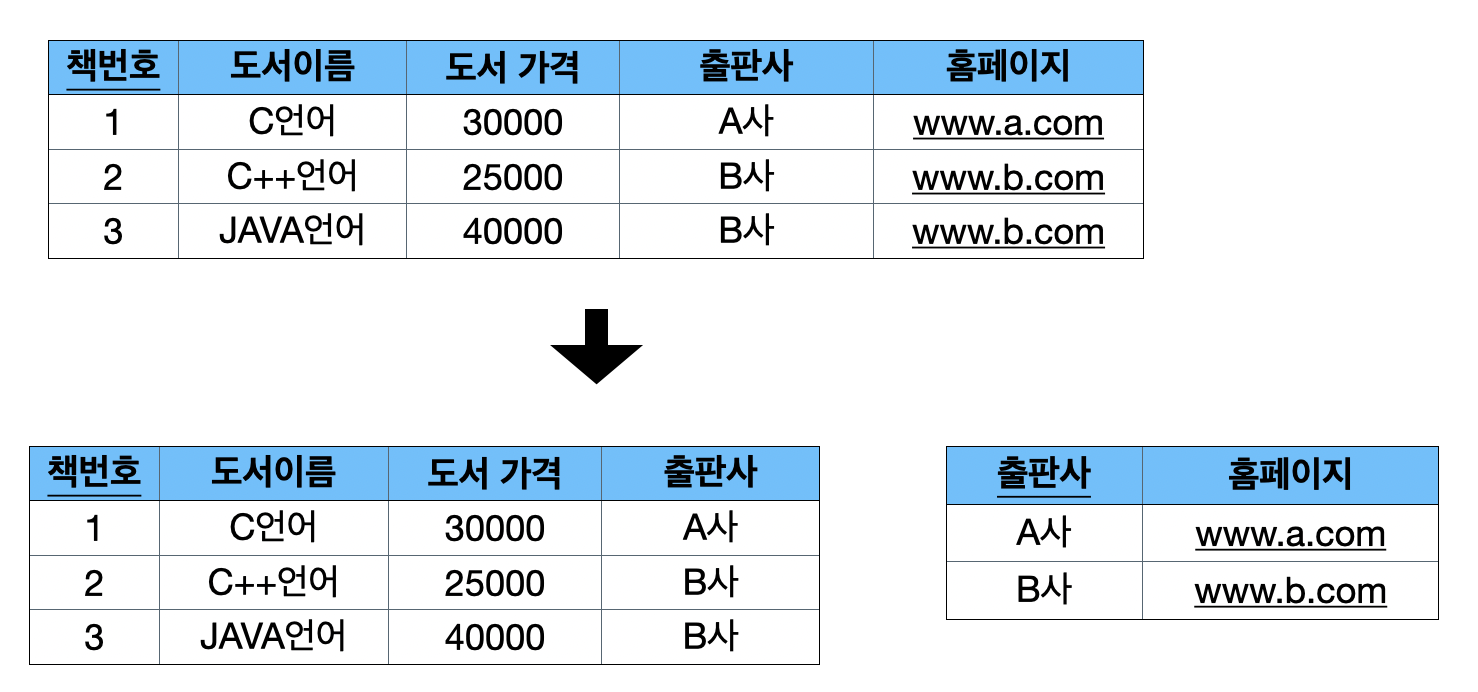
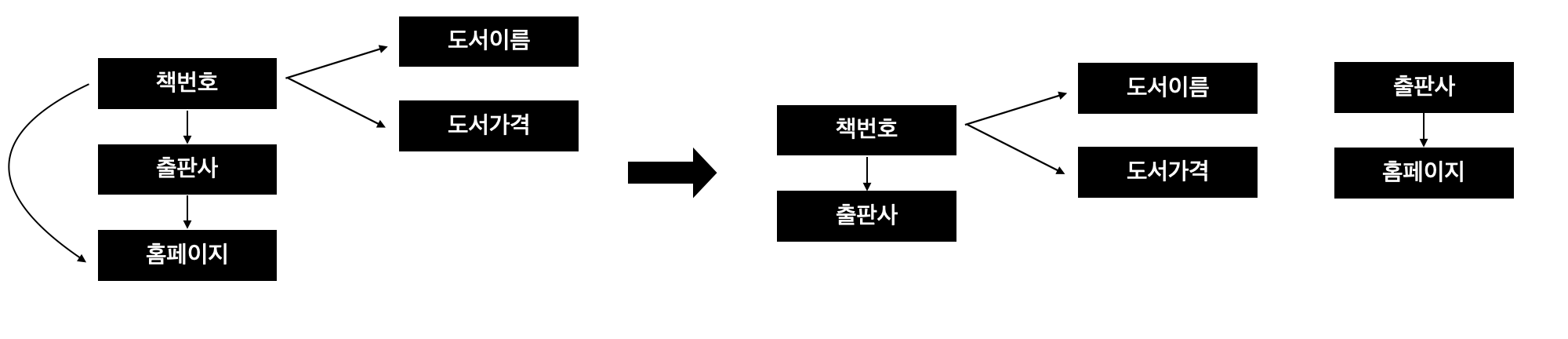
- <책번호>가 <출판사>에 영향을 주고, <출판사>가 <홈페이지>에 영향을 주는 관계인 A -> B이고, B -> C이면서, A -> C관계가 같이 있는 경우를 이행함수 종속이라 함
- <책번호, 출판사, 홈페이지>를 한 테이블에 두는 것은 이행함수 종속성으로 인해 3차 정규화를 만족하지 못함
- <책번호>는 <홈페이지>에 직접 영향을 주는 관계가 아니기 때문에(A -> C관계), <책번호, 출판사> 테이블, <출판사, 홈페이지>테이블로 분리하여 이행 함수 관계를 제거하여 3차 정규화를 만족시킴
[4] 보이스-코드 정규화(BCNF; Boyce and Codd Normal Form)
- 결정자가 함수 종속 제거, 모든 결정자가 후보 키인 정규화 과정
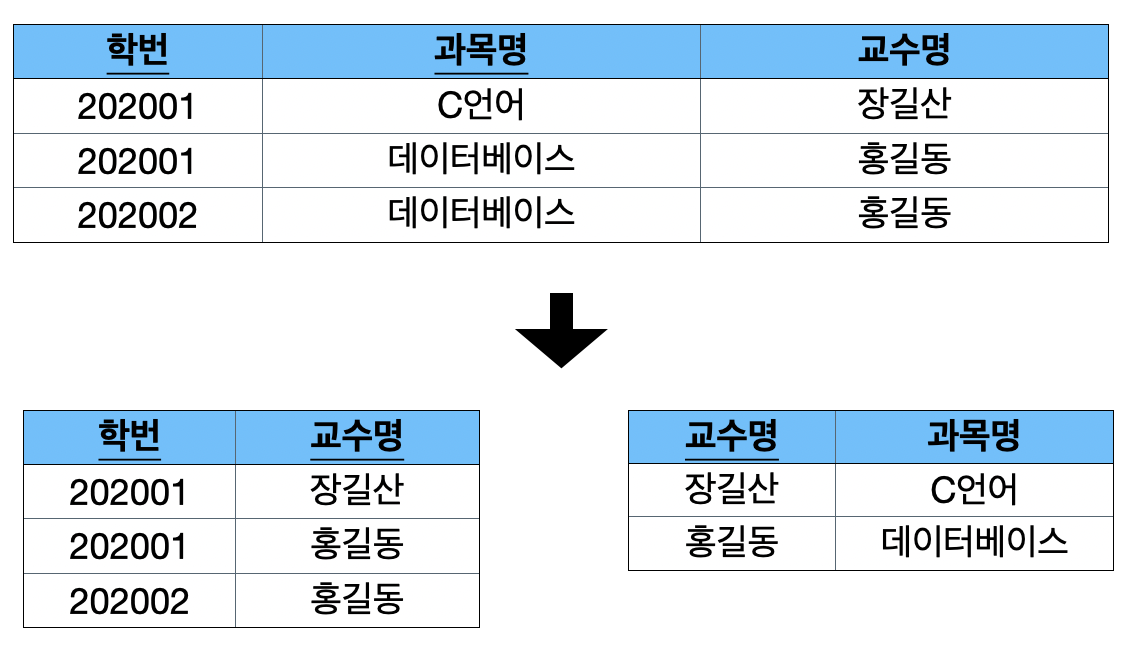
- <학번, 과목명>이 <교수명>에 영향을 주고, <교수명>이 <과목명>에 영향을 주는 관계로서, <교수명>은 <과목명>에 영향을 주지만, 한 테이블에 같이 존재하고 <교수명>은 키가 아닌 상황이므로 결정자인 <교수명>이 후보 키가 아님
- <학번, 과목명, 교수명>을 한 테이블에 두는 것은 <교수명>이 결정자이지만 후보 키가 아니기 때문에 보이스-코드 정규화를 만족하지 못함
- <교수명>은 과목명>에 직접 영향을 주기 때문에 <교수명, 과목명> 테이블로 분리하여 교수명이 후보 키 역할을 하도록 하여 보이스-코드 정규화를 만족시킴

