
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 람다
- 스프링 mvc2 - 검증
- 자바로 계산기 만들기
- 2024 정보처리기사 수제비 실기
- 자바의 정석 기초편 ch13
- 자바의 정석 기초편 ch1
- 자바 고급2편 - 네트워크 프로그램
- 자바 기초
- 자바의 정석 기초편 ch4
- 자바의 정석 기초편 ch7
- 자바의 정석 기초편 ch6
- 스프링 입문(무료)
- 스프링 mvc2 - 로그인 처리
- 스프링 고급 - 스프링 aop
- 자바의 정석 기초편 ch2
- 스프링 mvc2 - 타임리프
- 자바의 정석 기초편 ch12
- @Aspect
- 자바로 키오스크 만들기
- 자바 중급2편 - 컬렉션 프레임워크
- 스프링 트랜잭션
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch14
- 자바 고급2편 - io
- 자바 중급1편 - 날짜와 시간
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch9
- 자바의 정석 기초편 ch5
- 2024 정보처리기사 시나공 필기
- 데이터 접근 기술
- Today
- Total
개발공부기록
스레드 풀과 Executor 프레임워크, ExecutorService 우아한 종료(소개, 구현), Executor 스레드 풀 관리(코드, 분석), Executor 전략(고정 풀 전략, 캐시 풀 전략, 사용자 정의 풀 전략), Executor 예외 정책 본문
스레드 풀과 Executor 프레임워크, ExecutorService 우아한 종료(소개, 구현), Executor 스레드 풀 관리(코드, 분석), Executor 전략(고정 풀 전략, 캐시 풀 전략, 사용자 정의 풀 전략), Executor 예외 정책
소소한나구리 2025. 2. 16. 12:49출처 : 인프런 - 김영한의 실전 자바 - 고급1편 (유료) / 김영한님
유료 강의이므로 정리에 초점을 두고 코드는 일부만 인용
1. ExecutorService 우아한 종료
1) 소개
(1) 우아한 종료
- 고객의 주문을 처리하는 서버를 운영중일 때 서버 기능을 업데이트 위해서 서버를 재시작해야 한다고 가정
- 이때 서버 애플리케이션이 고객의 주문을 처리하고 있는 도중에 갑자기 재시작된다면 해당 고객의 주문이 제대로 진행되지 못할 것임
- 가장 이상적인 방향은 새로운 주문 요청은 막고, 이미 진행 중인 주문은 모두 완료한 다음에 서버를 재시작하는 것임
- 이처럼 서비스를 안정적으로 종료하는 것도 매우 중요한데 이렇게 문제없이 우아하게 종료하는 방식을 graceful shutdown이라 함
(2) ExecutorService의 종료 메서드
- 서비스 종료
- void shutdown(): 새로운 작업을 받지 않고 이미 제출된 작업을 모두 완료한 후에 종료, 논 블로킹 메서드이므로 이 메서드를 호출한 스레드는 대기하지 않고 즉시 다음 코드를 호출함
- List<Runnable> shutdownNow(): 실행 중인 작업을 중단하고 대기 중인 작업을 반환하며 즉시 종료함, 실행 중인 작업을 중단하기 위해 인터럽트를 발생시킴, 논 블로킹 메서드임
- close(): 자바 19부터 지원하는 서비스 종료 메서드로 shutdown()을 호출하고 하루를 기다려도 작업이 완료되지 않으면 shutdownNow()를 호출함, 호출한 스레드에 인터럽트가 발생해도 shutdownNow()를 호출함
- 서비스 상태 확인
- boolean isShutdown(): 서비스가 종료되었는지 확인
- boolean isTerminated(): shutdown(), shutdownNow() 호출 후 모든 작업이 완료되었는지 확인함
- 작업 완료 대기
- boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException: 서비스 종료 시 지정된 시간까지만 작업이 완료될 때까지 대기함, 블로킹 메서드
(3) shutdown() - 처리 중인 작업이 없는 경우


- ExecutorService에 아무런 작업이 없고 스레드만 2개 대기하고 있음
- shutdown()을 호출하면 ExecutorService는 새로운 요청을 거절하는데 이때 기본적으로 RejectedExecutionException 예외가 발생하고 스레드 풀의 자원을 정리함
(4) shutdown() - 처리중인 작업이 있는 경우
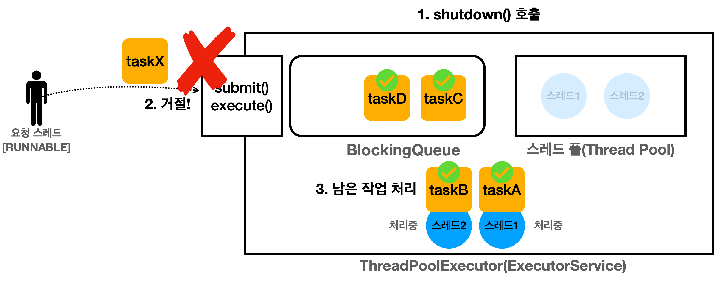

- 큐에 대기 중인 작업과 처리 중인 작업이 있을 때 shutdown()을 호출하면 ExecutorService는 새로운 요청을 거절하고 스레드 풀의 스레드는 처리중인 작업을 완료하고 큐에 남아있는 작업도 모두 꺼내서 완료함
- 모든 작업을 완료하면 자원을 정리하므로 처리 중이던 작업과 대기 중이던 작업이 모두 완료되고 종료됨
(5) shutdownNow() - 처리 중인 작업이 있는 경우

- 대기 중인 작업과 처리중인 작업이 있을 때 shutdownNow()를 호출하면 ExecutorService는 새로운 요청을 거절함
- 큐를 비우면서 큐에 있는 작업을 모두 꺼내서 컬렉션으로 반환하고 작업 중인 스레드에 인터럽트가 발생함
- 즉, 작업 중인 taskA, taskB는 인터럽트가 걸리고, 대기중인 taskC, taskD는 수행되지 않고 컬렉션으로 반환되며(Runnable, Future) 작업이 완료되면 자원을 정리함
2) 구현
(1) 우아한 종료 구현
- shutdown()을 호출해서 이미 들어온 모든 작업을 다 처리하고 서비스를 우아하게 종료하는 것이 가장 이상적이지만 갑자기 요청이 너무 많이 들어와서 큐에 대기중인 작업이 너무 많아 작업이 어렵거나, 작업이 너무 오래 걸리거나, 버그가 발생하여 특정 작업이 끝나지 않을 수 있음
- 이렇게 되면 서비스가 너무 늦게 종료되거나 종료되지 않는 문제가 발생할 수 있음
- 이럴 때는 보통 우아하게 종료하는 시간을 정하는데 예를 들면 60초까지는 작업을 다 처리할 수 있게 기다리고 60초가 지나면 문제가 있다고 가정하고 shutdownNow()를 호출해서 작업들을 강제로 종료하면 됨
- close()의 경우 이렇게 구현이 되어있으며 shutdown()을 호출하고 하루를 기다려도 작업이 완료되지 않으면 shutdownNow()를 호출함, 그러나 대부분 하루를 기다릴 수는 없을 것임
- shutdown()을 통해 우아한 종료를 시도하고 예제이므로 60초가 아닌 10초간 종료되지 않으면 shutdownNow()를 통해 강제 종료하는 방식을 직접 구현
- 예제에서 구현할 shutdownAndAwaitTermination()은 ExecutorService 공식 API 문서에서 제안하는 방식임
(2) ExecutorShutdownMain
- 1초간 걸리는 작업 3개와 100초간 걸리는 작업을 하나 만들고 작업을 시작한 후 중간에 shutdownAndAwaitTermination() 메서드를 호출해서 작업종료를 시도
- shutdownAndAwaitTermination()
- 우아한 종료를 위해 shutdown()을 시도하고, 10초가 기다려도 스레드의 작업이 끝나지 않으면 shutdownNow()를 호출
- shutdownNow()를 호출한 후 10초가 기다려도 끝나지 않으면 서비스가 종료되지 않았다는 로그를 남김
- awaitTermination()으로 대기중인 스레드가 인터럽트될 수 있으므로 인터럽트 된 스레드를 shutdownNow()로 종료
- 출력 결과를 보면 작업 중인 스레드에 shutdownNow()가 실행되어 인터럽트가 발생하고 내부 로직에 따라 RuntimeException이 발생한 것을 확인할 수 있음
package thread.executor;
public class ExecutorShutdownMain {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(2);
es.execute(new RunnableTask("taskA"));
es.execute(new RunnableTask("taskB"));
