
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 자바의 정석 기초편 ch14
- 스프링 mvc2 - 로그인 처리
- 자바의 정석 기초편 ch6
- 자바 중급2편 - 컬렉션 프레임워크
- 스프링 mvc2 - 검증
- @Aspect
- 스프링 고급 - 스프링 aop
- 자바 중급1편 - 날짜와 시간
- 2024 정보처리기사 수제비 실기
- 자바로 키오스크 만들기
- 자바 고급2편 - io
- 자바의 정석 기초편 ch7
- 자바 고급2편 - 네트워크 프로그램
- 자바의 정석 기초편 ch2
- 자바의 정석 기초편 ch4
- 자바 기초
- 자바의 정석 기초편 ch13
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch12
- 데이터 접근 기술
- 스프링 mvc2 - 타임리프
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch9
- 2024 정보처리기사 시나공 필기
- 자바의 정석 기초편 ch1
- 스프링 트랜잭션
- 자바로 계산기 만들기
- 스프링 입문(무료)
- 자바의 정석 기초편 ch5
- 람다
- Today
- Total
개발공부기록
컬렉션 프레임워크 - List, 리스트 추상화(인터페이스 도입, 의존관계 주입, 컴파일 타임, 런타임 의존관계), 직접 구현한 리스트의 성능 비교, 자바 리스트, 자바 리스트의 성능 비교 본문
컬렉션 프레임워크 - List, 리스트 추상화(인터페이스 도입, 의존관계 주입, 컴파일 타임, 런타임 의존관계), 직접 구현한 리스트의 성능 비교, 자바 리스트, 자바 리스트의 성능 비교
소소한나구리 2025. 2. 4. 19:32출처 : 인프런 - 김영한의 실전 자바 - 중급2편 (유료) / 김영한님
유료 강의이므로 정리에 초점을 두고 코드는 일부만 인용
1. 리스트 추상화
1) 인터페이스 도입
(1) List 자료 구조
- 순서가 있고 중복을 허용하는 자료 구조를 리스트(List)라고 함
- 이전강의에 만든 MyArrayList와 MyLinkedList는 내부 구현만 다를 뿐 같은 기능을 제공하는 리스트임
- 내부 구현이 다르기 때문에 상황에 따라 성능은 달라질 수 있지만 사용자 입장에서 보면 같은 기능을 제공함
- 이 둘의 공통 기능을 인터페이스로 뽑아서 추상화하면 다형성을 활용한 다양한 이득을 얻을 수 있게 됨
(2) MyList<E>
- MyList<E>라는 제네릭 인터페이스를 생성하고, MyArrayList와 MyLinkedList의 공통인 메서드들을 추상메서드로 선언
package collection.list;
public interface MyList<E> {
int size();
void add(E e);
void add(int index, E e);
E get(int index);
E set(int index, E element);
E remove(int index);
int indexOf(E e);
}
(3) MyArrayList, MyLinkedList
- 기존에 만들어둔 MyArrayListV4와 MyLinkedListV3를 복사하여 MyList 인터페이스를 구현하는 MyArrayList와 MyLinkedList클래스를 생성
- 각 복사된 클래스들은 MyList를 구현했으므로 MyList에 선언된 메서드와 동일한 이름의 메서드에는 @Override 애노테이션을 작성
package collection.list;
public class MyArrayList<E> implements MyList<E> {
// ... 코드 동일 생략, 메서드에 @Override 애노테이션 작성
}
public class MyLinkedList<E> implements MyList<E> {
// ... 코드 동일 생략, 메서드에 @Override 애노테이션 작성
}2) 의존관계 주입
(1) 구체적인 것에 의존
- MyArrayList를 활용하여 많은 데이터를 처리하는 BatchProcessor 클래스를 개발하고 있는데, 막상 프로그램을 개발하고 보니 데이터를 앞에서 추가하는 일이 많은 상황이라고 가정
- 데이터를 앞에서 추가하거나 앞에서 삭제하는 일이 많다면 MyArrayList보다는 MyLinkedList를 사용하는 것이 훨씬 효율적이므로 BatchProcessor의 내부 코드를 MyArrayList에서 MyLinkedList를 사용하도록 변경해야 함
- 아래의 예시처럼 BatchProcessor 클래스에 MyArrayList, MyLinkedList를 사용하고 있는 것을 BatchProcessor가 구체적인 클래스에 의존한다고 표현함
- 이렇게 구체적인 클래스에 의존하면 주석처리하고 새롭게 코드를 입력한 것처럼 MyArrayList를 MyLinkedList로 변경할 때 마다 여기에 의존하는 BatchProcessor의 코드도 함께 수정을 해야 함
public class BatchProcessor {