[5] 4차 정규화(4NF; 4 Normal Form)
- 다치(다중 값) 종속 제거, 특정 속성값에 따라 선택적인 속성을 분리하는 정규화
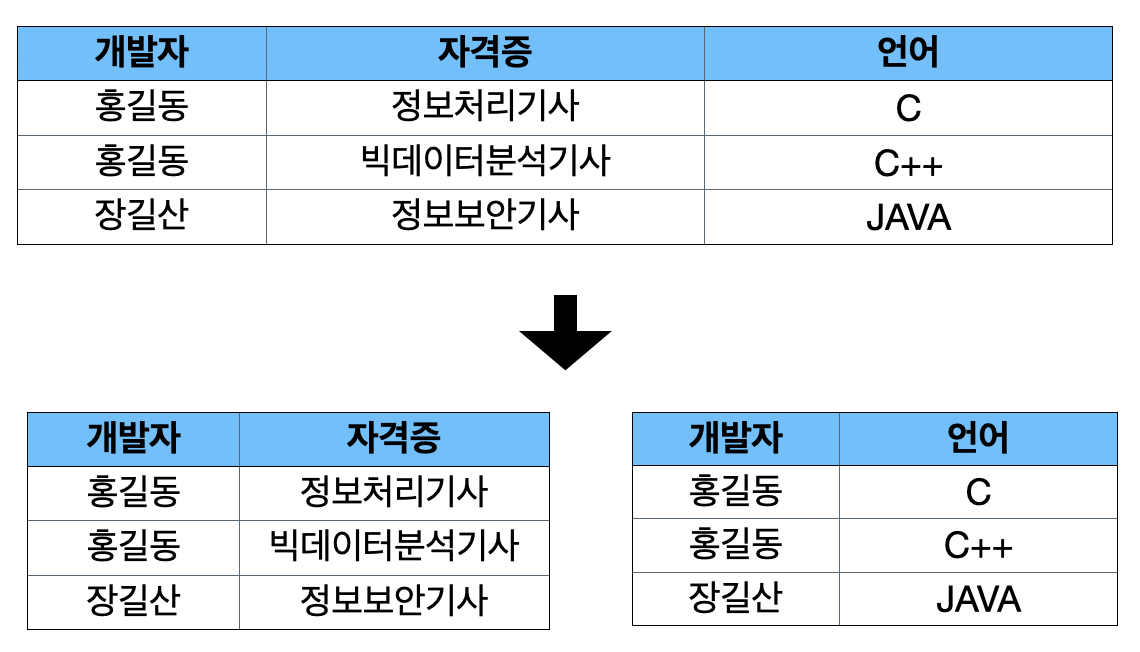
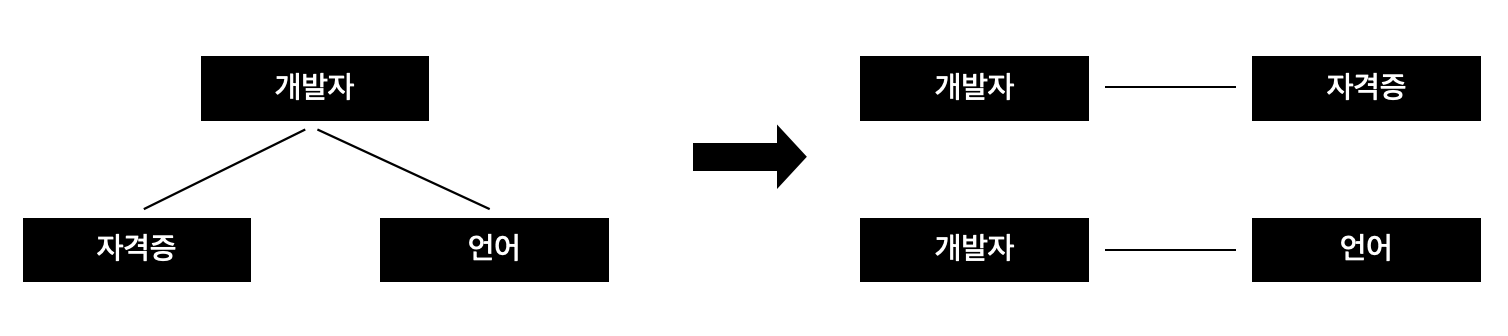
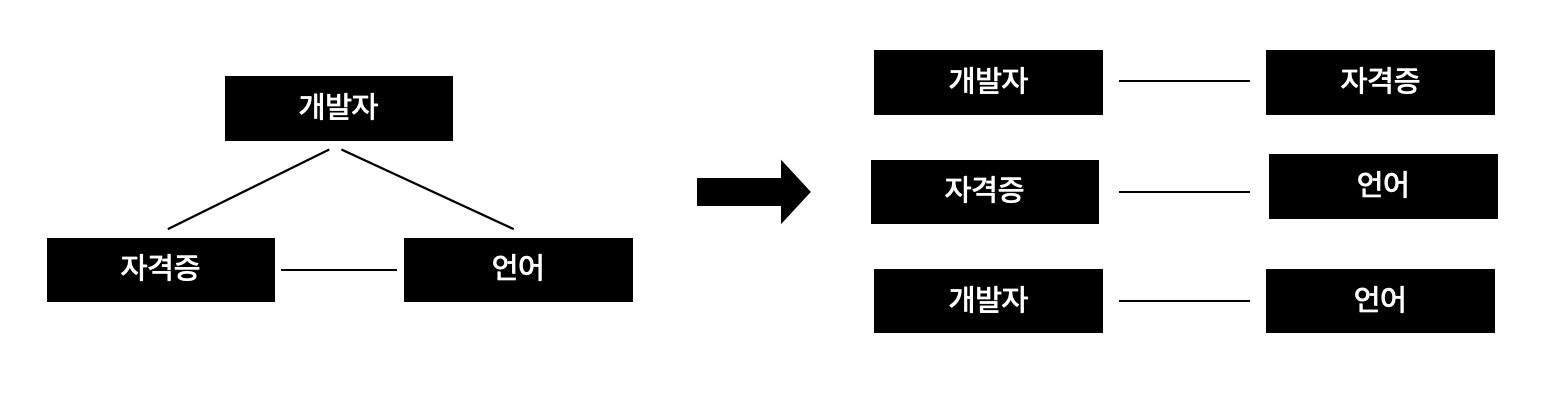
- <개발자>마다 <자격증> 값들이 여러 개 존재하고, 특정 <개발자>마다 <언어> 값들이 여러 개 존재하는 경우 다치 종속 관계라고 함
- <개발자> 별로 여러 <자격증> 값을 가지고 있고, <개발자>별로 여러 <언어>값을 가지고 있으므로 <개발자, 자격증>, <개발자, 언어> 테이블로 분리하여 관리하면 다치 종속 관계를 제거하기 때문에 4차 정규화를 만족 시킴
[6] 5차 정규화(5NF; 5 Normal Form)
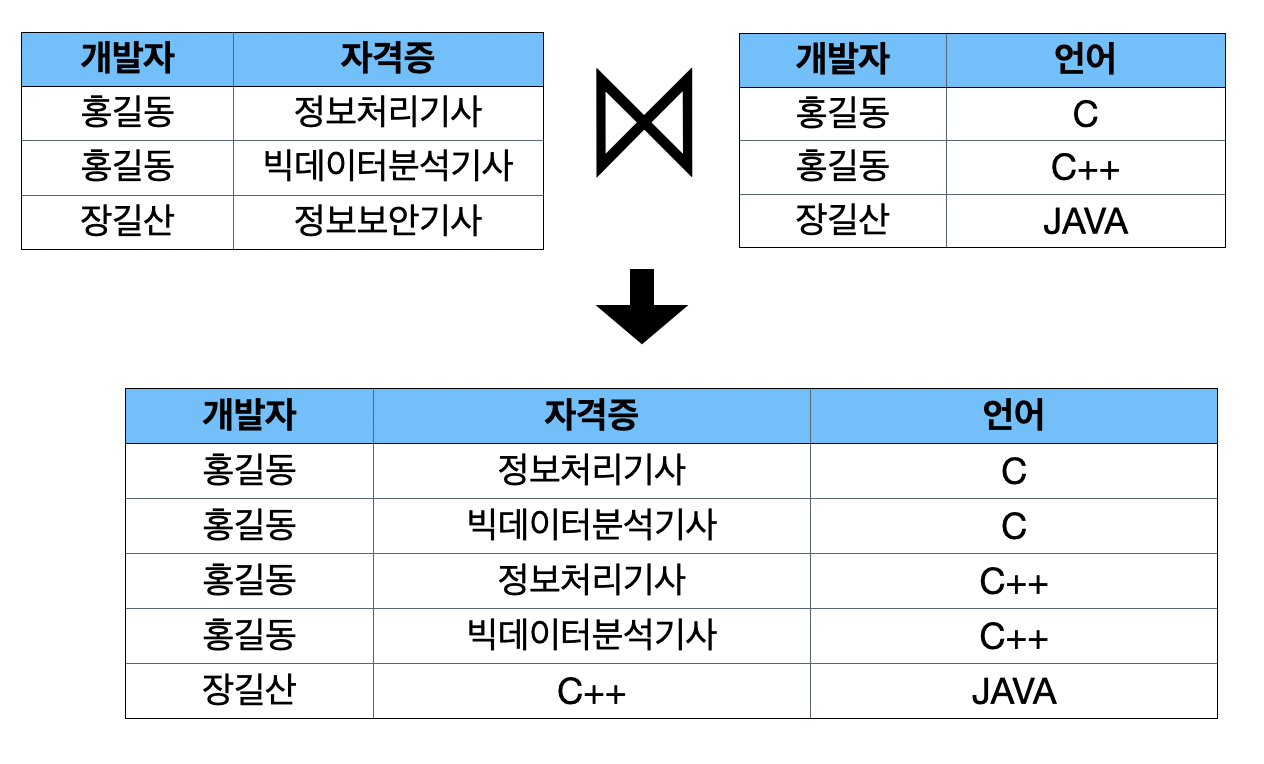
- 조인 종속을 제거하는 과정
- 4차 정규화 테이블에 대해 조인 연산을 수행하면 4차 정규화 수행 전 데이터와 다르게 되는 문제인 조인 종속이 발생함
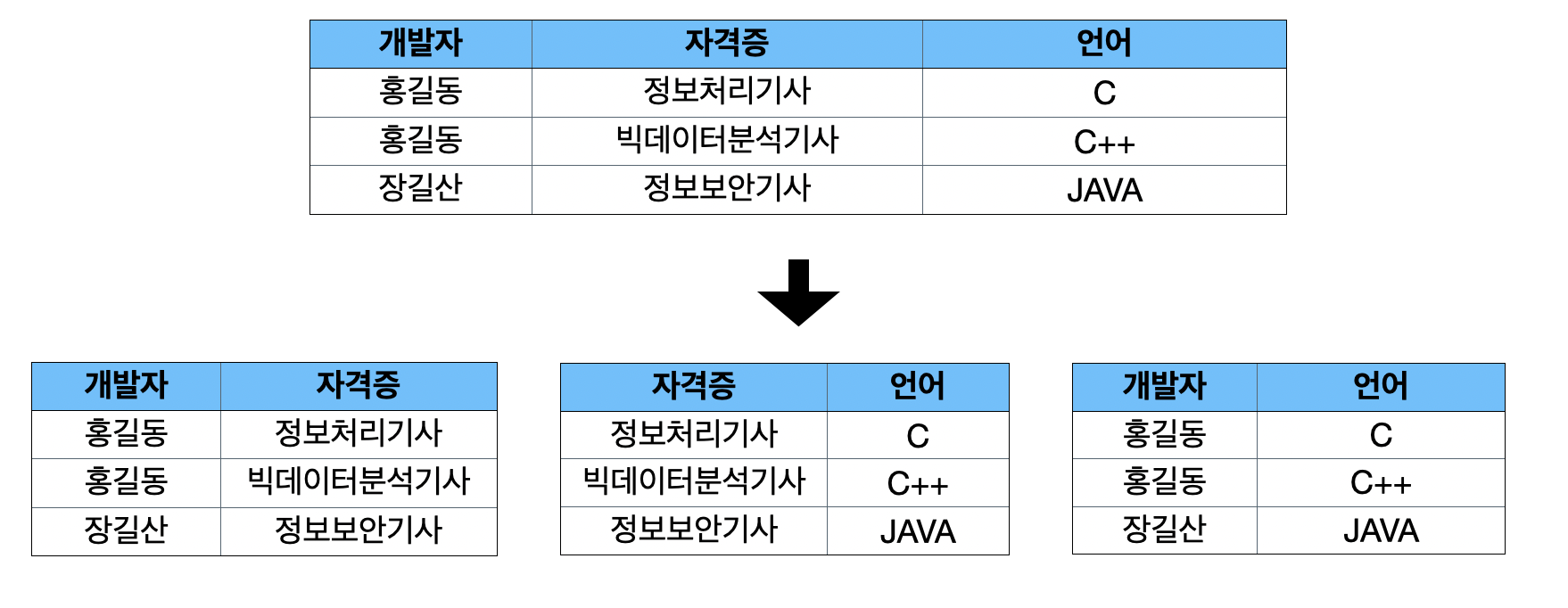
- 조인 종속 관계를 제거하기 위해서는 모든 속성 관계인 <개발자, 자격증>, <개발자, 언어> 뿐 아니라 <자격증, 언어> 관계에 대한 테이블을 만들어 줌으로써 조인했을 때 정확히 원래의 데이터로 복원할 수 있게 함
6) 반 정규화
(1) 반 정규화 (De - Normalization) 개념