es.execute(new RunnableTask("taskC"));
es.execute(new RunnableTask("longTask", 100_000)); // 100초 대기
ExecutorUtils.printState(es);
log("== shutdown 시작 ==");
shutdownAndAwaitTermination(es);
log("== shutdown 시작 ==");
ExecutorUtils.printState(es);
}
private static void shutdownAndAwaitTermination(ExecutorService es) {
// non-blocking, 새로운 작업을 받지 않고 처리 중이거나 큐에 이미 대기중인 작업은 처리함, 이후에 풀의 스레드를 종료함
es.shutdown();
try {
// 이미 대기중인 작업들을 모두 완료할 때 까지 10초 기다림
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {
// 정상 종료가 너무 오래 걸리면
log("서비스 정상 종료 실패 -> 강제 종료 시도");
es.shutdownNow();
// 작업이 취소될 때 까지 대기함
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {
log("서비스가 종료되지 않았습니다.");
}
}
} catch (InterruptedException e) {
// awaitTermination()으로 대기중인 현재 스레드가 인터럽트 될 수 있음
es.shutdownNow();
}
}
}
/* 실행 결과
14:27:14.597 [ main] [pool=2, active=2, queuedTasks=2, completedTasks=0]
14:27:14.599 [ main] == shutdown 시작 ==
14:27:14.597 [pool-1-thread-2] taskB 시작
14:27:14.598 [pool-1-thread-1] taskA 시작
14:27:15.605 [pool-1-thread-2] taskB 완료
14:27:15.608 [pool-1-thread-1] taskA 완료
14:27:15.608 [pool-1-thread-1] longTask 시작
14:27:15.608 [pool-1-thread-2] taskC 시작
14:27:16.617 [pool-1-thread-2] taskC 완료
14:27:24.605 [ main] 서비스 정상 종료 실패 -> 강제 종료 시도
14:27:24.609 [pool-1-thread-1] 인터럽트 발생, sleep interrupted
14:27:24.610 [ main] == shutdown 시작 ==
14:27:24.611 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=4]
Exception in thread "pool-1-thread-1" java.lang.RuntimeException: java.lang.InterruptedException: sleep interrupted
at util.ThreadUtils.sleep(ThreadUtils.java:12)
at thread.executor.RunnableTask.run(RunnableTask.java:22)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: java.lang.InterruptedException: sleep interrupted
at java.base/java.lang.Thread.sleep0(Native Method)
at java.base/java.lang.Thread.sleep(Thread.java:509)
at util.ThreadUtils.sleep(ThreadUtils.java:9)
... 4 more
*/
(3) 실행 로직 분석
es.shutdown();- 새로운 작업은 더 이상 받지 않고 처리 중이거나 큐에 이미 대기 중인 작업을 처리하고 스레드를 종료시킴
- 블로킹 메서드가 아니기 때문에 main 스레드는 대기하지 않고 바로 다음 코드를 호출함
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {- 블로킹 메서드로 main 스레드는 서비스 종료를 10초간 기다림
- 만약 10초 안에 모든 작업들이 완료됨다면 true를 반환하지만 longTask는 10초가 지나도 완료되지 않으므로 false를 반환함
log("서비스 정상 종료 실패 -> 강제 종료 시도");
es.shutdownNow();
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {
log("서비스가 종료되지 않았습니다.");
}- 정상 종료가 10초 이상 너무 오래 걸렸으므로 shutdownNow()를 통해 강제 종료에 들어감
- 강제 종료를 하면 작업 중인 스레드에 인터럽트가 발생하는데 shutdownNow()도 블로킹 메서드가 아니기 때문에 바로 인터럽트가 발생하면서 스레드도 작업을 종료하고 shutdownNow()를 통한 강제 shutdown도 완료됨
- 마지막에 강제 종료인 es.shutdownNow()를 호출한 다음에 10초간 또 기다리는 이유는 shutdownNow()가 작업 중인 스레드에 인터럽트를 호출하더라도 여러 가지 이유로 작업에 시간이 더 걸릴 수 있음
- 인터럽트 이후에 자원을 정리하는 간단한 작업을 수행할 수도 있기 때문에 이런 시간을 기다려주는 것임
- 최악의 경우 스레드가 인터럽트를 받을 수 없는 코드를 수행중일 수도 있기 때문에 강제 종료 후 10초간 대기해도 작업이 완료되지 않으면 개발자가 인지할 수 있는 로그를 남겨두어야 개발자가 나중에 문제를 찾아서 코드를 수정할 수 있음
(4) 정리
- 서비스를 종료할 때 생각보다 고려해야 할 점이 많음
- 기본적으로 우아한 종료를 선택하고 우아한 종료가 되지 않으면 무한정 기다릴 수는 없으니 그다음으로 강제 종료를 하는 방식으로 접근하는 것이 좋음
2. Executor 스레드 풀 관리
1) 코드
(1) ExecutorUtils - 추가
- Executor 프레임워크가 스레드를 관리하는지 상태를 출력하기 위해 만들었던 ExecutorUtils의 printState() 메서드에 taskName을 추가하여 남겨지는 로그에 taskName을 출력하도록 변경
package util;
public abstract class ExecutorUtils {
public static void printState(ExecutorService executorService, String taskName) {
if (executorService instanceof ThreadPoolExecutor poolExecutor) {
int pool = poolExecutor.getPoolSize();
int active = poolExecutor.getActiveCount();
int queueTasks = poolExecutor.getQueue().size();
long completedTask = poolExecutor.getCompletedTaskCount();
log(taskName + " -> [pool=" + pool + ", active=" + active + ", queuedTasks=" + queueTasks +
", completedTasks=" + completedTask + "]");
} else {
log(executorService);
}
}
}
(2) PoolSizeMainV1
- 작업을 보관한 블로킹 큐의 구현체로 ArrayBlockingQueue(2)를 사용하여 최대 2개까지 작업을 큐에 보관하도록 설정
- corePoolSize=2, maximumPoolSize=4
- 기본 스레드는 2개, 최대 스레드는 4개로 설정하면 스레드 풀에 기본 2개 스레드를 운영하고 요청이 너무 많거나 급한 경우 스레드 풀은 최대 4개까지 스레드를 증가시켜서 사용할 수 있음
- 이렇게 기본 스레드 수를 초과해서 만들어진 스레드를 초과 스레드라고 하며, 요청이 많거나 급한 경우는 기본 스레드뿐만 아니라 큐에 작업이 모두 가득 찬 경우를 말함