// private final MyArrayList<Integer> list = new MyArrayList<>();
private final MyLinkedList<Integer> list = new MyLinkedList<>(); //코드 변경
// 로직
}
(2) 추상적인 MyList 인터페이스에 의존
- 자바 기본편에서 배웠듯 구체적인 것에 의존하는 대신 추상적인 인터페이스에 의존하는 방법도 있는데, 인터페이스 타입의 변수를 선언하고 BatchProcessor를 생성하는 시점에 생성자를 통해 원하는 리스트 전략(알고리즘)을 선택해서 전달하면 됨
- 이렇게 다형성과 추상화를 활용하면 MyList를 사용하는 클라이언트 코드인 BatchProcessor를 전혀 변경하지 않고 원하는 리스트 전략을 런타임에 지정할 수 있음
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
// 로직
}
main() {
new BatchProcessor(new MyArrayList()); //MyArrayList를 사용하고 싶을 때
new BatchProcessor(new MyLinkedList()); //MyLinkedList를 사용하고 싶을 때
}
(3) BatchProcessor
- logic(int size) 메서드가 매우 복잡한 비즈니스 로직을 다룬다고 가정하고 주요 동작은 list의 앞 부분에 데이터를 추가하는 기능을 함
- MyList list의 구현체를 선택할지는 실행 시점에 생성자를 통해서 MyList 구현체가 전달되어서 결정됨
- 즉, MyArrayList의 인스턴스가 들어올 수 있고 MyLinkedList의 인스턴스가 들어올 수 있음
- 의존관계 주입: BatchProcessor의 외부에서 의존관계가 결정되어서 BatchProcessor 인스턴스에 들어오는 것처럼 보이는데 의존관계가 외부에서 주입되는 것 같다고 하여 의존관계 주입이라고 함
- 의존관계 주입은 Dependency Injection(DI)라고 부르며 의존성 주입이라고도 부름
package collection.list;
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(0, i); // 앞에 추가
}
long endTime = System.currentTimeMillis();
System.out.println("크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
}
(4) BatchProcessorMain
- BatchProcessor의 생성자에 MyArrayList를 사용할지 MyLinkedList를 사용할지 결정해서 넘기고 processor.logic()을 호출하면 생성자로 넘긴 자료 구조를 사용하여 실행됨
- 50만건을 입력했을 때 BatchProcessor의 logic()메서드에서 데이터를 앞에 추가하기 때문에 MyArrayList를 사용했을 때에는 O(n)의 성능을 보여 엄청 오래걸렸지만, MyLinkedList를 사용하면 O(1)로 엄청 빠르게 성능이 개선 된 것을 확인할 수 있음
- 데이터가 증가하면 증가할 수록 성능의 차이는 더 벌어짐
package collection.list;
public class BatchProcessorMain {
public static void main(String[] args) {
MyArrayList<Integer> list = new MyArrayList<>();
// MyLinkedList<Integer> list = new MyLinkedList<>();
BatchProcessor processor = new BatchProcessor(list);
processor.logic(300_000);
}
}
/*
MyArrayList 실행 결과
크기: 300000, 계산 시간: 63168ms
MyLinkedList 실행 결과
크기: 300000, 계산 시간: 6ms
*/3) 컴파일 타임, 런타임 의존관계
(1) 의존관계
- 의존관계는 크게 컴파일 타임 의존관계와 런타임 의존관계로 나눌 수 있음
- 컴파일 타임(compile time): 코드 컴파일 시점을 뜻함
- 런타임(runtime): 프로그램 실행 시점을 뜻함
(2) 컴파일 타임 의존관계 vs 런타임 의존관계

- 화살표는 해당 클래스에서 화살표 방향의 대상을 의존하고 있다고 관계를 표현한 것임
- 컴파일 타임 의존관계는 자바 컴파일러가 보는 의존관계로 클래스에 모든 의존관계가 다 나타남
- 클래스에 바로 보이는 의존관계이므로 실행하지 않은 소스 코드에 정적으로 나타내는 의존관계임
- BatchProcessor 클래스를 보면 MyList 인터페이스만 사용하며 코드 어디에도 MyArrayList나 MyLinkedList와 같은 정보는 보이지 않으므로 BatchProcessor는 MyList 인터페이스에만 의존한다고함
- 런타임 의존관계는 실제 프로그램이 작동할 때 보이는 의존관계로 생성된 인스턴스와 그것을 참조하는 의존관계임