- 정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법
- 비정규화, 역정규화라고도 함
** 반정규화 절차
1) 대상 조사 : 범위 처리 빈도수, 대량 범위 처리, 통계성 프로세스, 테이블 조인 수를 고려
2) 다른방법 유도 : 뷰 테이블, 클러스터링, 인덱스의 조정, 어플리케이션 변경 등을 유도
3) 반 정규화 적용
(2) 반 정규화 특징
- 반 정규화를 위해서는 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화에 우선순위를 둘 것인지를 비교하여 조정하는 과정이 중요함
- 장점 : 반 정규화된 데이터 구조는 성능 향상과 관리의 효율성이 증가
- 단점 : 데이터의 일관성 및 정합성 저하, 유지를 위한 비용이 별도로 발생하여 성능에 나쁜 영향을 미칠 수 있음
(3) 반 정규화 기법
| 구분 | 수행 방법 | 설명 | |
| 테이블 | 테이블 병합 | 1:1 관계, 1:M 관계를 통합하여 조인 횟수를 줄여 성능을 향상 | |
| 테이블 분할 | 테이블을 수직 또는 수평으로 분할 | ||
| 중복 테이블 추가 | 대량의 데이터들에 대한 집계함수(GROUP BY, SUM 등)를 사용하여 실시간 통계정보를 계산하는 경우에 효과적인 수행을 위해 별도의 통계 테이블을 두거나 중복 테이블을 추가 | ||
| 집계 테이블 추가 | 집계 데이터를 위한 테이블을 생성하는 방법 | ||
| 진행 테이블 추가 | 이력 관리 등의 목적으로 테이블을 추가하는 방법 | ||
| 특정 부분만을 포함하는 테이블 추가 |
