
- 분류 전체보기 (373)

- 프로젝트 회고 (0)
- 개발 공부 복습 (0)
- 인프런 - 스프링 완전정복 코스 로드맵 (98)
- 인프런 - 스프링부트와 JPA실무 로드맵 (30)
- 인프런 - 실전 자바 로드맵 (40)
- 책 공부 (3)
- 유튜브 공부 (75)
- 2024정보처리기사 준비 정리(필기 - 시나공, 실기 - 수제비) (127)
- 필기 1강 - 소프트웨어 설계 (17)
- 필기 2강 - 소프트웨어 개발 (16)
- 필기 3강 - 데이터베이스 구축 (13)
- 필기 4강 - 프로그래밍 언어 활용 (8)
- 필기 5강 - 정보시스템 구축 관리 (13)
- 실기 6강 - 프로그래밍 언어 활용 (22)
- 실기 1강 - 요구사항 확인(일부분), 2강 - 화면설계(일부분) (3)
- 실기 3강 - 데이터 입출력 구현 (5)
- 실기 7강 - SQL 응용 (7)
- 실기 9강 - 소프트웨어 개발 보안 구축 (8)
- 실기 10강 - 애플리케이션 테스트 관리 (5)
- 실기 11강 - 응용 SW 기초 기술 활용 (10)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 코드로 시작하는 자바 첫걸음
- 스프링 db1 - 스프링과 문제 해결
- 스프링 입문(무료)
- 자바의 정석 기초편 ch12
- 스프링 db2 - 데이터 접근 기술
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch13
- 자바 기본편 - 다형성
- 2024 정보처리기사 수제비 실기
- 자바 중급1편 - 날짜와 시간
- @Aspect
- jpa 활용2 - api 개발 고급
- 2024 정보처리기사 시나공 필기
- 자바의 정석 기초편 ch1
- 스프링 mvc2 - 타임리프
- 게시글 목록 api
- 자바의 정석 기초편 ch7
- 자바 중급2편 - 컬렉션 프레임워크
- 스프링 고급 - 스프링 aop
- 스프링 mvc2 - 로그인 처리
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch9
- 스프링 mvc1 - 서블릿
- 자바의 정석 기초편 ch2
- 스프링 mvc2 - 검증
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch14
- 자바의 정석 기초편 ch6
- 자바의 정석 기초편 ch4
- jpa - 객체지향 쿼리 언어
- Today
- Total
나구리의 개발공부기록
컬렉션 프레임워크 - LinkedList, 노드와 연결, 직접 구현하는 연결 리스트(시작, 추가와 삭제, 제네릭 도입) 본문
컬렉션 프레임워크 - LinkedList, 노드와 연결, 직접 구현하는 연결 리스트(시작, 추가와 삭제, 제네릭 도입)
소소한나구리 2025. 2. 4. 10:59출처 : 인프런 - 김영한의 실전 자바 - 중급2편 (유료) / 김영한님
유료 강의이므로 정리에 초점을 두고 코드는 일부만 인용
1. 노드와 연결
1) 노드와 연결
(1) 설명
- 배열 리스트는 데이터가 얼마나 추가될지 예측할 수 없는 경우 나머지 공간의 메모리가 낭비되는 것과 앞이나 중간에 데이터를 추가, 삭제할 때 성능이 좋지 않은 문제가 있음
- 낭비되는 메모리 없이 딱 필요한 만큼만 메모리를 확보해서 사용하고, 앞이나 중간에 데이터를 추가하거나 삭제할 때도 효율적인 자료구조가 있는데 바로 노드를 만들고 각 노드를 연결하는 방식임
(2-1) 노드 클래스
- 노드 클래스는 내부에 저장할 데이터인 item과 다음으로 연결한 노드의 참조인 next를 가짐
- 이 노드 클래스를 사용해서 데이터 A, B, C를 순서대로 연결하는 것을 그림으로 설명
public class Node {
Object item;
Node next;
}
(2-2) 노드에 데이터 A 추가

- Node 인스턴스를 생성하고 item에 "A"를 넣어줌
(2-3) 노드에 데이터 B 추가

- Node 인스턴스를 생성하고 item에 "B"를 넣어주고 처음 만든 노드의 Node next 필드에 새로 만든 노드의 참조값을 넣어주면 첫번째 노드와 두 번째 노드가 서로 연결됨
- 첫 번째 노드의 node.next를 호출하면 두 번째 노드를 구할 수 있음
(2-4) 노드에 데이터 C 추가

- Node 인스턴스를 생성하고 item에 "C"를 넣어주고 두 번째 만든 노드의 Node next 필드에 새로 만든 노드의 참조값을 넣어주면 두 번째 노드와 세 번째 노드가 서로 연결됨
- 첫 번째 노드의 node.next를 호출하면 두 번째 노드를 구할 수 있고, 두 번째 노드의 node.next를 호출하면 세 번째 노드를 구할 수 있으며 첫 번째 노드의 node.next.next를 호출하면 세 번째 노드를 구할 수 있음
2) 코드 구현
(1) Node