- 즉, 프로그램이 실행될 때 인스턴스들의 의존관계로 보면되며 런타임 의존관계는 프로그램 실행 중에 계속 변할 수 있음
(3) 정리
- MyList 인터페이스의 도입으로 같은 리스트 자료구조를 그대로 사용하면서 원하는 구현을 변경할 수 있게 되었음
- BatchProcessor 클래스는 구체적인 MyArrayList나 MyLinkedList에 의존하는 것이 아니라 추상적인 MyList에 의존하여 런타임에 MyList의 구현체를 얼마든지 선택할 수 있음
- BatchProcessor에서 사용하는 리스트의 의존관계를 클래스에서 미리 결정하지 않고 생성자를 통해 객체를 생성하는 시점으로 미뤘기 때문에 런타임에 MyList의 구현체를 변경해도 BatchProcessor의 코드는 전혀 변경하지 않아도 됨
- 이렇게 생성자를 통해 런타임 의존관계를 주입하는 것을 생성자 의존관계 주입 또는 생성자 주입이라고 함
- 클라이언트 코드의 변경 없이 구현 알고리즘인 MyList 인터페이스의 구현을 자유롭게 확장이 가능하도록 구현하여 자바 기본편에서 학습한 OCP 원칙을 지킴
- 클라이언트 클래스는 컴파일 타임에 추상적인 것에 의존하고 런타임에 의존관계 주입을 통해 구현체를 주입받아 사용함으로써 이런 이점을 얻을 수 있음
** 참고
- 지금과 같은 코드를 전략 패턴을 사용한 코드임
- 자바 기본편 강의에서 더 자세히 설명함
- https://nagul2.tistory.com/400
2. 직접 구현한 리스트의 성능 비교
(1) MyListPerformanceTest
- 직접 구현한 MyArrayList와 MyLinkedList의 성능을 비교
- 리스트의 앞, 중간, 뒤에 데이터를 추가하거나, 조회하거나, 검색했을 때의 걸리는 시간을 측정한 결과
- 실행 환경은 맥북 M1 Pro임
package collection.list;
public class MyListPerformanceTest {
public static void main(String[] args) {
int size = 50_000;
System.out.println("==MyArrayList 추가==");
addFirst(new MyArrayList<>(), size);
addMid(new MyArrayList<>(), size);
MyArrayList<Integer> arrayList = new MyArrayList<>();
addLast(arrayList, size);
System.out.println("==MyLinkedList 추가");
addFirst(new MyLinkedList<>(), size);
addMid(new MyLinkedList<>(), size);
MyLinkedList<Integer> linkedList = new MyLinkedList<>();
addLast(linkedList, size);
int loop = 10000;
System.out.println("==MyArrayList 조회==");
getIndex(arrayList, loop, 0);
getIndex(arrayList, loop, size / 2);
getIndex(arrayList, loop, size - 1);
System.out.println("==MyLinkedList 조회==");
getIndex(linkedList, loop, 0);
getIndex(linkedList, loop, size / 2);
getIndex(linkedList, loop, size - 1);
System.out.println("==MyArrayList 검색==");
search(arrayList, loop, 0);
search(arrayList, loop, size / 2);
search(arrayList, loop, size - 1);
System.out.println("==MyLinkedList 검색==");
search(linkedList, loop, 0);
search(linkedList, loop, size / 2);
search(linkedList, loop, size - 1);
}
private static void getIndex(MyList<Integer> list, int loop, int index) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < loop; i++) {
list.get(index);
}
long endTime = System.currentTimeMillis();
System.out.println("index: " + index + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void search(MyList<Integer> list, int loop, int findValue) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < loop; i++) {