테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성하는 방법 | ||
| 컬럼 | 컬럼 중복화 | 조인 성능 향상을 위한 중복 허용 | |
| 관계 | 중복관계 추가 | 성능 저하를 예방하기 위해 추가적 관계를 맺는 방법 | |
3. 물리 데이터 모델
1) 데이터베이스 무결성
(1) 데이터베이스 무결성(Database Integrity)개념
- 데이터 베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제 값이 일치하는 성질
- 데이터의 무결성을 유지하는 것은 데이터베이스 관리 시스템(DBMS)의 중요한 기능이며, 주로 데이터에 적용되는 연산에 제한을 두어 데이터의 무결성을 유지함
- 무결성은 권한이 있는 사용자로부터 데이터베이스를 보호함
(2) 데이터베이스 무결성 종류
| 종류 | 설명 | 주요 기법 |
| 개체 무결성 (Entity Integrity) |
한 엔터티에서 같은 기본 키(PK)를 가질 수 없거나, 기본 키(PK)의 속성이 NULL을 허용할 수 없는 제약 조건 | 기본 키(Primary Key) 유니크 인덱스(Unique Index) |
| 참조 무결성 (Referential Integrity) |
외래 키가 참조하는 다른 개체의 기본 키에 해당하는 값이 기본 키값이나 NULL이어야 하는 제약 조건 | 외래 키(Foreign Key) |
| 속성 무결성 (Attribute Integrity) |
속성의 값을 기본값, NULL 여부, 도메인(데이터 타입, 길이)이 지정된 규칙을 준수 해야 하는 제약 조건 | 체크(CHECK) NULL / NOT NULL 기본값(DEFAULT) |