- 3000, TimeUnit.MILLISECONDS
- 초과 스레드가 생존할 수 있는 대기 시간을 뜻하며 이 시간 동안 초과 스레드가 처리할 작업이 없다면 초과 스레드는 제거됨
- 여기서는 3초로 설정했으므로 초과 스레드가 3초간 작업을 하지 않고 대기하면 스레드 풀에서 제거됨
package thread.executor.poolsize;
public class PoolSizeMainV1 {
public static void main(String[] args) {
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(2);
ExecutorService es = new ThreadPoolExecutor(2, 4,
3000, TimeUnit.MILLISECONDS, workQueue);
printState(es);
es.execute(new RunnableTask("task1"));
printState(es, "task1");
es.execute(new RunnableTask("task2"));
printState(es, "task2");
es.execute(new RunnableTask("task3"));
printState(es, "task3");
es.execute(new RunnableTask("task4"));
printState(es, "task4");
es.execute(new RunnableTask("task5"));
printState(es, "task5");
es.execute(new RunnableTask("task6"));
printState(es, "task6");
try {
es.execute(new RunnableTask("task7"));
} catch (RejectedExecutionException e) {
log("task7 실행 거절 예외 발생: " + e);
}
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
sleep(3000);
log("== maximumPooSize 대기 시간 초과 == ");
printState(es);
es.close();
log("== shutdown 완료 ==");
printState(es);
}
}
/* 실행 결과
16:07:11.821 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
16:07:11.823 [pool-1-thread-1] task1 시작
16:07:11.829 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]
16:07:11.829 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
16:07:11.829 [pool-1-thread-2] task2 시작
16:07:11.829 [ main] task3 -> [pool=2, active=2, queuedTasks=1, completedTasks=0]
16:07:11.829 [ main] task4 -> [pool=2, active=2, queuedTasks=2, completedTasks=0]
16:07:11.830 [ main] task5 -> [pool=3, active=3, queuedTasks=2, completedTasks=0]
16:07:11.830 [pool-1-thread-3] task5 시작
16:07:11.830 [ main] task6 -> [pool=4, active=4, queuedTasks=2, completedTasks=0]
16:07:11.830 [pool-1-thread-4] task6 시작
16:07:11.830 [ main] task7 실행 거절 예외 발생: java.util.concurrent.RejectedExecutionException: Task thread.executor.RunnableTask@67424e82 rejected from java.util.concurrent.ThreadPoolExecutor@2f4d3709[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
16:07:12.830 [pool-1-thread-1] task1 완료
16:07:12.831 [pool-1-thread-1] task3 시작
16:07:12.834 [pool-1-thread-2] task2 완료
16:07:12.835 [pool-1-thread-3] task5 완료
16:07:12.835 [pool-1-thread-2] task4 시작
16:07:12.835 [pool-1-thread-4] task6 완료
16:07:13.834 [pool-1-thread-1] task3 완료
16:07:13.841 [pool-1-thread-2] task4 완료
16:07:14.836 [ main] == 작업 수행 완료 ==
16:07:14.839 [ main] [pool=4, active=0, queuedTasks=0, completedTasks=6]
16:07:17.845 [ main] == maximumPooSize 대기 시간 초과 ==
16:07:17.845 [ main] [pool=2, active=0, queuedTasks=0, completedTasks=6]
16:07:17.847 [ main] == shutdown 완료 ==
16:07:17.848 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=6]
*/2) 분석
(1) 작업 생성

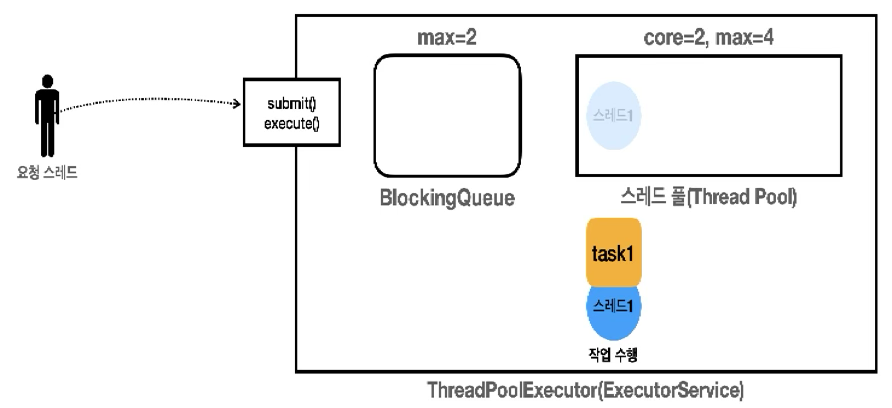
16:07:11.821 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
16:07:11.823 [pool-1-thread-1] task1 시작
16:07:11.829 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]- Executor의 최초 상태는 스레드 풀에 스레드가 없으며 작업요청이 오면 스레드를 생성함
- 요청 스레드가 task1 작업을 요청하면 Executor는 스레드 풀에 스레드가 core 사이즈만큼 있는지 확인하고 없다면 스레드를 하나 생성함
- 작업을 처리하기 위해 스레드를 하나 생성했기 때문에 작업을 큐에 넣을 필요 없이 해당 스레드가 작업을 바로 처리함


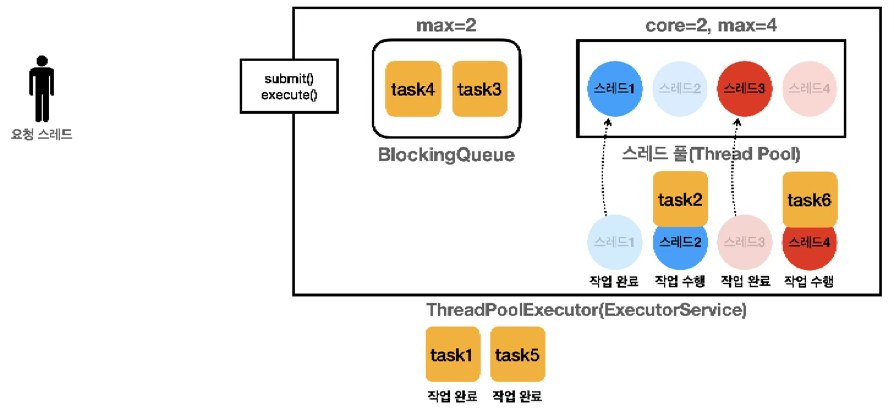
16:07:11.829 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
16:07:11.829 [pool-1-thread-2] task2 시작
16:07:11.829 [ main] task3 -> [pool=2, active=2, queuedTasks=1, completedTasks=0]- 요청 스레드가 task2를 요청하면 Executor가 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인하고 core 사이즈 만큼 없으므로 스레드를 하나 생성하고 해당 스레드도 바로 task2 작업을 수행함
- 이후 task3을 요청하면 Executor가 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인하는데 이미 core 사이즈 만큼 스레드가 만들어져 있고 사용할 수 있는 스레드도 없음
- 이 경우에는 스레드를 생성하지 않고 블로킹 큐에 작업을 보관해 둠


16:07:11.829 [ main] task4 -> [pool=2, active=2, queuedTasks=2, completedTasks=0]
16:07:11.830 [ main] task5 -> [pool=3, active=3, queuedTasks=2, completedTasks=0]
16:07:11.830 [pool-1-thread-3] task5 시작- task4 작업을 요청하면 마찬가지로 core 사이즈만큼 스레드가 이미 만들어져있고 모두 사용중이기 때문에 큐에 작업이 보관되어 작업 큐에도 공간이 꽉 참