list.indexOf(findValue);
}
long endTime = System.currentTimeMillis();
System.out.println("findValue: " + findValue + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addFirst(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("앞에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addMid(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i / 2, i);
}
long endTime = System.currentTimeMillis();
System.out.println("평균 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addLast(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("뒤에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
}
/* 실행 결과
==MyArrayList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 1602ms
평균 추가 - 크기: 50000, 계산 시간: 726ms
뒤에 추가 - 크기: 50000, 계산 시간: 2ms
==MyLinkedList 추가
앞에 추가 - 크기: 50000, 계산 시간: 2ms
평균 추가 - 크기: 50000, 계산 시간: 1014ms
뒤에 추가 - 크기: 50000, 계산 시간: 2055ms
==MyArrayList 조회==
index: 0, 반복: 10000, 계산 시간: 0ms
index: 25000, 반복: 10000, 계산 시간: 0ms
index: 49999, 반복: 10000, 계산 시간: 0ms
==MyLinkedList 조회==
index: 0, 반복: 10000, 계산 시간: 0ms
index: 25000, 반복: 10000, 계산 시간: 441ms
index: 49999, 반복: 10000, 계산 시간: 891ms
==MyArrayList 검색==
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 228ms
findValue: 49999, 반복: 10000, 계산 시간: 446ms
==MyLinkedList 검색==
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 484ms
findValue: 49999, 반복: 10000, 계산 시간: 967ms
*/
(2) 추가, 삭제
- 배열 리스트: 인덱스를 통해 추가나 삭제할 위치를 O(1)로 빠르게 찾지만 추가나 삭제 이후에 데이터를 한칸씩 밀어야하는 부분이 O(n)으로 오래걸림
- 연결 리스트: 인덱스를 통해 추가나 삭제할 위치를 O(n)으로 느리게 찾지만 실제 데이터의 추가나 삭제가 간단한 참조 변경으로 빠르게 O(1)로 수행됨
- 앞에 추가 / 삭제: 데이터가 앞에 있으므로 삭제할 위치를 찾는데도 O(1), 노드를 변경하는데도 O(1)이 걸리는 연결리스트가 빠름
- 평균 추가 / 삭제: 둘다 O(n)의 성능을 보이지만 동작의 방식에 차이가 있어서 배열 리스트가 조금 빠름
- 뒤에 추가 / 삭제: 데이터가 뒤에 있으므로 이동할 데이터도 없고 위치를 찾는데 O(1)이 걸리는 배열 리스트가 빠름
(3) 인덱스 조회
- 배열 리스트: 배열에 인덱스를 사용하여 값을 O(1)로 찾을 수 있음
- 연결 리스트: 노드를 인덱스 수 만큼 이동해야 하므로 O(n)이 걸림
(4) 검색
- 둘다 O(n)의 성능을 보이지만 동작 방식의 차이로 배열리스트가 더 빠르게 동작함
- 배열 리스트: 데이터를 찾을 때 까지 배열을 순회
- 연결 리스트: 데이터를 찾을 때 까지 노드를 순회
(5) 시간 복잡도와 실제 성능
- 이론적으로 MyLinkedList의 평균 추가(중간 삽입) 연산은 MyArrayList보다 빠를 수 있으나 실제 성능은 요소의 순차적 접근 속도, 메모리 할당 및 해제 비용, CPU 캐시 활용도 등 다양한 요소에 의해 영향을 받음
- MyArrayList는 요소들이 메모리 상에서 연속적으로 위치하여 CPU 캐시 효율이 좋고 메모리 접근 속도가 빠름
- 반면 MyLinkedList는 각 요소가 별도의 객체로 존재하고 다음 요소의 참조를 저장하기 때문에 여기저기에 흩어져서 존재할 확률이 높아 CPU 캐시 효율이 떨어지고 메모리 접근 속도도 상대적으로 느릴 수 있음
- MyArrayList가 CAPACITY를 넘어가면 배열을 다시 만들고 복사하는 과정이 추가되는 것 때문에 느리다고 생각할 수 있지만 한번에 2배씩 늘어나서 이 과정이 가끔 발생하기 때문에 전체 성능에 큰 영향을 주지 않음