- 필드의 접근 제어자는 private으로 선언하는 것이 좋지만 예제이므로 설명을 단순하게 하기 위해 디폴트 접근 제어자를 사용
- 위에서 설명한 Node를 그대로 구현하였음
package collection.link;
public class Node {
Object item;
Node next;
public Node(Object item) {
this.item = item;
}
}
(2) NodeMain1
- new Node()로 노드를 각각 생성하고, 이전 Node의 next필드에 참조를 저장하고 반복문으로 Node의 item필드를 꺼내는 코드
package collection.link;
public class NodeMain1 {
public static void main(String[] args) {
// 노드 생성하고 연결하기: A -> B -> C
Node first = new Node("A");
first.next = new Node("B");
first.next.next = new Node("C");
System.out.println("모든 노드 탐색하기");
Node x = first;
while (x != null) {
System.out.println(x.item);
x = x.next;
}
}
}
/* 실행 결과
모든 노드 탐색하기
A
B
C
*/
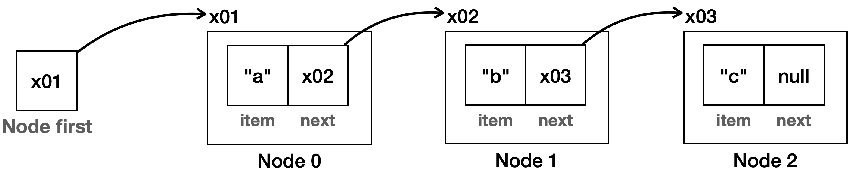
(3-1) 노드 연결하기

- Node first = new Node("A"): Node 인스턴스를 생성하고 item에 "A"를 넣어줌
- Node first = x01: first 변수에 생성된 노드의 참조를 보관함
(3-2) 노드에 데이터 B 추가
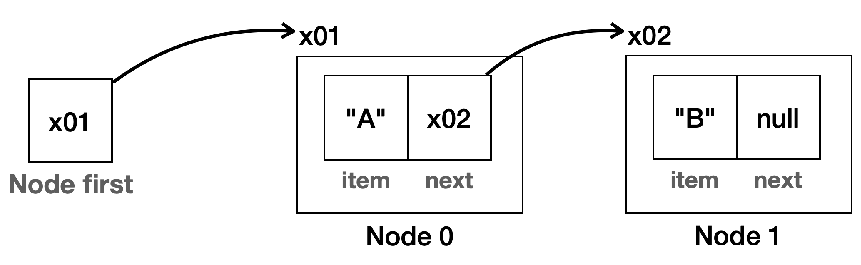
- first.next = new Node("B"): Node 인스턴스를 생성하고 item에 "B"를 넣어줌
- first.next = x02: 처음 만든 노드의 next 필드에 새로 만든 노드의 참조값을 넣어주면 첫 번째 노드와 두 번째 노드가 서로 연결됨
(3-3) 노드에 데이터 C 추가

- first.next.next = new Node("C"): Node 인스턴스를 생성하고 item에 "C"를 넣어줌
- first.next.next = x03: 두 번째 만든 노드의 Node next 필드에 새로 만든 노드의 참조값을 넣어주면 두 번째 노드와 세 번째 노드가 서로 연결됨
- x01.next.next = x03, x02.next = x03이 됨
(4) 연결된 노드를 찾는 방법
- Node first를 통해 첫 번째 노드를 구할 수 있음
- 첫 번째 노드의 node.next를 호출하면 두 번째 노드를 구할 수 있고, 두 번째 노드의 node.next를 호출하면 세 번째 노드를 구할 수 있음
- 첫 번째 노드의 node.next.next를 호출하면 세 번째 노드를 구할 수 있음
(5) 모든 노드 탐색하기

- Node x는 처음 노드부터 순서대로 이동하면서 노드를 가리킴
- Node x는 x01을 참조하고 while문을 통해 반복해서 다음 노드를 가리킴
- while문은 다음 노드가 없을 때까지 반복하고 Node.next의 참조값이 null이면 노드의 끝임
3) Node에 toString 추가
(1) Node - IDE 기능 사용
- 노드의 연결 상태를 더 편하게 보기 위해 toString()을 오버라이딩
package collection.link;
public class Node {
// ... 기존 코드 동일
@Override
public String toString() {
return "Node{" +
"item=" + item +
", next=" + next +
'}';
}
}
(2) NodeMain2
- first 변수로만 출력하면 Node 클래스에서 toString()을 오버라이딩했기 때문에 next 필드에서 다음 노드의 참조값을 가지고 있으므로 계속 toString()이 호출되어서 아래 출력결과와 같이 출력하게 됨
- IDE의 도움을 받아서 만든 toString()으로 필요한 정보를 확인할 수는 있지만 한눈에 보기가 좀 복잡함
package collection.link;
public class NodeMain2 {
public static void main(String[] args) {
// 노드 생성하고 연결하기: A -> B -> C
Node first = new Node("A");
first.next = new Node("B");
first.next.next = new Node("C");
System.out.println("연결된 노드 출력하기");
System.out.println(first);
}
}
/* 실행 결과
연결된 노드 출력하기