| 사용자 정의 무결성 (User-Defined Integrity) |
사용자의 의미적 요구사항을 준수해야 하는 제약 조건 | 트리거(Trigger) 사용자 정의 데이터 타입 (User Defined Data Type) |
| 키 무결성 (Key Integrity) |
한 릴레이션에 같은 키값을 가진 튜플들을 허용할 수 없는 제약 조건 | 유니크(Unique) |
(3) 참조 무결정 제약 조건
- 릴레이션과 릴레이션 사이에 대해 참조의 일관성을 보장하기 위한 조건
- 두 개의 릴레이션이 기본키, 외래키를 통해 참조 관계를 형성할 경우, 참조하는 외래키의 값은 항상 참조되는 릴레이션에 기본키로 존재 해야 함
[1] 제한(Restricted) : 참조무결성 원칙을 위배하는 연산을 거절하는 옵션
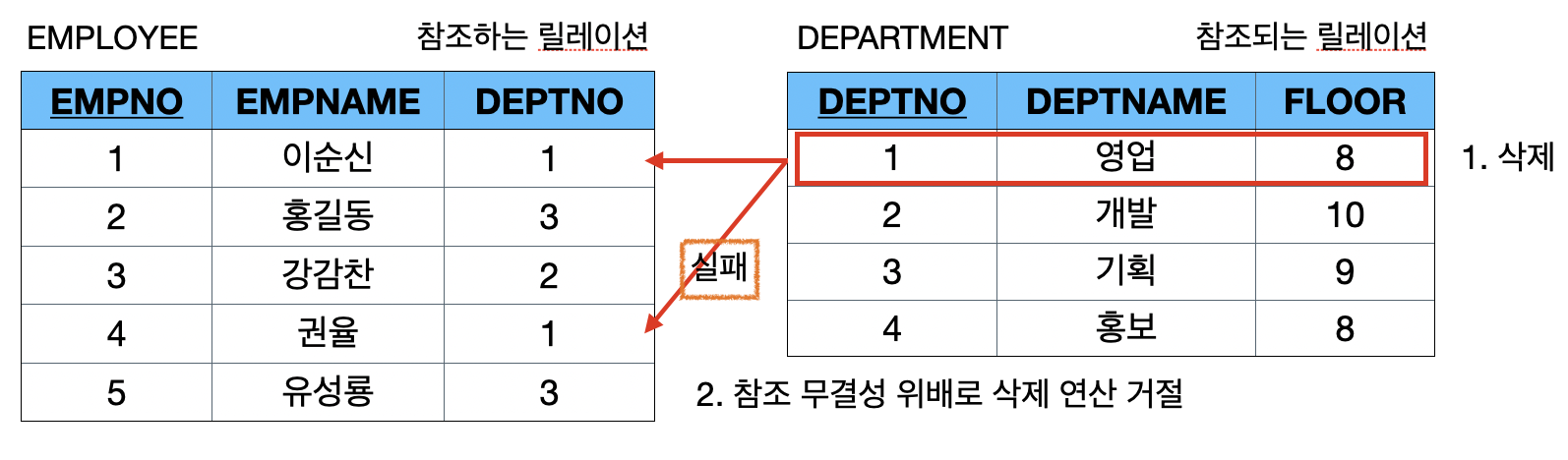
- DEPARTMENT 릴레이션에서 첫 번째 튜플(1. 영업, 8)을 삭제하면 참조무결성 제약 조건을 위배하게 되므로 삭제 연산을 수행하지 않고 거절됨
[2] 연쇄(Cascade) : 참조되는 릴레이션에서 튜플을 삭제하고, 참조되는 릴레이션에서 이 튜플을 참조하는 튜플들도 함께 삭제하는 옵션
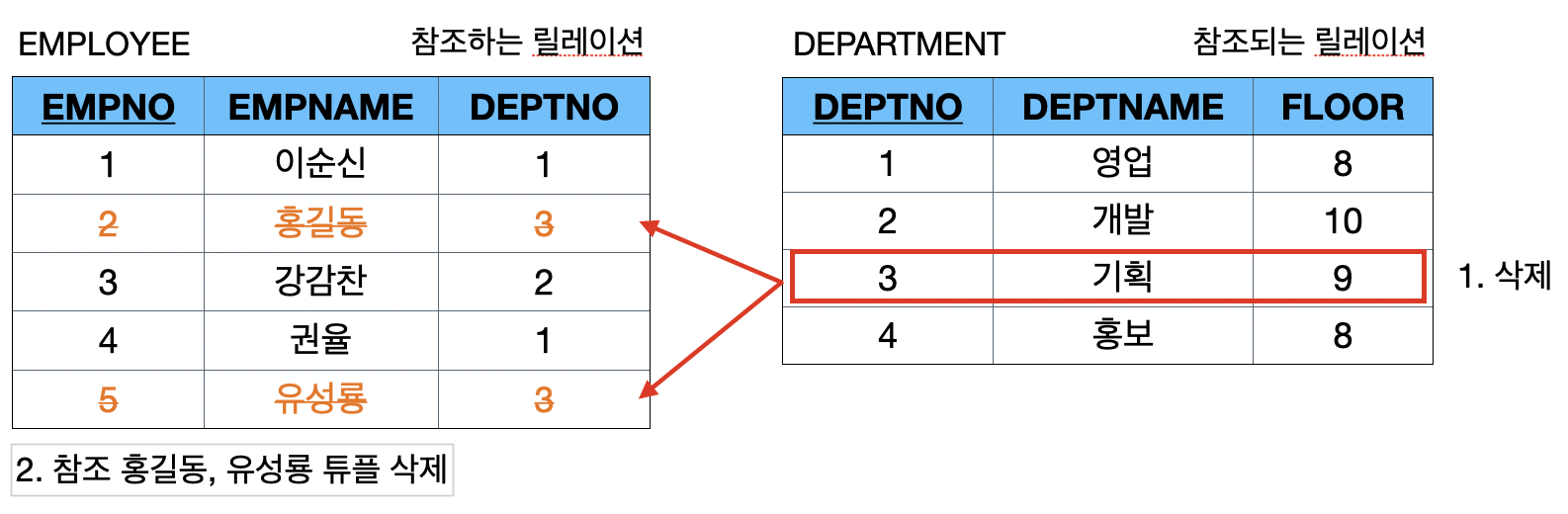
- DEPARTMENT 릴레이션에서 (3. 기획, 9)튜플을 삭제하면 EMPLOYEE 릴레이션에서 부서번호3을 참조하는 홍길동과 유성룡이 함께 삭제됨
[3] 널 값(Nullify)