- task5 작업을 요청하면 Executor가 스레드 풀에 core 사이즈만큼 있는지 먼저 확인함
- core 사이즈 만큼 있으면 작업을 큐에 보관을 시도함
- 큐에도 작업이 가득 차면 대기하는 작업이 꽉 찰 정도로 요청이 많다는 의미로 긴급 상황이 됨
- 이 경우에 Executor가 max(maximumPoolSize)까지 초과 스레드를 만들어서 작업을 수행하여 ThreadPoolExecutor를 생성할 때 core를 2, max를 4로 지정했으므로 초과 스레드를 2개 더 만들 수 있음
- Executor가 초과 스레드인 스레드 3을 만들고 task5 작업을 바로 처리하며 이 경우에는 큐가 가득 찼기 때문에 작업을 큐에 넣는 것도 불가능함
- 그래서 실행 결과를 보면 먼저 들어온 task3, task4는 큐에 보관되어 있는 반면 task5는 초과 스레드가 작업을 받아서 바로 수행됨


16:07:11.830 [ main] task6 -> [pool=4, active=4, queuedTasks=2, completedTasks=0]
16:07:11.830 [pool-1-thread-4] task6 시작
16:07:11.830 [ main] task7 실행 거절 예외 발생: java.util.concurrent.RejectedExecutionException:
Task thread.executor.RunnableTask@67424e82 rejected from java.util.concurrent.ThreadPoolExecutor@2f4d3709
[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]- task6 작업이 요청이 오면 아직 스레드 풀도 가득 차있고 작업 큐도 가득 차있기 때문에 긴급상황으로 초과 스레드를 생성하여 바로 작업을 처리함
- 여기서 task7 작업이 요청이 들어오면, 큐도 가득 찼고, 스레드 풀도 max 사이즈만큼 가득 찼기 때문에 더 이상 작업을 처리할 수 없으므로 RejectedExecutionException이 발생함
- 즉, 큐도 가득 차서 작업을 보관할 수도 없고 스레드 풀도 max만큼 스레드 수가 가득 찼기 때문에 작업을 거절하게 됨
(2) 작업 수행



16:07:12.830 [pool-1-thread-1] task1 완료
16:07:12.831 [pool-1-thread-1] task3 시작
16:07:12.834 [pool-1-thread-2] task2 완료
16:07:12.835 [pool-1-thread-3] task5 완료
16:07:12.835 [pool-1-thread-2] task4 시작
16:07:12.835 [pool-1-thread-4] task6 완료
16:07:13.834 [pool-1-thread-1] task3 완료
16:07:13.841 [pool-1-thread-2] task4 완료- 작업들이 순차적으로 수행되며 작업을 완료하면 스레드 풀에 복귀하여 큐에 남아있는 작업을 다시 꺼내서 수행함
- 작업 결과를 보면 대기 큐에 보관된 task3, task4가 초과 스레드가 작업을 수행한 task5, task6보다 늦게 완료되는 것을 확인할 수 있음
(3) 작업 수행 완료



16:07:14.836 [ main] == 작업 수행 완료 ==
16:07:14.839 [ main] [pool=4, active=0, queuedTasks=0, completedTasks=6]
16:07:17.845 [ main] == maximumPooSize 대기 시간 초과 ==
16:07:17.845 [ main] [pool=2, active=0, queuedTasks=0, completedTasks=6]
16:07:17.847 [ main] == shutdown 완료 ==
16:07:17.848 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=6]- 모든 작업이 완료되면 스레드 풀에 스레드들이 모두 대기함
- 스레드 3과 스레드 4와 같은 초과 스레드들은 지정된 시간까지 작업을 하지 않고 대기하면 제거됨
- ThreadPoolExecutor 생성 시 3초로 지정하였으므로 3초간 아무 작업이 없을 경우 스레드 풀에서 제거되며 만약 이 사이에 작업을 처리하게 되면 시간은 계속 초기화됨
- 작업 요청이 계속 들어온다면 긴급한 상황이 끝난 것이 아니기 때문에 긴급한 상황이 끝날 때까지 초과 스레드를 살려두어야 많은 스레드를 사용하여 작업을 더 빨리 처낼 수 있기 때문임
- 3초가 지나서 초과 스레드가 제거되고 이후 shutdown()이 진행되면 스레드 풀의 스레드가 모두 제거됨
(4) 정리 - Executor 스레드 풀 관리
- 작업을 요청하면 core 사이즈만큼 스레드를 만듦
- core 사이즈를 초과하면 큐에 작업을 넣음
- 큐를 초과하면 max 사이즈 만큼 스레드를 만들고 임시로 사용되는 초과 스레드가 생성되며 큐가 가득 차서 큐에 작업을 넣을 수 없으므로 생성된 초과 스레드가 작업을 바로 수행함
- max 사이즈를 초과하면 큐도 가득 차고 풀에 최대 생성 가능한 스레드 수도 가득 찬 것이므로 요청을 거절하며 예외가 발생함
(5) PrestartPoolMain - 스레드 미리 생성하기
- 응답시간이 아주 중요한 서버라면, 서버가 고객의 처음 요청을 받기 전에 스레드를 스레드 풀에 미리 생성해두고 싶을 수 있음
- 스레드를 미리 생성해 두면 처음 요청에서 사용되는 스레드의 생성 시간을 줄일 수 있음
- ThreadPoolExecutor.prestartAllCoreThreads()를 사용하면 기본 스레드를 미리 생성할 수 있음
- ExecutorService는 이 메서드를 제공하지 않음
package thread.executor;
public class PrestartPoolMain {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(1000);
printState(es);
ThreadPoolExecutor poolExecutor = (ThreadPoolExecutor) es;
poolExecutor.prestartAllCoreThreads();
printState(es);
}
}
/* 실행 결과
17:08:09.192 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
17:08:09.238 [ main] [pool=1000, active=0, queuedTasks=0, completedTasks=0]
*/3. Executor 전략
1) 고정 풀 전략
(1) newSingleThreadPool() - 단일 스레드 풀 전략
new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())- 스레드 풀에 기본 스레드 1개만 사용하며 큐 사이즈에 제한이 없음
- 주로 간단히 사용하거나 테스트 용도로 사용함
(2-1) newFixedThreadPool(nThreads) - 고정 풀 전략
new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())- 스레드 풀에 nThreads만큼의 기본 스레드를 생성하고 초과 스레드는 생성하지 않음
- 마찬가지로 큐 사이즈에 제한이 없으며 스레드 수가 고정되어 있으므로 CPU, 메모리 리소스가 어느 정도 예측 가능한 안정적인 방식임
(2-2) PoolSizeMainV2
- 2개의 스레드가 안정적으로 작업을 처리하는 것을 확인할 수 있음
- 특징
- 스레드 수가 고정되어 있기 때문에 CPU, 메모리 리소스가 어느정도 예측 가능하기 때문에 일반적인 상황에서 가장 안정적으로 서비스를 운영할 수 있음
- 큐 사이즈도 제한이 없어서 작업을 많이 담아두어도 문제가 없음
package thread.executor.poolsize;
public class PoolSizeMainV2 {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(2);
log("pool 생성");