Node{item=A, next=Node{item=B, next=Node{item=C, next=null}}}
*/
(3) Node - toString을 직접 구현
- [A->B->C]와 같이 데이터와 연결 구조를 한눈에 볼 수 있도록 toString()을 직접 구현
- 반복문 안에서 문자를 더하기 때문에 StringBuilder를 사용하는 것이 효율적임
- 구현은 앞서 살펴본 모든 노드 탐색하기와 동일하게 while문을 사용하여 다음 노드가 없을 때까지 반복함
- x.next가 null이 아니면 다음 노드가 있는 것이기 때문에 "->"표시를 출력하고 x = x.next로 탐색의 위치를 다음으로 이동
package collection.link;
public class Node {
// ... 기존 코드 동일 생략
// [A->B->C] 모양
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node x = this;
sb.append("[");
while (x != null) {
sb.append(x.item);
if (x.next != null) {
sb.append("->");
}
x = x.next;
}
sb.append("]");
return sb.toString();
}
}
(4) NodeMain2
- 직접 만든 toString()덕분에 NodeMain2의 코드를 수정없이 출력해보면 내부 데이터와 연결 구조를 깔끔하게 볼 수 있음
/* 실행 결과
연결된 노드 출력하기
[A->B->C]
*/4) 다양한 기능 만들기
(1) NodeMain3
- 모든 노드 탐색, 마지막 노드 조회, 특정 index의 노드 조회, 노드에 데이터 추가하는 기능들을 각각 만들어서 실행하는 코드
package collection.link;
public class NodeMain3 {
public static void main(String[] args) {
// 노드 생성하고 연결하기: A -> B -> C
Node first = new Node("A");
first.next = new Node("B");
first.next.next = new Node("C");
System.out.println(first);
// 모든 노드 탐색하기
System.out.println("모든 노드 탐색하기");
printAll(first);
// 마지막 노드 조회하기
Node lastNode = getLastNode(first);
System.out.println("lastNode = " + lastNode);
// 특정 index의 노드 조회하기
int index = 2;
Node index2Node = getNode(first, index);
System.out.println("index2Node = " + index2Node.item);
// 데이터 추가하기
System.out.println("데이터 추가하기");
add(first, "D");
System.out.println(first);
add(first, "E");
System.out.println(first);
add(first, "F");
System.out.println(first);
}
private static void printAll(Node node) {
Node x = node;
while (x != null) {
System.out.println(x.item);
x = x.next;
}
}
private static Node getLastNode(Node node) {
Node x = node;
while (x.next != null) {
x = x.next;
}
return x;
}
private static Node getNode(Node node, int index) {
Node x = node;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
private static void add(Node node, String param) {
Node lastNode = getLastNode(node);
lastNode.next = new Node(param);
}
}
/* 실행 결과
[A->B->C]
모든 노드 탐색하기
A
B
C
lastNode = [C]
index2Node = C
데이터 추가하기
[A->B->C->D]
[A->B->C->D->E]
[A->B->C->D->E->F]
*/
(2) 모든 노드 탐색하기
- printAll(Node node): 다음 노드가 없을 때 까지 반복해서 노드의 데이터를 출력
(3) 마지막 노드 조회하기
- Node getLastNode(Node node): 노드를 순서대로 탐색하면서 Node.next의 참조값이 null인 노드를 찾아서 반환