(6) 정리, 배열 리스트 vs 연결 리스트
- 이론적으로 MyLinkedList가 평균(중간 삽입)에 있어서 더 효율적일 수 있지만 현대 컴퓨터 시스템의 메모리 접근 패턴과 CPU 캐시 최적화 등을 고려할 때 MyArrayList가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많음
- 그래서 대부분 배열리스트가 성능상 유리하여 실무에서는 주로 배열 리스트를 기본으로 사용하며 만약 데이터를 앞쪽에서 자주 추가하거나 삭제할 일이 있다면 연결 리스트를 고려하면 됨
3. 자바 리스트
1) 컬렉션 프레임워크 - 리스트
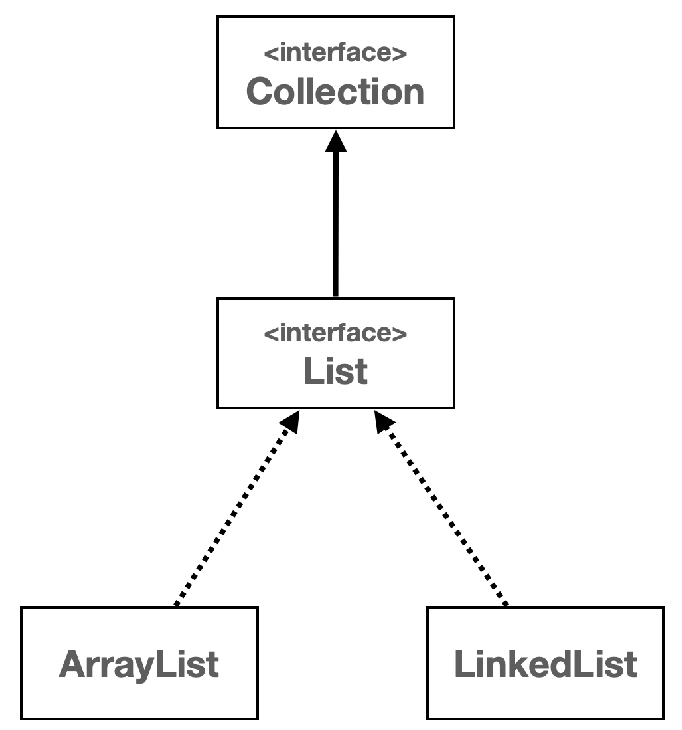
(1) Collection 인터페이스
- java.util 패키지의 컬렉션 프레임워크의 핵심 인터페이스 중 하나임
- 이 인터페이스는 자바에서 다양한 컬렉션(데이터 그룹)을 다루기 위한 메서드를 정의함
- List, Set, Queue와 같은 다양한 하위 인터페이스와 함께 사용되며 이를 통해 데이터를 리스트, 세트, 큐 등의 형태로 관리할 수 있음
(2) List 인터페이스
- java.util 패키지에 있는 컬렉션 프레임워크의 일부
- List는 객체들의 순서가 있는 컬렉션을 나타내며 같은 객체의 중복 저장을 허용함
- 배열과 비슷하지만 크기가 동적으로 변화하는 컬렉션을 다룰 때 유연하게 사용할 수 있음
- ArrayList, LinkedList와 같은 여러 구현 클래스를 가지고 있으며 각 클래스는 List 인터페이스의 메서드를 구현함
(3) List 인터페이스의 주요 메서드
| 메서드 | 설명 |
| add(E e) | 리스트의 끝에 지정된 요소를 추가 |
| add(int index, E element) | 리스트의 지정된 위치에 요소를 삽입 |
| addAll(Collection<? extends E> c) | 지정된 컬렉션의 모든 요소를 리스트의 끝에 추가 |
| addAll(int index, Collection<? extends E> c | 지정된 컬렉션의 모든 요소를 리스트의 지정된 위치에 추가 |
| get(int index) | 리스트에서 지정된 위치의 요소를 반환 |
| set(int index, E element) | 지정한 위치의 요소를 변경하고 이전 요소를 반환 |
| remove(int index) | 리스트에서 지정한 위치의 요소를 제거하고 그 요소를 반환 |
| remove(Object o) | 리스트에서 지정된 첫 번째 요소를 제거 |
| clear() | 리스트에서 모든 요소를 제거 |
| indexOf(Object o) | 리스트에서 지정된 요소의 첫 번째 인덱스를 반환 |
| lastIndexOf(Object o) | 리스트에서 지정된 요소의 마지막 인덱스를 반환 |
| contains(Object o) | 리스트가 지정된 요소를 포함하고 있는지 여부를 반환 |
| sort(Comparator<? super E> c | 리스트의 요소를 지정된 비교자에 따라 정렬 |
| subList(int fromIndex, int toIndex) | 리스트의 일부분의 뷰를 반환 |
| size() | 리스트의 요소 수를 반환 |
| isEmpty() | 리스트가 비어있는지 여부를 반환 |
| iterator() | 리스트의 요소에 대한 반복자를 반환 |
| toArray() | 리스트의 모든 요소를 배열로 반환 |
| toArray(T[] a) | 리스트의 모든 요소를 지정된 배열로 반환 |
2) 자바 ArrayList
(1) 자바 ArrayList의 특징
- 자바가 제공하는 ArrayList는 직접 만든 MyArrayList와 거의 비슷함
- 배열을 사용해서 데이터를 관리함
- 기본 CAPACITY는 10이며 CAPACITY를 넘어가면 50%증가함(자바 버전에 따라 최적화가 달라질 수 있음) - 메모리 고속 복사 연산을 사용함
- ArrayList의 중간 위치에 데이터를 추가하면 추가할 위치 이후의 모든 요소를 한 칸씩 뒤로 이동시켜야 하는데 자바가 제공하는 ArrayList는 이 부분을 최적화함
- System.arraycopy()를 활용하여 시스템 레벨에서 최적화된 메모리 고속 복사 연산을 사용하므로 비교적 빠르게 수행됨
(2) 메모리 고속 복사 연산 사용
- 기존에 직접 만든 MyArrayList는 루프를 돌면서 하나씩 이동하도록 설계하여 매우 느리게 동작함
- 메모리 고속 복사는 그림 처럼 시스템 레벨에서 이동할 배열을 시스템 레벨에서 한번에 아주 빠르게 복사함
- 이 부분은 OS, 하드웨어에 따라 성능이 다르기 때문에 정확한 측정은 어렵지만 한 칸씩 이동하는 방식과 비교하면 수 배 이상의 빠른 성능을 제공함
- 그러나 데이터가 엄청 많으면 아무리 이렇게 최적화를 하여도 근본적인 동작방식때문에 느릴 수 밖에 없음

3) 자바 LinkedList
(1) 자바의 LinkedList의 특징
- 마찬가지로 직접만든 MyLinkedList와 특징과 거의 같지만 구조 차이가 있음