- 참조되는 릴레이션에서 튜플을 삭제하고, 참조하는 릴레이션에서 해당 튜플을 참조하는 튜플들의 외래 키에 NULL값을 넣는 옵션
- 만일 릴레이션을 정의할 때 참조하는 릴레이션에서 NULL 값이 들어갈 애트리뷰트에 NOT NULL이라고 명시되어 있다면 삭제 연산을 거절함

- DEPARTMENT 릴레이션에서 첫 번째 튜플 (1, 영업, 8)을 삭제하면 EMPLOYEE 릴레이션에서 부서번호 1을 참조하는 이순신과 권율의 부서번호에 NULL 값을 넣음
[4] 참조무결성 제약 조건 SQL문법 (삭제 시)
ALTER TABLE 테이블
ADD FOREIGN KEY (외래키)
REFERENCES 참조테이블(기본키)
ON DELETE [ RESTRICT | CASDADE | SET NULL];2) 키
(1) 키(Key) 개념
- 데이터베이스에서 조건을 만족하는 튜플을 찾거나 순서대로 정렬할 때 다른 튜플들과 구별할 수 있는 기준이 되는 속성
(2) 키 특성
- 유일성(Uniqueness) : 식별자에 의해 엔터티 내에 모든 튜플들을 유일하게 구분하는 특성
- 최소성(Minimality) : 최소한의 속성으로 식별자를 구성하는 특성
(3) 키 종류
- 기본 키(Primary Key) : 테이블의 각 튜플을 고유하게 식별하는 키
- 후보 키(Candidate Key) : 테이블에서 각 튜플을 구별하는데 기준이 되는키, 기본 키와 대체 키를 합친 키
- 대체 키(Alternate Key) : 후보 키 중에서 기본 키로 선택되지 않은 키