printState(es);
for (int i = 1; i <= 6; i++) {
String taskName = "task" + i;
es.execute(new RunnableTask(taskName));
printState(es);
}
es.close();
log("== shutdown ==");
}
}
/* 실행 결과
17:20:28.636 [ main] pool 생성
17:20:28.645 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
17:20:28.647 [ main] [pool=1, active=1, queuedTasks=0, completedTasks=0]
17:20:28.647 [ main] [pool=2, active=2, queuedTasks=0, completedTasks=0]
17:20:28.647 [pool-1-thread-1] task1 시작
17:20:28.647 [pool-1-thread-2] task2 시작
17:20:28.647 [ main] [pool=2, active=2, queuedTasks=1, completedTasks=0]
17:20:28.648 [ main] [pool=2, active=2, queuedTasks=2, completedTasks=0]
17:20:28.648 [ main] [pool=2, active=2, queuedTasks=3, completedTasks=0]
17:20:28.648 [ main] [pool=2, active=2, queuedTasks=4, completedTasks=0]
17:20:29.654 [pool-1-thread-1] task1 완료
17:20:29.656 [pool-1-thread-1] task3 시작
17:20:29.656 [pool-1-thread-2] task2 완료
17:20:29.658 [pool-1-thread-2] task4 시작
17:20:30.662 [pool-1-thread-1] task3 완료
17:20:30.663 [pool-1-thread-1] task5 시작
17:20:30.664 [pool-1-thread-2] task4 완료
17:20:30.664 [pool-1-thread-2] task6 시작
17:20:31.667 [pool-1-thread-2] task6 완료
17:20:31.670 [pool-1-thread-1] task5 완료
17:20:31.672 [ main] == shutdown ==
*/
(2-3) 주의
- 하지만 상황에 따라 장점이 가장 큰 단점이 되기도 하는데 서버 자원은 여유가 있는데 사용자만 점점 느려지는 문제가 발생할 수 있게 됨
- 상황1 - 점진적인 사용자 확대
- 개발한 서비스가 잘 되어서 사용자가 점점 늘어남
- 고정 스레드 전략을 사용하여 서비스를 안정적으로 잘 운영했는데 언젠가부터 사용자들이 서비스 응답이 점점 느려진다고 항의가 옴
- 상황2 - 갑작스런 요청 증가
- 마케팅 팀의 이벤트가 대성공하면서 사용자가 폭증하였음
- 그러나 고객이 응답을 받지 못한다고 항의가 옴
- 확인
- 위의 상황에서 CPU, 메모리 사용량을 확인해 보면 아무런 문제 없이 여유 있고 안정적으로 서비스가 운영되고 있음
- 고정 스레드 전략은 실행되는 스레드 수가 고정되어 있으므로 사용자가 늘어나도 CPU, 메모리 사용량이 확 늘어나지 않음
- 고정 풀 전략의 큐 사이즈는 무한이기 때문에 큐에는 요청이 계속 쌓이는데 요청이 처리되는 시간보다 쌓이는 시간이 더 빠르기 때문에 문제가 발생한 것임
- 큐에 10,000건이 쌓여있는데 고정 스레드 수가 10이고 각 스레드가 작업을 하나 처리하는데 1초가 걸린다면 모든 작업을 다 처리하는 데는 1,000초가 걸리게 되며 처리 속도보다 작업이 쌓이는 속도가 더 빠른 경우는 문제가 더 커짐
- 서비스 초기에는 사용자가 적기 때문에 이런 문제가 없지만 사용자가 늘어나면 문제가 될 수 있으며 갑작스러운 요청 증가도 마찬가지임
2) 캐시 풀 전략
(1) newCachedThreadPool() - 캐시 풀 전략
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());- 기본 스레드를 사용하지 않고 60초 생존 주기를 가진 초과 스레드만 사용함
- 초과 스레드의 수는 제한이 없으며 큐에 작업을 저장하지 않는 대신 생산자의 요청을 스레드 풀의 소비자 스레드가 직접 받아서 바로 처리함(SynchronousQueue)
- 모든 요청이 대기하지 않고 스레드가 바로바로 처리하여 빠른 처리가 가능함
(2) SynchronousQueue, 특별한 블로킹 큐
- BlockingQueue 인터페이스의 구현체 중 하나임
- 내부에 저장 공간이 없는 대신에 생산자의 작업을 소비자 스레드에게 직접 전달함
- 이름 그대로 생산자와 소비자를 동기화하는 큐이며 중간에 버퍼를 두지 않고 생산자 스레드와 소비자 스레드 간의 작업을 직접 주고받는 방식이라고 생각하면 됨
(3) PoolSizeMainV3
- 스레드가 제거되는 것을 확인하기 위해 스레드 생존 주기를 기본 60초에서 3초로 줄여서 작성
- 실행 결과를 보면 모든 작업이 대기하지 않고 작업의 수만큼 스레드가 생기면서 바로 실행되는 것을 확인할 수 있음
- "maximumPoolSize 대기 시간 초과" 로그를 통해 초과 스레드가 대기 시간이 지나면 모두 사라지는 것도 확인할 수 있음
- 특징
- 캐시 스레드 풀 전략은 매우 빠르고 유연한 전략임
- 이 전략은 기본 스레드도 없고 대기 큐에 작업도 쌓이지 않는 대신에 작업 요청이 오면 초과 스레드로 작업을 바로바로 처리하기 때문에 빠른 처리가 가능함
- 초과 스레드의 수도 제한이 없기 때문에 CPU, 메모리 자원만 허용한다면 시스템의 자원을 최대로 사용할 수 있음
- 추가로 초과 스레드는 60초간 생존하기 때문에 작업 수에 맞추어 적절한 수의 스레드가 재사용이 됨
- 이런 특징 때문에 요청이 갑자기 증가하면 스레드도 갑자기 증가하고 요청이 줄어들면 스레드도 점점 줄어들어 매우 유연한 전략임
- Executor 스레드 풀 관리
- 기본 스레드 없이 초과 스레드만 만들 수 있는 이유는 Executor 스레드 풀 기본 관리 정책을 보면 알 수 있음
- 작업을 요청하면 core 사이즈만큼 스레드를 만듦 -> core 사이즈가 없으므로 바로 core 사이즈를 초과함
- core 사이즈를 초과하면 큐에 작업을 넣어야 함 -> SynchronousQueue를 사용하기 때문에 큐에 작업을 넣을 수 없음
- 큐를 초과하면 max 사이즈만큼 임시로 사용되는 초과 스레드가 생성됨 -> 초과 스레드가 생성되며 풀에 대기하는 초과 스레드가 있으면 재사용됨
- max 사이즈를 초과하면 요청을 거절하며 예외를 발생시킴 -> max 사이즈가 무제한이라서 초과 스레드를 무제한으로 만들 수 있음
package thread.executor.poolsize;
public class PoolSizeMainV3 {
public static void main(String[] args) {
// ExecutorService es = Executors.newCachedThreadPool();
// 스레드 생존 주기를 60초 -> 3초로 조절
ThreadPoolExecutor es = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 3,
TimeUnit.SECONDS, new SynchronousQueue<>());
log("pool 생성");
printState(es);
for (int i = 1; i <= 6; i++) {
String taskName = "task" + i;
es.execute(new RunnableTask(taskName));
printState(es, taskName);
}
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
sleep(3000);
log("== maximumPooSize 대기 시간 초과 ==");
printState(es);
es.close();
log("== shutdown ==");
}
}