- 예제에서는 마지막에 있는 C값을 가지고 있는 노드가 출력됨
(4) 특정 index의 노드 조회하기
- getNode(Node node, int index): index로 특정 위치의 노드를 찾음
- index의 수 만큼 x = x.next를 반복 호출하면 x가 참조하는 노드의 위치가 순서대로 하나씩 증가하여 원하는 위치의 노드를 찾을 수 있음
(5) 데이터 추가하기

- add(Node node, String Param)
- 데이터를 추가할 때는 새로운 노드를 만들고 마지막 노드에 새로 만든 노드를 연결하면 됨
- 마지막 노드를 조회하는 getLastNode(node) 메서드를 통해서 마지막 노드를 찾고 해당 노드의 next에 새로운 노드를 생성하여 참조를 입력하면 됨
(6) 정리
- 노드는 내부에 데이터와 다음 노드에 대한 참조를 가지고 있음
- 지금까지 설명한 구조는 각각의 노드가 참조를 통해 연결(Link, 링크)되어 있음
- 데이터를 추가할 때 동적으로 필요한 만큼의 노드만 만들어서 연결하면 되기 때문에 배열과 다르게 메모리를 낭비하지는 않지만, next 필드를 통해 참조값을 보관하기 때문에 배열과 비교하여 추가적인 메모리를 더 사용함
- 이렇게 각각의 노드를 연결(링크)해서 사용하는 자료 구조로 리스트를 만든것을 연결 리스트라고 함
2. 직접 구현하는 연결 리스트
1) 시작
(1) 연결 리스트
- 배열을 통해 리스트를 만든 것을 배열 리스트라고한다면 지금 학습한 노드와 연결 구조를 통해서 만든 리스트를 연결 리스트(링크드 리스트)라고 함
- 연결 리스트는 배열 리스트의 단점인 메모리 낭비, 중간 위치의 데이터 추가에 대한 성능 문제를 어느정도 극복할 수 있음
- 배열 리스트도, 연결 리스트도 모두 같은 리스트이며 리스트의 내부에서 배열을 사용하는지, 노드와 연결 구조를 사용하는지의 차이가 있을 뿐임
- 즉, 배열 리스트를 사용하든 연결 리스트를 사용하든 둘다 리스트 자료 구조이기 때문에 리스트를 사용하는 개발자 입장에서는 내부가 어떻게 돌아가는지는 몰라도 '순서가 있고 중복을 허용하는 자료 구조구나' 라고 생각하고 사용할 수 있어야 함
(2-1) MyLinkedListV1
- Node first: 첫 노드의 위치를 가리킴
- size: 자료 구조에 입력된 데이터의 사이즈, 데이터가 추가될 때마다 하나씩 증가함
- toString()은 IDE의 도움을 받아서 오버라이딩 하였고, 노드를 추가하거나 꺼내는기능들을 정의하였음
package collection.link;
public class MyLinkedListV1 {
private Node first;
private int size = 0;
public void add(Object e) {
Node newNode = new Node(e);
if (first == null) {
first = newNode;
} else {
Node lastNode = getLastNode();
lastNode.next = newNode;
}
size++;
}
private Node getLastNode() {
Node x = first;
while (x.next != null) {
x = x.next;
}
return x;
}
public Object set(int index, Object element) {
Node x = getNode(index);
Object oldValue = x.item;
x.item = element;
return oldValue;
}
public Object get(int index) {
Node x = getNode(index);
return x.item;
}
private Node getNode(int index) {
Node x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
public int indexOf(Object o) {
int index = 0;
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
return index;
}
index++;
}
return -1;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyLinkedListV1{" +
"first=" + first +
", size=" + size +
'}';
}
}
(2-2) void add(Object e)
- 새로운 노드를 만들고 getLastNode()를 통해 마지막 노드를 찾아서 새로운 노드를 마지막에 연결함
- 만약 노드가 하나도 없으면 새로 만든 노드를 first에 연결
(2-3) Object set(int index, Object element)
- 특정 위치에 있는 데이터를 찾아서 변경하고 기존 값을 반환