- 이중 연결 리스트 구조로 첫 번째 노드와 마지막 노드 둘다 참조함
- 우리가 직접 만든 MyLinkedList의 노드는 다음 노드로만 이동할 수 있는 단일 연결 구조이기 때문에 이전 노드로 이동할 수 없다는 단점이 있지만 이중 연결 리스트는 양쪽으로 이동할 수 있으므로 성능이 개선됨
(2) 이중 연결 리스트

- 자바가 제공하는 LinkedList는 이중 연결 구조이기 때문에 다음 노드 뿐만 아니라 이전 노드로도 이동할 수 있으며 마지막 노드에 대한 참조를 제공함
- 마지막 노드의 참조를 가지고 있어 데이터를 마지막에 추가하는 경우에도 O(1)의 성능을 제공함
- node.next를 호출하면 다음 노드로, node.prev를 호출하면 이전 노드로 이동함
- 이전 노드로 이동할 수 있기 때문에 마지막 노드로부터 역방향으로 조회할 수 있어 인덱스 조회 성능을 최적화할 수 있음
- 예를 들어 인덱스로 조회하는 경우 인덱스가 사이즈의 절반 이하라면 처음부터 찾아서올라가고 인덱스가 사이즈의 절반을 넘으면 마지막 노드 부터 역방향으로 조회해서 성능을 최적화하도록 구현되어있음
// 자바의 LinkedList 클래스
class Node {
E item;
Node next; // 다음 노드 참조
Node prev; // 이전 노드 참조
}
class LinkedList {
Node first;// 첫 번째 노드 참조
Node last; // 마지막 노드 참조
int size;
}4. 자바 리스트의 성능 비교
(1) JavaListPerformanceTest
- 기존에 만들었던 MyListPerformanceTest 코드를 복사하여 자바의 리스트를 사용하도록 코드를 수정하여 테스트를 진행
- 코드는 똑같기 때문에 생략하고 출력결과만 작성
/* 실행 결과
==ArrayList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 114ms
평균 추가 - 크기: 50000, 계산 시간: 55ms
뒤에 추가 - 크기: 50000, 계산 시간: 2ms
==LinkedList 추가
앞에 추가 - 크기: 50000, 계산 시간: 3ms
평균 추가 - 크기: 50000, 계산 시간: 1063ms
뒤에 추가 - 크기: 50000, 계산 시간: 5ms
==ArrayList 조회==
index: 0, 반복: 10000, 계산 시간: 1ms
index: 25000, 반복: 10000, 계산 시간: 1ms
index: 49999, 반복: 10000, 계산 시간: 0ms
==LinkedList 조회==
index: 0, 반복: 10000, 계산 시간: 0ms
index: 25000, 반복: 10000, 계산 시간: 411ms
index: 49999, 반복: 10000, 계산 시간: 0ms
==ArrayList 검색==
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 134ms
findValue: 49999, 반복: 10000, 계산 시간: 258ms
==LinkedList 검색==
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 533ms
findValue: 49999, 반복: 10000, 계산 시간: 986ms
*/
(2) 자바가 제공하는 배열 리스트와 연결 리스트 vs 직접 만든 배열 리스트와 연결 리스트 - 성능 비교 표
- 자바가 제공하는 ArrayList가 고속 복사를 사용하는 덕분에 대부분의 기능에서 성능이 빠른 것을 확인할 수 있음
- 그러나 데이터가 많아지면 최적화를 한다고하더라도 동작방식 특성상 느려질수밖에 없음
- 자바가 제공하는 LinkedList는 이중 연결 리스트로 뒤에 추가하는 것이 매우 빠른 것을 볼 수 있으며 표에는 평균을 나타내어서 MyLinkedList와 차이가 없게 나지만, 평균보다 앞쪽에서 찾거나 뒤쪽에서 찾게되면 성능이 더 빨라짐
| 기능 | MyArrayList | ArrayList(자바) | MyLinkedList | LinkedList(자바) |
| 앞에 추가 / 삭제 | O(n) - 1602ms | O(n) - 114ms | O(1) - 2ms | O(1) - 3ms |
| 평균 추가 / 삭제 | O(n) - 726ms | O(n) - 55ms | O(n) - 1014ms | O(n) - 1063ms |
| 뒤에 추가 / 삭제 | O(1) - 2ms | O(1) - 2ms | O(n) - 2055ms | O(n) - 5ms |
| 인덱스 조회 | O(1) - 0ms | O(1) - 0ms | O(n) - 평균 441ms | O(n) - 평균 411ms |
| 검색 | O(n) - 평균 228ms | O(n) - 평균 134ms | O(n) - 평균 484ms | O(n) - 평균 533 |
(3) 정리