/* 실행 결과
17:49:17.820 [ main] pool 생성
17:49:17.830 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
17:49:17.832 [pool-1-thread-1] task1 시작
17:49:17.837 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]
17:49:17.837 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
17:49:17.837 [pool-1-thread-2] task2 시작
17:49:17.837 [ main] task3 -> [pool=3, active=3, queuedTasks=0, completedTasks=0]
17:49:17.837 [pool-1-thread-3] task3 시작
17:49:17.838 [ main] task4 -> [pool=4, active=4, queuedTasks=0, completedTasks=0]
17:49:17.838 [pool-1-thread-4] task4 시작
17:49:17.838 [pool-1-thread-5] task5 시작
17:49:17.838 [ main] task5 -> [pool=5, active=5, queuedTasks=0, completedTasks=0]
17:49:17.838 [ main] task6 -> [pool=6, active=6, queuedTasks=0, completedTasks=0]
17:49:17.838 [pool-1-thread-6] task6 시작
17:49:18.839 [pool-1-thread-1] task1 완료
17:49:18.843 [pool-1-thread-5] task5 완료
17:49:18.843 [pool-1-thread-3] task3 완료
17:49:18.843 [pool-1-thread-2] task2 완료
17:49:18.844 [pool-1-thread-4] task4 완료
17:49:18.844 [pool-1-thread-6] task6 완료
17:49:20.843 [ main] == 작업 수행 완료 ==
17:49:20.845 [ main] [pool=6, active=0, queuedTasks=0, completedTasks=6]
17:49:23.849 [ main] == maximumPooSize 대기 시간 초과 ==
17:49:23.850 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=6]
17:49:23.855 [ main] == shutdown ==
*/
(4) 주의
- 캐시 스레드 풀 전략은 매우 유연하게 동작하는 것이 큰 장점이지만 특정 상황에서는 단점이 될 수 있는데 서버의 자원을 최대한 사용하지만 서버가 감당할 수 있는 임계점을 넘는 순간 시스템이 다운될 수 있는 문제가 발생할 수 있음
- 상황1 - 점진적인 사용자 확대
- 개발한 서비스가 잘되어서 사용자가 점점 늘어나는 경우에는 캐시 스레드 전략을 사용할 경우 모니터링을 하고 있다면 문제를 빠르게 찾을 수 있기 때문에 크게 문제가 되지 않음
- 사용자가 점점 증가하면서 스레드 사용량도 함께 늘어나고 따라서 CPU 메모리의 사용량도 자연스럽게 증가함
- CPU, 메모리 자원은 한계가 있기 때문에 모니터링을 통해 적절한 시점에 시스템을 증설해야 함
- 만약 모니터링을 소홀히 하고 있다면 CPU, 메모리 같은 시스템 자원을 너무 많이 사용하면서 시스템이 다운될 수 있음
- 상황2 - 갑작스런 요청 증가
- 마케팅 팀의 이벤트가 대성공하면서 사용자가 폭증하였음
- 그러나 고객이 응답을 받지 못한다고 항의가 옴
- 상황2 - 확인
- CPU, 메모리 사용량을 확인해 보면 CPU 사용량이 100%이고 메모리 사용량도 지나치게 높아져있으며 스레드 수를 확인해보면 스레드가 수 천 개 실행되고 있는 상황을 마주할 수 있음
- 캐시 스레드 풀 전략은 스레드가 무한으로 생성될 수 있기 때문에 너무 많은 스레드가 작업을 처리하면서 시스템 전체가 느려지는 현상이 발생할 수 있음
- 만약 스레드가 처리하는 속도보다 더 많은 작업이 들어오게 되면 시스템은 너무 많은 스레드에 잠식당해서 메모리도 거의 다 사용되어 버리고 결국 시스템이 멈추는 장애가 발생하게 됨
3) 사용자 정의 풀 전략
(1) 세분화된 전략
- 세분화된 전략을 사용하면 앞서 문제가 되었던 상황1, 상황2를 모두 어느 정도 대응할 수 있음
- 일반: 일반적인 상황에는 CPU, 메모리 자원을 예측할 수 있도록 고정 크기의 스레드로 서비스를 안정적으로 운영
- 긴급: 사용자의 요청이 갑자기 증가하면 긴급하게 스레드를 추가로 투입해서 작업을 빠르게 처리함
- 거절: 사용자의 요청이 폭증해서 긴급 대응도 어렵다면 사용자의 요청을 거절함
- 이 방법은 평소에는 안정적으로 운영하다가 사용자의 요청이 갑자기 증가하면 긴급하게 스레드를 더 투입해서 급한 불을 끄는 방법으로 긴급 상황에서는 CPU, 메모리 자원을 더 사용하기 때문에 적정 수준을 찾아야 함
- 시스템이 감당할 수 없을 정도로 사용자의 요청이 폭증하면 처리 가능한 수준의 사용자 요청만 처리하고 나머지 요청을 거절하도록 하여 어떤 경우에도 시스템이 다운되는 최악의상황은 피해야 함
ExecutorService es = new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000));- 세분화된 전략을 사용하여 ThreadPoolExecutor를 생성할 경우 위의 예시처럼 적용할 수 있음
- 100개의 기본 스레드를 사용하고 추가로 긴급 대응 가능한 초과 스레드를 100개를 사용
- 초과 스레드는 60초의 생존 주기를 가짐
- ArrayBlockingQueue를 사용하여 1000개의 작업이 큐에 대기할 수 있도록 작성
(2) PoolSizeMainV4
- 세분화된 전략을 사용하고 TASK_SIZE를 조정하면서 실행하여 일반 상황, 긴급 상황, 거절 상황을 구현
- RunnableTask는 작업을 처리하는데 1초가 걸림
- 일반: 1000개의 이하의 작업이 큐에 담겨있음 -> 100개의 기본 스레드가 처리하여 약 11초가 걸림
- 긴급: 큐에 담긴 작업이 1000개를 초과함 -> 100개의 기본 스레드와 100개의 초과 스레드가 처리하여 약, 6초가 걸림
- 거절: 초과 스레드를 투입 했지만 큐에 담긴 작업 1000개를 초과하고 초과 스레드도 넘어간 상황이므로 1201번에서 예외를 발생시키고 나머지는 긴급 상황과 같이 처리됨
package thread.executor.poolsize;
public class PoolSizeMainV4 {
static final int TASK_SIZE = 1100; // 1. 일반
// static final int TASK_SIZE = 1200; // 2. 긴급
// static final int TASK_SIZE = 1201; // 3. 거절
public static void main(String[] args) {
ExecutorService es = new ThreadPoolExecutor(100, 200, 60,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000));
printState(es);
long startMs = System.currentTimeMillis();
for (int i = 1; i <= TASK_SIZE; i++) {
String taskName = "task" + i;
try {
es.execute(new RunnableTask(taskName));
printState(es, taskName);
} catch (RejectedExecutionException e) {
log(taskName + " -> " + e);
}
}
es.close();
long endTime = System.currentTimeMillis();
log("time: " + (endTime - startMs));
}
}
(3) 일반 - TASK_SIZE = 1100
...