- getNode(index)를 통해 특정 위치에 있는 노드를 찾고 그 노드의 item 데이터를 변경함
(2-4) Object get(int index)
- 특정 위치에 있는 데이터를 반환
- getNode(index)를 통해 특정 위치에 있는 노드를 찾고 해당 노드에 있는 값을 반환
(2-5) int indexOf(Object o)
- 데이터를 검색하고 검색된 위치를 반환
- 모든 노드를 순회하면서 equals()를 사용하여 같은 데이터가 있는지 찾음
(3) MyLinkedListV1Main
- ArrayList 강의에서 만들었던 MyArrayListV1Main을 MyLinkedListV1()을 사용하도록 변경만 하고 나머지는 거의 그대로 사용하여도 정상적으로 코드가 동작하여 출력되는 것을 확인할 수 있음
- MyArrayListV1 리스트와 제공하는 기능이 같기 때문에 메서드 이름도 같게 맞추어 두었음
- 연결 리스트는 데이터를 추가할 때 마다 동적으로 노드가 늘어나기 때문에 범위를 초과하는 문제가 발생하지 않음
package collection.link;
public class MyLinkedListV1Main {
public static void main(String[] args) {
MyLinkedListV1 list = new MyLinkedListV1();
System.out.println("==데이터 추가==");
System.out.println(list);
list.add("a");
System.out.println(list);
list.add("b");
System.out.println(list);
list.add("c");
System.out.println(list);
System.out.println("==기능 사용==");
System.out.println("list.size = " + list.size());
System.out.println("list.get(1) = " + list.get(1));
System.out.println("list.indexOf('c') = " + list.indexOf("c"));
System.out.println("list.set(2, 'z') = " + list.set(2, "z"));
System.out.println(list);
list.add("d");
System.out.println(list);
list.add("e");
System.out.println(list);
list.add("f");
System.out.println(list);
}
}
/* 실행 결과
==데이터 추가==
MyLinkedListV1{first=null, size=0}
MyLinkedListV1{first=[a], size=1}
MyLinkedListV1{first=[a->b], size=2}
MyLinkedListV1{first=[a->b->c], size=3}
==기능 사용==
list.size = 3
list.get(1) = b
list.indexOf('c') = 2
list.set(2, 'z') = c
MyLinkedListV1{first=[a->b->z], size=3}
MyLinkedListV1{first=[a->b->z->d], size=4}
MyLinkedListV1{first=[a->b->z->d->e], size=5}
MyLinkedListV1{first=[a->b->z->d->e->f], size=6}
*/2) 연결 리스트와 빅오
(1) Object get(int index)
- 특정 위치에 있는 데이터를 반환할 때: O(n)
- 배열은 인덱스로 원하는 데이터를 즉시 찾을 수 있어 배열을 사용하는 배열 리스트도 인덱스로 조회시 O(1)의 빠른 성능을 보장함
- 그러나, 연결 리스트에서 사용하는 노드들은 배열이 아니라 다음 노드에 대한 참조가 있을 뿐이므로 인덱스로 원하는 위치의 데이터를 찾으려면 인덱스 숫자 만큼 다음 노드를 반복해서 찾아야 함
- 즉, 연결 리스트는 인덱스 조회 성능이 나쁨
(2) void add(Object e)
- 마지막에 데이터를 추가할 때: O(n)
- 마지막 노드에 새로운 노드를 추가하는데는 O(1)이 걸리지만 마지막 노드를 찾는데에 마찬가지로 반복문으로 처음부터 끝까지 참조를 넘겨서 마지막을 찾아야 하므로 O(n)이 걸림
(3) Object set(int index, Object element)
- 특정 위치에 있는 데이터를 찾아서 변경하고 기존 값을 변경할 때: O(n)
- 마찬가지로 특정 위치의 노드를 찾는데 O(n)이 걸림
(4) int indexOf(Object o)
- 데이터를 검색하고 검색된 위치를 반환할 때: O(n)
- 모든 노드를 순회하면서 equals()를 사용하여 같은 데이터가 있는지 찾아야 하므로 O(n)이 걸림
(5) 정리