- 슈퍼 키(Super Key) : 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족하지 못하는 키
- 외래 키(Foreign Key) : 한 릴레이션의 컬럼이 다른 릴레이션의 기본 키로 이용되는 키, 테이블 간의 참조 데이터 무결성을 위한 제약 조건
3) 인덱스(Index)
- 검색 연산의 최적화를 위해 데이터베이스 내 열에 대한 정보를 구성한 데이터 구조
- 인덱스를 통해 전체 데이터의 검색 없이 필요한 정보에 대해 신속한 조회가 가능함
4) 파티셔닝
(1) 파티셔닝(Partitioning) 개념
- 테이블 또는 인덱스 데이터를 파티션(Partition)단위로 나누어 저장하는 기법
(2) 파티셔닝 유형
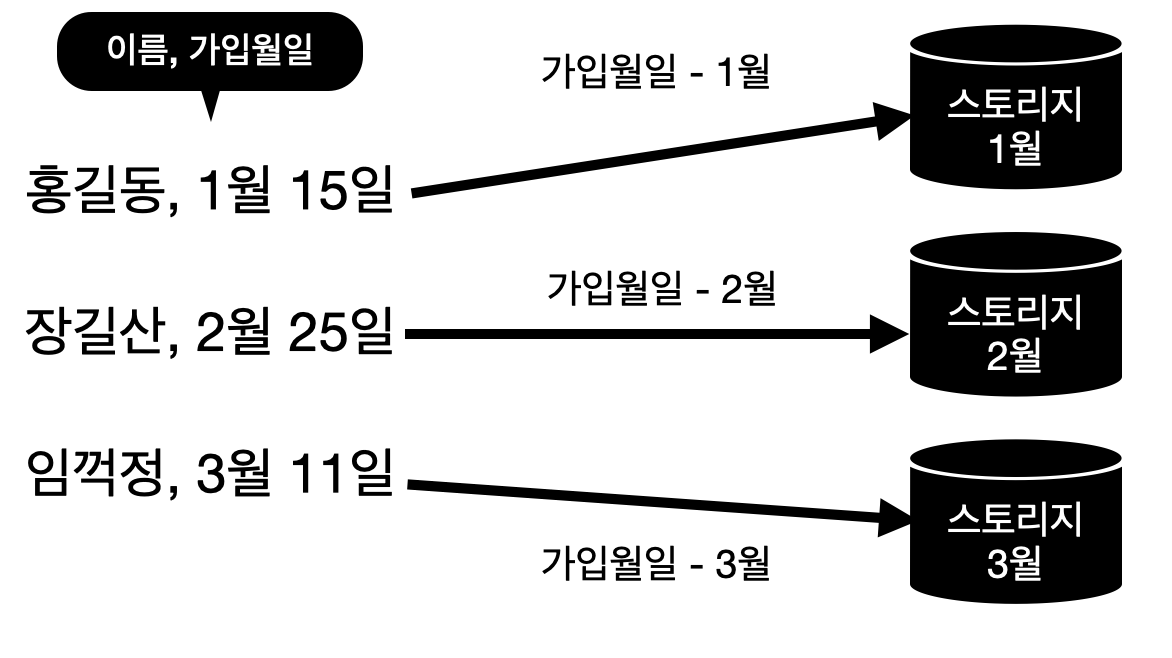
[1] 레인지 파티셔닝(Range Partitioning) = 범위 파티셔닝
- 연속적인 숫자나 날짜를 기준으로 하는 파티셔닝 기법
- 손쉬운 관리 기법을 제공하여 관리 시간의 단축이 가능함
- ex) 우편번호, 일별, 월별, 분기별 등의 데이터에 적합
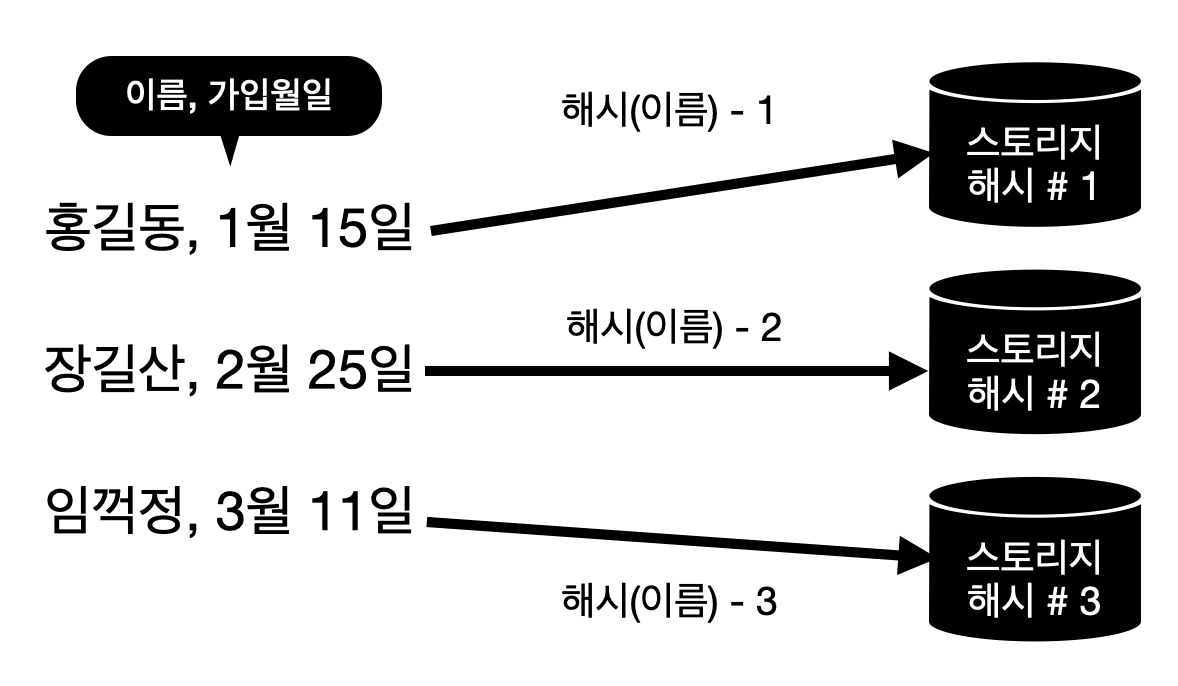
[2] 해시 파티셔닝(Hash Partitioning)
- 파티션 키의 해시 함수 값에 의한 파티셔닝 기법
- 균등한 데이터 분할이 가능하고 질의 성능 향상이 가능함
- ex) 파티션을 위한 범위가 없는 데이터에 적합
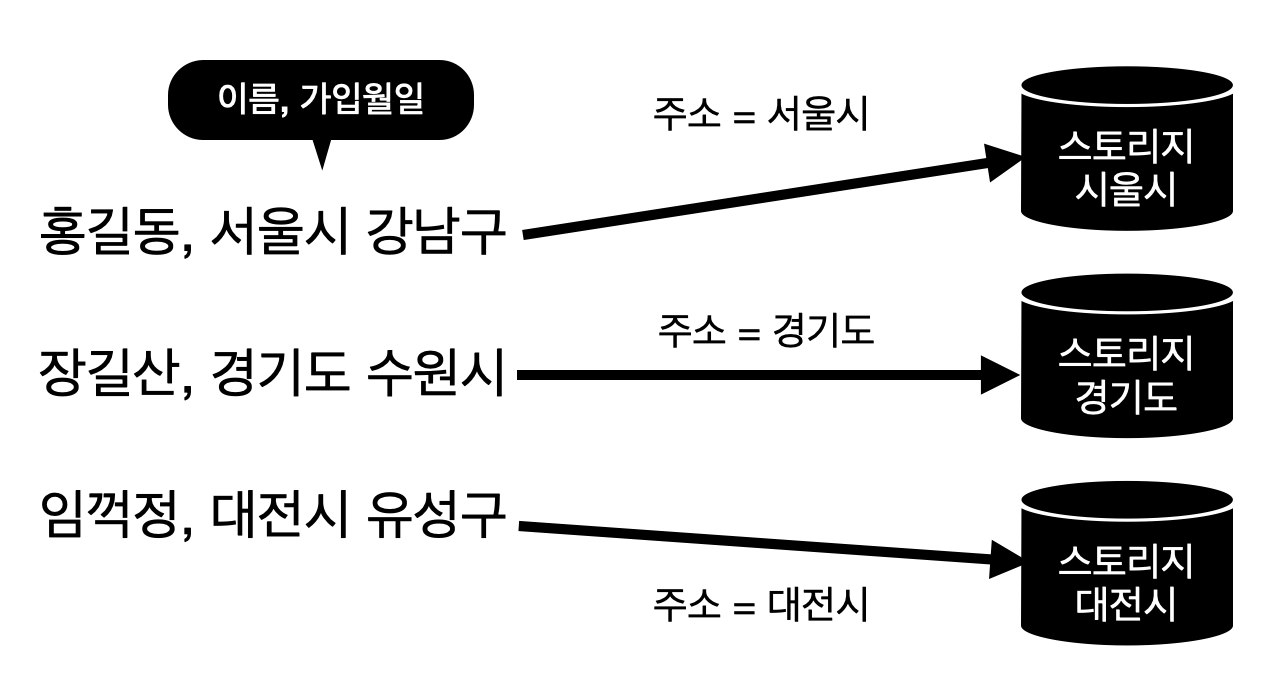
[3] 리스트 파티셔닝(List Partitioning) = 목록 파티셔닝
- 특정 파티션에 저장될 데이터에 대한 명시적 제어가 가능한 파티셔닝 기법