- 자바가 제공하는 LinkedList와 ArrayList도 우리가 직접 만든것과 특징이 거의 비슷하기 때문에 ArrayList가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많아 실무에서는 주로 배열 리스트를 기본으로 사용함
- 앞쪽에서 데이터를 자주 추가하거나 삭제할 일이 있을때에만 연결 리스트를 고려하면 됨
- 다만 데이터가 적을 때는 의미가 없으므로 데이터가 몇만 몇십만건 이상으로 아주 많을때에 이런 방향성을 고려하면 됨
- 일반적으로 책이나 강의에서 중간 삽입이 LinkedList가 더 효율적이라고 알려주는 경우가 많지만 실제로는 그렇지 않은것을 테스트 결과로 알 수 있음
5. 문제와 풀이
1) 배열을 리스트로 변경
(1) 문제 설명
- 배열을 사용하는 ArrayEx1을 배열 대신 리스트를 사용하도록 변경
- 다음 코드와 실행 결과를 참고하여 리스트를 사용하는 ListEx1 클래스를 생성
package collection.list.test.ex1;
public class ArrayEx1 {
public static void main(String[] args) {
int[] students = {90, 80, 70, 60, 50};
int total = 0;
for (int i = 0; i < students.length; i++) {
total += students[i];
}
double average = (double) total / students.length;
System.out.println("점수 총합: " + total);
System.out.println("점수 평균: " + average);
}
}
실행 결과
점수 총합: 350
점수 평균: 70.0
(2) 정답
package collection.list.test.ex1;
public class ListEx1 {
public static void main(String[] args) {
List<Integer> students = new ArrayList<>();
students.add(90);
students.add(80);
students.add(70);
students.add(60);
students.add(50);
int total = 0;
for (Integer student : students) {
total += student;
}
double average = (double) total / students.size();
System.out.println("점수 총합: " + total);
System.out.println("점수 평균: " + average);
}
}2) 리스트의 입력과 출력
(1) 문제 설명
- 사용자에게 n개의 정수를 입력받아서 List에 저장하고 입력 순서대로 출력
- 0을 입력하면 입력을 종료하고 결과를 출력
- 출력시 출력 포멧은 1, 2, 3, 4, 5와 같이 , 쉼표를 사용해서 구분하고 마지막에는 쉼표를 넣지 않아야 함
- ListEx2클래스에 구현
실행 결과
n개의 정수를 입력하세요 (종료 0)
1
2
3
4
5
0
출력
1, 2, 3, 4, 5
(2) 정답
강의 코드에서는 입력값에 정수만 받도록 검증하는 try-catch하는 코드가 없이 작성되어있음
package collection.list.test.ex1;
public class ListEx2 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
Scanner scanner = new Scanner(System.in);
System.out.println("n개의 정수를 입력하세요 (종료 0)");
int input;
while (true) {
try {
input = scanner.nextInt();
} catch (InputMismatchException e) {
System.out.println("정수만 입력 가능합니다");
scanner.next(); // 버퍼 비우기
continue;
}
if (input == 0) {
break;
}
numbers.add(input);
}
printList(numbers);
}
private static void printList(List<Integer> list) {
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i));
if (i < list.size() - 1) {
System.out.print(", ");
}
}
}
}
3) 합계와 평균
(1) 문제 설명
- 사용자에게 n개의 정수를 입력받아서 List에 보관하고 보관한 정수의 합계와 평균을 계산하는 프로그램을 ListEx3에 작성
실행 결과
n개의 정수를 입력하세요 (종료 0)
1
2
3
4
5
0
입력한 정수의 합계: 15
입력한 정수의 평균: 3.0
(2) 정답
package collection.list.test.ex1;
public class ListEx3 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