- 연결 리스트는 연결을 유지하기 위한 추가 메모리가 사용되는 단점이 존재하지만 참조를 통해 데이터를 추가하기 때문에 꼭 필요한 메모리를 사용함
3) 추가와 삭제 - 이론
(1) 데이터를 추가, 삭제 기능 추가
- void add(int index, Object e): 특정 위치에 데이터를 추가하고 내부에서 노드도 함께 추가
- void remove(int index): 특정 위치의 데이터를 삭제하고 내부에서 노드도 함께 삭제
(2) 첫 번째 위치에 데이터 추가

- [a->b->c]라는 데이터가 있을 때 첫 번째 항목에 "d"를 추가해서 [d->a->b->c]로 만드는 과정을 분석
- 연결 리스트는 배열처럼 실제 index가 존재하는 것이 아니라 처음 연결된 노드를 index 0, 그 다음 노드를 index 1로 가정할 뿐으로 연결 리스트에서 index는 연결된 순서를 뜻함
- 신규 생성된 노드를 다음 노드와 연결하고 처음 노드의 참조값을 담는 first에 신규 노드를 연결하면 됨
- 배열의 경우 첫 번째 항목에 데이터가 추가되면 모든 데이터를 오른쪽으로 하나씩 밀어야 하지만 연결 리스트는 새로 생성한 노드의 참조만 변경하고 나머지 노드는 어떤 일이 발생했는지 모름
- 연결 리스트의 첫 번째 항목에 값을 추가하는 것은 매우 빠르며 O(1)로 표현할 수 있음
(4) 첫 번째 위치의 데이터 삭제

- [d->a->b->c]로 만들어진 노드를 첫 번째 항목을 삭제하여 [a->b->c]로 변경 과정을 분석
- first에 삭제 대상의 다음 노드를 연결하고 삭제 대상의 데이터를 초기화
- 삭제 대상인 노드는 더이상 참조하는 곳이 없으므로 GC의 대상이되어 제거됨
- 배열의 경우 첫 번째 항목이 삭제되면 모든 데이터를 왼쪽으로 하나씩 밀어야 했지만 연결 리스트는 일부 참조만 변경하기만 하면 됨
- 연결리스트의 첫 번째 항목에 값을 삭제하는 것은 O(1)로 매우 빠름
(5) 중간 위치에 데이터 추가

- [a->b->c]로 만들어진 노드의 1번 인덱스 위치에 e를 추가하여 [a->e->b->c]로 변경하는 과정을 분석
- 새로운 노드를 생성하고 노드가 입력될 위치의 직전 노드를 먼저 찾음
- 찾은 직전 노드를 prev라고 가정하면, prev의 다음 노드와 신규 노드를 연결한 뒤 prev와 신규 노드를 연결하면 됨
- 위치를 찾고 노드를 추가하는데는 O(1)이 걸리지만 인덱스를 사용하여 노드를 추가할 위치를 찾는데 O(n)이 걸리므로 결과적으로 O(n)의 성능을 보임
(5) 중간 위치에 데이터 삭제
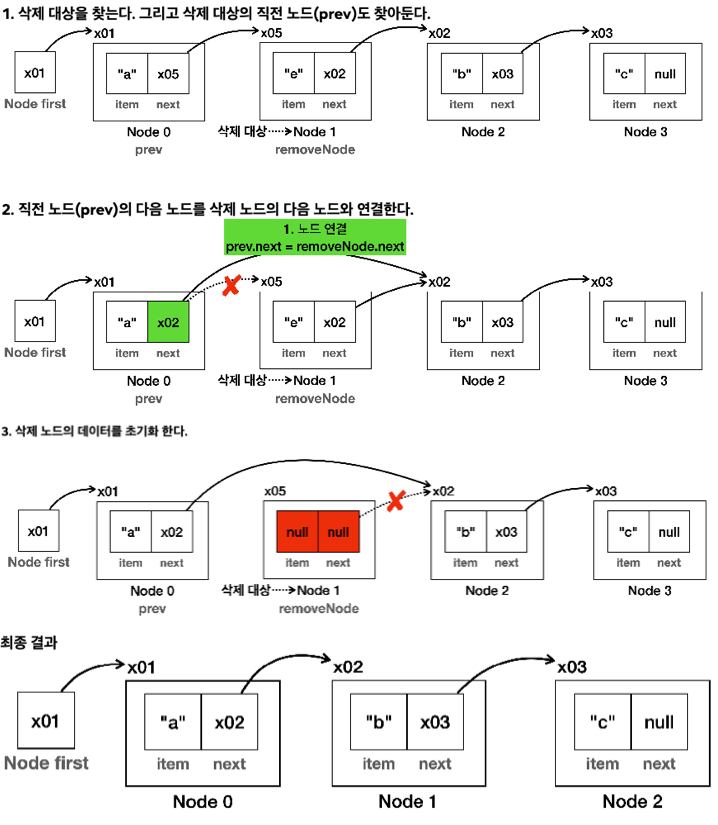
- 삭제 대상과 삭제 대상의 직전 노드(prev)를 찾은 후 prev의 다음 노드를 삭제 대상의 다음 노드와 연결하고 삭제 노드의 데이터를 초기화함
- 삭제 대상의 노드는 참조하는 곳이 없으므로 GC의 대상이 되어 제거됨
- 중간 항목을 추가하는 것과 비슷하게 돌아가며 삭제하는 것은 매우 빨라서 O(1)이지만 삭제할 항목을 찾는데에 O(n)의 성능이 나오기 때문에 결국 O(n)의 성능을 보임
4) 추가와 삭제 - 실습
(1) MyLinkedListV2
- 위에서 이론으로 학습한 void(add int index, Object e)와, Object remove(int index)를 코드로 구현
- 코드로만 보면 동작이 이해가 어려우므로 그림과 함께 코드를 이해하는 것을 권장함
package collection.link;
public class MyLinkedListV2 {
// ... 기존 코드 동일 생략
// 추가 코드
public void add(int index, Object e) {
Node newNode = new Node(e);
if (index == 0) {
newNode.next = first;
first = newNode;
} else {
Node prev = getNode(index - 1);
newNode.next = prev.next;
prev.next = newNode;
}
size++;
}
// 추가 코드
public Object remove(int index) {
Node removeNode = getNode(index);
Object removedItem = removeNode.item;
if (index == 0) {
first = removeNode.next;
} else {
Node prev = getNode(index - 1);
prev.next = removeNode.next;
}
removeNode.item = null;
removeNode.next = null;
size--;
return removedItem;
}
}
(2) MyLinkedListV2Main
- 직접 만든 기능을 사용해보는 코드
package collection.link;