18:52:24.633 [ main] task1100 -> [pool=100, active=100, queuedTasks=1000, completedTasks=0]
18:52:25.587 [pool-1-thread-4] task4 완료
...
18:52:35.668 [ main] time: 11088- 1000개의 이하의 작업이 큐에 담겨있으므로 100개의 기본 스레드가 작업을 처리함
- 최대 1000개의 작업이 큐에 대기하고 100개의 작업이 실행중일 수 있으므로 1100개 까지는 기본 스레드로 처리가 가능함
- 1초가 걸리는 작업이 1100개 있으므로 약 11초 후에 작업이 종료되는 것을 확인할 수 있음
(4) 긴급 - TASK_SIZE = 1200
...
18:55:04.292 [ main] task1100 -> [pool=100, active=100, queuedTasks=1000, completedTasks=0]
...
18:55:04.301 [ main] task1200 -> [pool=200, active=200, queuedTasks=1000, completedTasks=0]
...
18:55:10.326 [ main] time: 6090- 큐에 담긴 작업이 1000개를 초과하여 100개의 기본 스레드에 100개의 초과 스레드가 생성되어 처리함
- 긴급 투입한 스레드 덕분에 풀의 스레드 수가 2배가 되어 작업을 2배 빠르게 처리할 수 있게 됨
- 1200개의 작업을 6초 만에 작업이 종료되는 것을 확인할 수 있음
- 물론 CPU, 메모리 사용을 더 하기 때문에 이런 부분은 감안해서 긴급 상황에 투입할 최대 스레드를 정해야 함
(5) 거절 - TASK_SIZE = 1201
...
18:56:39.374 [ main] task1200 -> [pool=200, active=200, queuedTasks=1000, completedTasks=0]
18:56:39.374 [pool-1-thread-200] task1200 시작
18:56:39.376 [ main] task1201 -> java.util.concurrent.RejectedExecutionException:
Task thread.executor.RunnableTask@5c8da962 rejected from java.util.concurrent.ThreadPoolExecutor@2f4d3709
[Running, pool size = 200, active threads = 200, queued tasks = 1000, completed tasks = 0]
...
18:56:45.405 [ main] time: 6095- 중간의 task1201 예외 로그를 확인할 수 있음
- 긴급 투입한 스레드로도 작업이 빠르게 소모되지 않는다는 것은 시스템이 감당하기 어려운 많은 요청이 들어오고 있다는 의미임
- 여기서는 큐에 대기하는 작업 1000개와 스레드가 처리 중인 작업 200개를 초과하면 예외가 발생하므로 1201번 작업에서 예외가 발생한 것을 확인할 수 있음
- 이런 경우에는 요청을 거절하고 고객 서비스라면 시스템에 사용자가 너무 많으니 나중에 다시 시도해 달라고 하는 것이 좋으며 나머지 1200개의 작업들은 긴급 상황과 같이 정상 처리 됨
(6) 자주 하는 실수
new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new LinkedBlockingQueue());- 큐를 LinkedBlockingQueue()로 적용하는 실수를 많이 하는데 이렇게 설정하면 큐의 사이즈가 무한대의 사이즈로 늘어날 수 있기 때문에 큐가 가득 찰 수 없으므로 절대로 최대 사이즈만큼 늘어날 수가 없음
- 결국 기본 스레드 100개 만으로 무한대의 작업을 처리해야 하는 문제가 발생하게 됨
4. Executor 예외 정책
1) 예외 정책
(1) 다양한 거절 정책
- 생산자 소비자 문제를 실무에서 사용할 때는 결국 소비자가 처리할 수 없을 정도로 생산 요청이 가득 차면 어떻게 할지를 정해야 함
- 개발자가 인지할 수 있게 로그도 남겨야 하고 사용자에게 현재 시스템에 문제가 있다고 알리는 것도 필요한데 이런 것을 위해 예외 정책이 필요함
- ThreadPoolExecutor는 작업을 거절하는 다양한 정책을 제공함
- AbortPolicy: 새로운 작업을 제출할 때 RejectedExecutionException을 발생시키며 기본 정책임
- DiscardPolicy: 새로운 작업을 조용히 버림
- CallerRunsPolicy: 새로운 작업을 제출한 스레드가 대신해서 직접 작업을 실행함
- 사용자 정의(RejectedExecutionHandler): 개발자가 직접 정의한 거절 정책을 사용할 수 있음
- 참고로 ThreadPoolExecutor를 shutdown()하면 이후에 요청하는 작업을 거절하는데 이때도 같은 정책이 적용됨
(2) RejectMainV1 - AbortPolicy
- 작업이 거절되면 RejectedExecutionException을 던지며 기본적으로 설정되어 있는 정책임
- ThreadPoolExecutor 생성자 마지막에 new ThreadPoolExecutor.AbortPolicy()를 제공하면 되며 기본 정책이기 때문에 생략해도 됨
- 스레드를 1개만 사용하여 큐에 작업을 넣지 않도록 SynchronousQueue를 사용하고 실행해 보면 RejectedExecutionException 예외가 발생하는 것을 확인할 수 있음
- 발생한 예외를 잡아서 작업을 포기하거나 사용자에게 알리는 등의 필요한 코드를 직접 구현해도 되고 다른 정책들을 사용해도 됨
package thread.executor.reject;
public class RejectMainV1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.AbortPolicy());
executor.execute(new RunnableTask("task1"));
try {
executor.submit(new RunnableTask("task2"));
} catch (RejectedExecutionException e) {
log("요청 초과");
// 포기, 다시 시도 등 다양한 고민을 하여 적용하면 됨
log(e);
}
executor.close();
}
}
/* 실행 결과
19:14:43.804 [ main] 요청 초과
19:14:43.803 [pool-1-thread-1] task1 시작
19:14:43.805 [ main] java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@3941a79c[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@7530d0a[Wrapped task = thread.executor.RunnableTask@27bc2616]] rejected from java.util.concurrent.ThreadPoolExecutor@7291c18f[Running, pool size = 1, active threads = 1, queued tasks = 0, completed tasks = 0]
19:14:44.811 [pool-1-thread-1] task1 완료
*/
(3) RejectedExecutionHandler
- 마지막에 전달한 AbortPolicy는 RejectedExecutionHandler의 구현체로 ThreadPoolExecutor 생성자는 RejectedExecutionHandler의 구현체를 전달받음
- ThreadPoolExecutor는 거절해야 하는 상황이 발생하면 여기에 있는 rejectedExecution()을 호출함
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
(4) RejectMainV2 - DiscardPolicy
- 거절된 작업을 무시하고 아무런 예외도 발생시키지 않음
- ThreadPoolExecutor 생성자 마지막에 DiscardPolicy()를 제공하면 성공한 태스크를 제외한 나머지 태스크는 실행이 안 되는 것을 확인할 수 있음
- DiscardPolicy 내부에 들어가 보면 왜 조용히 버리는 정책인지 이해가 가는데 rejectedExecution() 메서드가 비어있음
package thread.executor.reject;