Scanner scanner = new Scanner(System.in);
System.out.println("n개의 정수를 입력하세요 (종료 0)");
int input;
while (true) {
try {
input = scanner.nextInt();
} catch (InputMismatchException e) {
System.out.println("정수만 입력 가능합니다");
scanner.next(); // 버퍼 비우기
continue;
}
if (input == 0) {
break;
}
numbers.add(input);
}
printResult(numbers);
}
private static void printResult(List<Integer> list) {
int sum = 0;
for (Integer number : list) {
sum += number;
}
double avg = (double) sum / list.size();
System.out.println("입력한 정수의 합계: " + sum);
System.out.println("입력한 정수의 평균: " + avg);
}
}4) 리스트를 사용한 쇼핑 카트
(1) 문제 설명
- ShoppingCartMain코드가 작동하도록 ShoppingCart 클래스를 완성
- ShoppingCart는 내부에 리스트를 사용해야함
Item 클래스
package collection.list.test.ex2;
public class Item {
private String name;
private int price;
private int quantity;
public Item(String name, int price, int quantity) {
this.name = name;
this.price = price;
this.quantity = quantity;
}
public String getName() {
return name;
}
public int getTotalPrice() {
return price * quantity;
}
}
ShoppingCartMain
package collection.list.test.ex2;
public class ShoppingCartMain {
public static void main(String[] args) {
ShoppingCart cart = new ShoppingCart();
Item item1 = new Item("마늘", 2000, 2);
Item item2 = new Item("상추", 3000, 4);
cart.addItem(item1);
cart.addItem(item2);
cart.displayItems();
}
}
실행 결과
장바구니 상품 출력
상품명:마늘, 합계:4000
상품명:상추, 합계:12000
전체 가격 합:16000
(2) 정답
package collection.list.test.ex2;
public class ShoppingCart {
List<Item> items = new ArrayList<>();
public void addItem(Item item) {
items.add(item);
}
public void displayItems() {
System.out.println("장바구니 상품 출력");
int totalPrice = 0;
for (Item item : items) {
System.out.println("상품명:" + item.getName() + ", 합계:" + item.getTotalPrice());
totalPrice += item.getTotalPrice();
}
System.out.println("전체 가격 합:" + totalPrice);
}
}
유지보수성 증가
- displayItems() 메서드를 보면 전체 가격을 계산하는 로직과 단순히 item에서 값을 뽑아서 출력하는 코드가 섞여 있는데, 유지보수성을 좋게 하려면 아래처럼 분리하는 방법도 있음
- 물론 반복문을 한번 더 돌기 때문에 성능저하가 있을 수 있지만 요즘은 컴퓨터가 너무 좋아져서 이정도의 추가코드는 성능저하가 발생하지 않으며 오히려 메서드로 분리했기 때문에 유지보수성이 더 좋아지는 효과가 있음
public void displayItems() {
System.out.println("장바구니 상품 출력");
for (Item item : items) {
System.out.println("상품명:" + item.getName() + ", 합계:" + item.getTotalPrice());
}
System.out.println("전체 가격 합:" + calculateTotalPrice());
}
private int calculateTotalPrice() {
int totalPrice = 0;
for (Item item : items) {
totalPrice += item.getTotalPrice();
}
return totalPrice;
}