public class MyLinkedListV2Main {
public static void main(String[] args) {
MyLinkedListV2 list = new MyLinkedListV2();
// 마지막에 추가, O(n)
list.add("a");
list.add("b");
list.add("c");
System.out.println(list);
// 첫 번째 항목에 추가, 삭제
System.out.println("첫 번째 항목에 추가");
list.add(0, "d"); // O(1)
System.out.println(list);
System.out.println("첫 번째 항목을 삭제");
list.remove(0); // O(1)
System.out.println(list);
// 중간 항목에 추가, 삭제
System.out.println("중간 항목에 추가");
list.add(1, "e"); // O(n)
System.out.println(list);
System.out.println("중간 항목을 삭제");
list.remove(1); // O(1)
System.out.println(list);
}
}
/* 실행 결과
MyLinkedListV2{first=[a->b->c], size=3}
첫 번째 항목에 추가
MyLinkedListV2{first=[d->a->b->c], size=4}
첫 번째 항목을 삭제
MyLinkedListV2{first=[a->b->c], size=3}
중간 항목에 추가
MyLinkedListV2{first=[a->e->b->c], size=4}
중간 항목을 삭제
MyLinkedListV2{first=[a->b->c], size=3}
*/
(3) 직접 만든 배열 리스트와 연결 리스트의 성능 비교 표
| 기능 | 배열 리스트 | 연결 리스트 |
| 인덱스 조회 | O(1) | O(n) |
| 검색 | O(n) | O(n) |
| 앞에 추가 / 삭제 | O(n) | O(1) |
| 뒤에 추가 / 삭제 | O(1) | O(n) |
| 평균 추가 / 삭제 | O(n) | O(n) |
- 배열 리스트는 인덱스를 통해 추가하거나 삭제할 위치를 O(1)로 빠르게 찾지만 추가나 삭제 이후에 데이터를 한 칸씩 밀어야하므로 이부분이 O(n)이 걸림
- 반면 연결 리스트는 인덱스를 통해 추가나 삭제할 위치를 찾는 것이 O(n)이 걸리지만 찾은 이후에는 일부 노드의 참조값만 변경하면 되기 때문에 이부분이 O(1)로 빠름
- 데이터를 앞쪽에 추가하는 경우에는 연결리스트가 더 좋은 성능을 제공하는데 배열 리스트처럼 추가한 항목의 오른쪽에 있는 데이터를 한 칸씩 밀지 않아도 되기 때문임
- 하지만 마지막에 데이터를 추가하는 경우에는 연결 리스트의 경우 노드를 마지막까지 순회해야하기 때문에 O(n)의 성능이 걸리므로, 인덱스로 마지막 위치를 바로 찾을 수 있는 배열 리스트가 더 성능이 좋음
(4) 배열 리스트 vs 연결 리스트 사용
- 데이터를 조회할 일이 많고 뒷 부분에 데이터를 추가할 일이 많을 때: 배열 리스트가 보통 더 좋은 성능을 제공함
- 앞쪽의 데이터를 추가하거나 삭제할 일이 많을 때: 연결 리스트를 사용하는 것이 더 좋은 성능을 제공함
** 참고 - 단일 연결 리스트, 이중 연결 리스트
- 지금 직접 구현한 연결리스트는 한 방향으로만 이동하는 단일 연결 리스트이지만 노드를 앞 뒤로 모두 연결하는 이중 연결 리스트를 사용하면 성능을 더 개선할 수 있으며 자바가 제공하는 연결리스트는 이중 연결 리스트임
- 뒤에서 자세히 설명하지만 이중 연결 리스트는 마지막 노드를 참조하는 변수를 가지고 있어서 뒤에 추가하거나 삭제하는 경우에도 O(1)의 성능을 제공함
// 이중 연결 리스트 예시
public class Node {
Object item;
Node next; // 다음 노드 참조
Node prev; // 이전 노드 참조
}
// 마지막 노드를 참조하는 연결 리스트 예시
public class LinkedList {
private Node first;
private Node last; // 마지막 노드 참조
private int size = 0;
}5) 제네릭 도입
(1) MyLinkedListV3<E>
- 타입 안정성을 높이기 위해 제네릭을 도입
- 연결 리스트에 사용하는 Node는 외부에서 사용되는 것이 아니라 연결 리스트 내부에서만 사용하므로 중첩 클래스로 작성
- Object로 처리하던 부분을 타입 매개변수 <E>로 변경하고 정적 중첩 클래스로 새로 선언한 Node<E>도 제네릭 타입으로 선언함
package collection.link;
public class MyLinkedListV3<E> {
private Node<E> first;
private int size = 0;