public class RejectMainV2 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.DiscardPolicy());
executor.execute(new RunnableTask("task1"));
executor.execute(new RunnableTask("task2"));
executor.execute(new RunnableTask("task3"));
executor.execute(new RunnableTask("task4"));
executor.execute(new RunnableTask("task5"));
executor.close();
}
}
/* 실행 결과
10:51:31.226 [pool-1-thread-1] task1 시작
10:51:32.233 [pool-1-thread-1] task1 완료
*/
// DiscardPolicy 내부 구조
public static class DiscardPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
(5) RejectMainV3 - CallerRunsPolicy
- 호출한 스레드가 직접 작업을 수행하며 이로 인해 새로운 작업을 제출하는 스레드의 속도가 느려질 수 있음
- 이 정책은 스레드 풀에 보관할 큐도 없고 작업할 스레드가 없으면 작업을 요청한 스레드가 대신 작업을 수행하여 실행 결과를 보면 main스레드가 작업 스레드와 번갈아가면서 작업을 수행하는 것을 확인할 수 있음
- 이 정책의 특징은 생산자 스레드가 소비자 스레드 대신 일을 수행하는 것도 있지만 생산자 스레드가 대신 일을 수행하는 덕분에 작업의 생산 자체가 느려진다는 점임
- 즉, 작업의 생산 속도가 너무 빠르다면 생산 속도를 조절할 수 있다는 것인데, 원래대로 실행된다면 main스레드가 작업들을 멈추지 않고 task1 ~ task5 연속해서 바로 생산해야 함
- 그러나 CallerRunsPolicy 정책 덕분에 main 스레드는 본인이 직접 작업을 완료하고 나서야 다음 작업을 생산할 수 있으므로 결과적으로 생산 속도가 조절됨
- CallerRunsPolicy의 rejectedExecution 메서드를 보면 r.run()으로 요청한 스레드가 작업을 직접 수행하는 것을 알 수 있음
- 참고로 ThreadPoolExecutor를 shutdown()을 하면 이후에 요청하는 작업을 거절하는데 이때도 같은 정책이 적용되지만 CallerRunsPolicy 정책은 shutdown() 이후에도 작업을 수행하기 때문에 조건을 체크해서 작업을 수행하지 않도록 되어있음
package thread.executor.reject;
public class RejectMainV3 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
executor.execute(new RunnableTask("task1"));
executor.execute(new RunnableTask("task2"));
executor.execute(new RunnableTask("task3"));
executor.execute(new RunnableTask("task4"));
executor.execute(new RunnableTask("task5"));
executor.close();
}
}
/* 실행 결과
12:04:12.275 [ main] task2 시작
12:04:12.275 [pool-1-thread-1] task1 시작
12:04:13.288 [pool-1-thread-1] task1 완료
12:04:13.288 [ main] task2 완료
12:04:13.292 [ main] task4 시작
12:04:13.292 [pool-1-thread-1] task3 시작
12:04:14.297 [ main] task4 완료
12:04:14.299 [ main] task5 시작
12:04:14.298 [pool-1-thread-1] task3 완료
12:04:15.303 [ main] task5 완료
*/
// CallerRunsPolicy 구조
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
(6) RejectMainV5 - 사용자 정의
- 사용자 정의(RejectedExecutionHandler): 사용자는 RejectedExecutionHandler 인터페이스를 구현하여 자신만의 거절 처리 전략을 정의할 수 있어 이를 통해 특정 요구사항에 맞는 작업 거절 방식을 설정할 수 있음
- RejectedExecutionHandler를 직접 구현하여 거절된 작업을 버리지만 경고 로그를 남겨서 문제를 인지할 수 있는 거절 정책을 만들어서 실행해 보면 거절된 기대하는 바와 같이 거절된 작업이 실행되는 것을 확인할 수 있음
package thread.executor.reject;
public class RejectMainV4 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS, new SynchronousQueue<>(), new MyRejectedExecutionHandler());
executor.execute(new RunnableTask("task1"));
executor.execute(new RunnableTask("task2"));
executor.execute(new RunnableTask("task3"));
executor.close();
}
static class MyRejectedExecutionHandler implements RejectedExecutionHandler {
static AtomicInteger count = new AtomicInteger();
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
int i = count.incrementAndGet();
log("[경고] 거절된 누적 작업 수: " + i);
}
}
}
/* 실행 결과
12:17:32.479 [pool-1-thread-1] task1 시작
12:17:32.479 [ main] [경고] 거절된 누적 작업 수: 1
12:17:32.481 [ main] [경고] 거절된 누적 작업 수: 2
12:17:33.487 [pool-1-thread-1] task1 완료
*/2) 정리
(1) 실무 전략 선택
- 고정 스레드 풀 전략: 트래픽이 일정하고, 시스템 안전성이 가장 중요
- 캐시 스레드 풀 전략: 일반적인 성장하는 서비스
- 사용자 정의 풀 전략: 다양한 상황에 대응
(2) 가장 좋은 최적화는 최적화하지 않는 것임
- 많은 개발자가 미래에 발생하지 않을 일 때문에 코드를 최적화하는 경우가 많음
- 예를 들어 초기 서비스이고 아직 사용자가 많을지 예측이 되지 않은 상황인데 코드 최적화에 너무 많은 시간을 사용하게 되면 사용자는 얼마 없는데 매우 비싼 서버를 구매하는 것과 같음
- 극단적으로 최적화를 하지 말자는 이야기가 아니라 중요한 것은 예측 불가능한 너무 먼 미래보다는 현재 상황에 맞는 최적화가 필요하다는 점임
- 예를 들어서 A와 관련된 기능을 매우 많이 최적화했는데 사용자가 없어서 결국 버리게 되는 경우도 있는 반면 별로 신경 쓰지 않았던 B와 관련된 기능에 사용자가 많이 늘어날 수도 있음
- 결국 가장 좋은 방법은 시스템의 상황을 잘 모니터링하고 있다가 최적화가 필요한 부분들이 발생하면 그때 필요한 부분들을 개선하는 것임
- 우리가 만든 서비스가 잘 되어서 많은 요청이 들어오면 좋겠지만 대부분의 서비스는 트래픽이 어느 정도 예측이 가능하며 성장하는 서비스라도 어느정도 성장이 예측이 가능함
- 그래서 일반적인 상황이라면 고정 스레드 풀 전략이나 캐시 스레드 풀 전략을 사용하면 충분함
- 한 번에 처리할 수 있는 수를 제한하고 안정적으로 처리하고 싶다면 고정 풀 전략을, 사용자의 요청을 빠르게 대응하고 싶다면 캐시 스레드 풀 전략을 사용하면 됨
- 자원만 충분하다면 고정 풀 전략을 선택하면서 풀의 수를 많이 늘려서 사용자의 요청도 빠르게 대응하면서 안정적인 서비스 운영도 가능하므로 일반적인 상황을 벗어날 정도로 서비스가 잘 운영되면 그때 더 나은 최적화 방법을 선택하면 됨
- 백엔드 서버 개발자라면 시스템의 자원을 적절하게 활용하되 최악의 경우 적절한 거절을 통해 절대로 시스템이 다운되지 않도록 해야 함
- 적절한 거절은 서버에도 우리의 삶에도 모두 필요함