- 분포도가 비슷하고 데이터가 많은 SQL에서 컬럼의 조건이 많이 들어오는 경우 유용함
- ex) [한국, 일본, 중국 -> 아시아][노르웨이, 스웨덴, 핀란드 -> 북유럽]
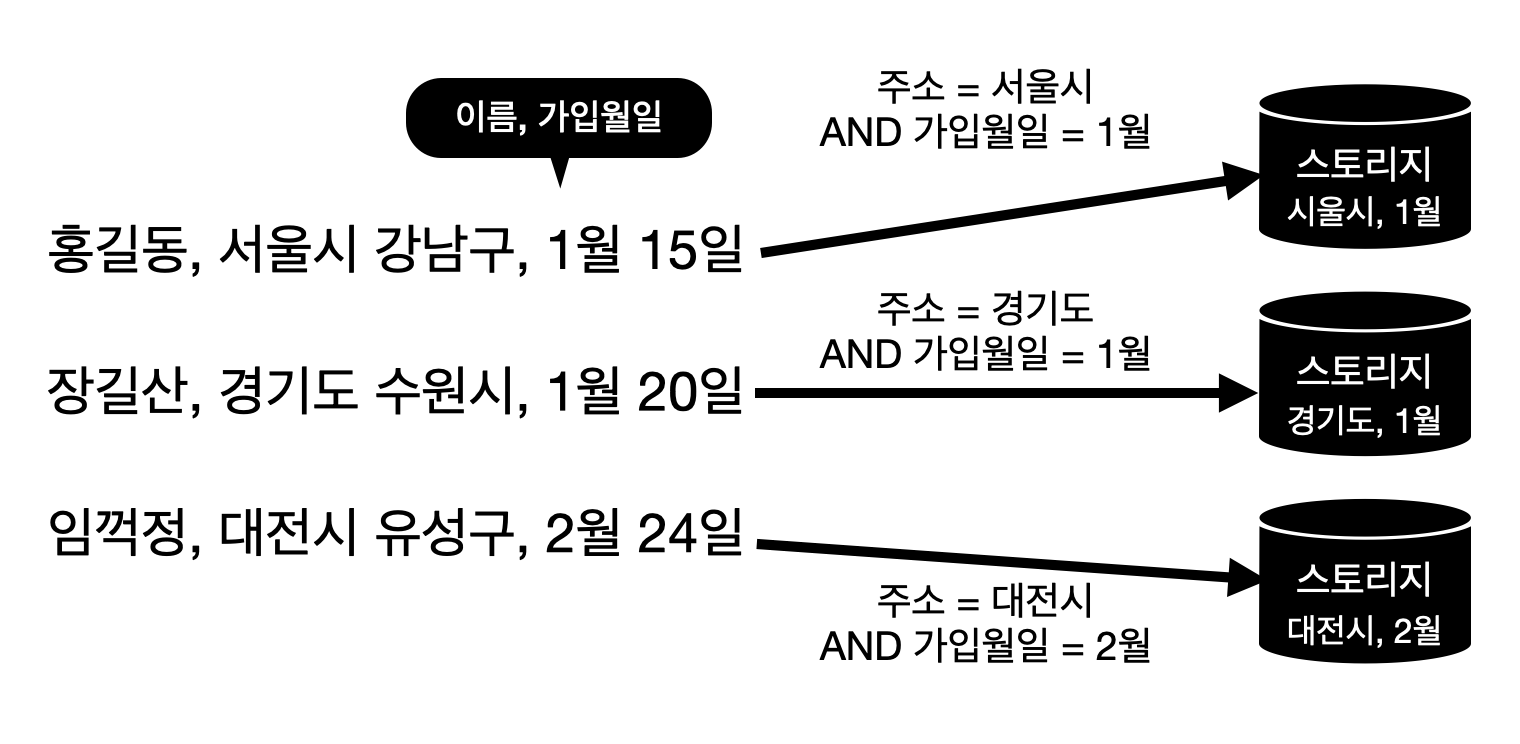
[4] 컴포지트 파티셔닝(Composite Partitioning)
- 레인지 파티셔닝, 해시 파티셔닝, 리스트 파티셔닝 중 2개 이상의 파티셔닝을 결합하는 파티셔닝 기법
- 큰 파티션에 대한 I/O 요청을 여러 파티션으로 분산할 수 있음
- ex) 레인지 파티셔닝할 수 있는 컬럼이나, 파티션이 너무 커서 효과적으로 관리할 수 없을 때 유용
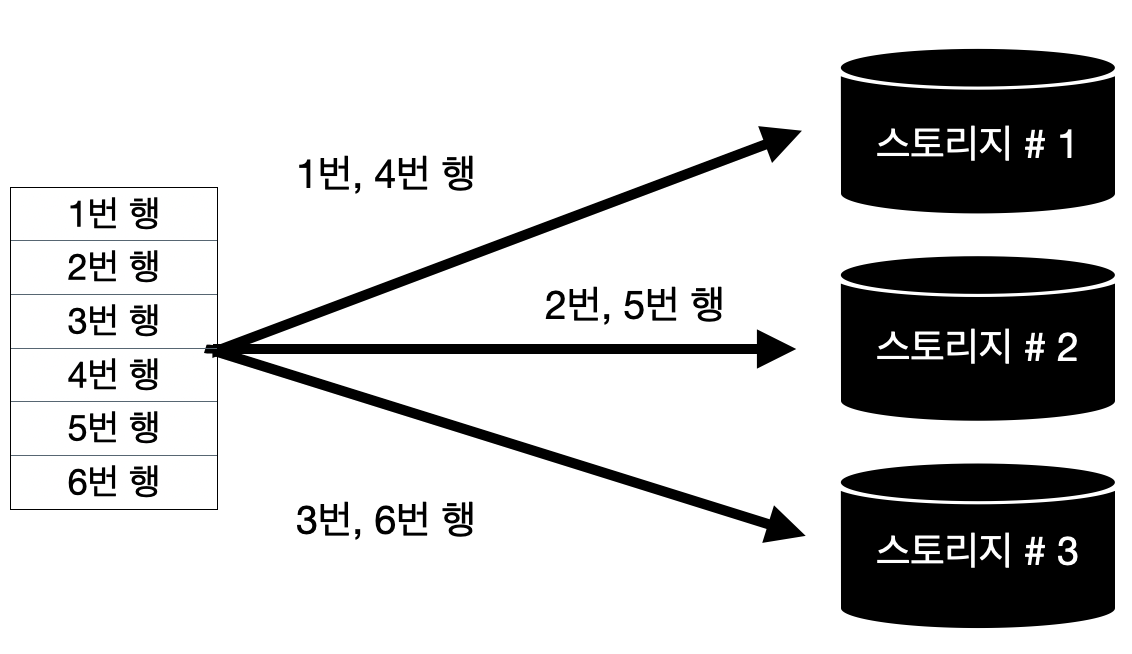
[5] 라운드 로빈(Round-Robin)
- 라운드로빈으로 회전하면서 새로운 행을 파티션에 할당하는 기법
- 파티션에 행의 고른 분포를 원할 때 사용
'2024정보처리기사 준비 정리(필기 - 시나공, 실기 - 수제비) > 실기 3강 - 데이터 입출력 구현' 카테고리의 다른 글
| Chapter 02 - 데이터베이스 기초 활용(기출문제, 예상문제), Chapter 03 - 단원종합문제 (0) | 2024.06.29 |
|---|---|
| Chapter 02 - 데이터베이스 기초 활용 (0) | 2024.06.29 |
| Chapter 01 - 데이터 저장소(기출문제,예상문제) (0) | 2024.06.27 |
| Chapter 01 - 데이터 저장소(1) (0) | 2024.06.27 |