public void add(E e) {
Node<E> newNode = new Node<>(e);
if (first == null) {
first = newNode;
} else {
Node<E> lastNode = getLastNode();
lastNode.next = newNode;
}
size++;
}
private Node<E> getLastNode() {
Node<E> x = first;
while (x.next != null) {
x = x.next;
}
return x;
}
// 추가 코드
public void add(int index, E e) {
Node<E> newNode = new Node<>(e);
if (index == 0) {
newNode.next = first;
first = newNode;
} else {
Node<E> prev = getNode(index - 1);
newNode.next = prev.next;
prev.next = newNode;
}
size++;
}
public E set(int index, E element) {
Node<E> x = getNode(index);
E oldValue = x.item;
x.item = element;
return oldValue;
}
// 추가 코드
public E remove(int index) {
Node<E> removeNode = getNode(index);
E removedItem = removeNode.item;
if (index == 0) {
first = removeNode.next;
} else {
Node<E> prev = getNode(index - 1);
prev.next = removeNode.next;
}
removeNode.item = null;
removeNode.next = null;
size--;
return removedItem;
}
public E get(int index) {
Node<E> x = getNode(index);
return x.item;
}
private Node<E> getNode(int index) {
Node<E> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
public int indexOf(E o) {
int index = 0;
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
return index;
}
index++;
}
return -1;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyLinkedListV3{" +
"first=" + first +
", size=" + size +
'}';
}
private static class Node<E> {
E item;
Node<E> next;
public Node(E item) {
this.item = item;
}
// [A->B->C] 모양
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node<E> x = this;
sb.append("[");
while (x != null) {
sb.append(x.item);
if (x.next != null) {
sb.append("->");
}
x = x.next;
}
sb.append("]");
return sb.toString();
}
}
}
(2) MyLinkedListV3Main
- 제네릭을 사용한 MyLinkedList도 모두 정상적으로 동작하는 것을 확인할 수 있으며, 제네릭 덕분에 타입 안정성이 있는 자료구조를 만들 수 있게 되었음
package collection.link;
public class MyLinkedListV3Main {
public static void main(String[] args) {
MyLinkedListV3<String> stringList = new MyLinkedListV3<>();
stringList.add("a");
stringList.add("b");
stringList.add("c");
String string = stringList.get(0);
System.out.println("string = " + string);
MyLinkedListV3<Integer> integerList = new MyLinkedListV3<>();
integerList.add(1);
integerList.add(2);
integerList.add(3);
Integer integer = integerList.get(0);
System.out.println("integer = " + integer);
}
}
/* 실행 결과
string = a
integer = 1
*/


