
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 자바의 정석 기초편 ch14
- 자바의 정석 기초편 ch1
- 자바의 정석 기초편 ch9
- 스프링 트랜잭션
- 자바의 정석 기초편 ch12
- 자바의 정석 기초편 ch7
- 스프링 mvc2 - 로그인 처리
- 자바 고급2편 - io
- 스프링 입문(무료)
- 스프링 고급 - 스프링 aop
- 자바 중급2편 - 컬렉션 프레임워크
- 자바 고급2편 - 네트워크 프로그램
- 스프링 mvc1 - 스프링 mvc
- 데이터 접근 기술
- 스프링 mvc2 - 타임리프
- 자바로 계산기 만들기
- 자바 중급1편 - 날짜와 시간
- 자바의 정석 기초편 ch6
- 2024 정보처리기사 시나공 필기
- 자바 기초
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch4
- 자바의 정석 기초편 ch13
- @Aspect
- 자바로 키오스크 만들기
- 스프링 mvc2 - 검증
- 람다
- 자바의 정석 기초편 ch2
- 2024 정보처리기사 수제비 실기
Archives
- Today
- Total
개발공부기록
Java - 체육복, 문자열 나누기, 대충 만든 자판, 둘만의 암호, 햄버거 만들기, 성격 유형 검사하기, 바탕화면 정리 본문
기타 개발 공부/온라인 코딩 테스트 회고
Java - 체육복, 문자열 나누기, 대충 만든 자판, 둘만의 암호, 햄버거 만들기, 성격 유형 검사하기, 바탕화면 정리
소소한나구리 2025. 4. 17. 12:22728x90
Java - 이번 글의 문제들은 모두 끝까지 풀지 못했음
체육복
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/42862
- 도난당한 체육복을 여벌 체육복이 있는 학생이 체육복을 빌려주려함
- 학생들의 번호는 체격 순으로 매겨져 있어 바로 앞본호의 학생이나 바로 뒷 버놓의 학생에게만 체육복을 빌려줄 수 있음
- 4번 학생은 3번 학생이나 5번 학생에게만 체육복을 빌려 줄 수 있음
- 체육복이 없으면 수업을 들을 수 없기 때문에 체육복을 적절히 빌려 최대한 많은 학생이 체육 수업을 들어야 함
- 전체 학생 수 n, 체육복을 도난당한 학생들의 번호가 담긴 배열 lost, 여벌의 체육복을 가져온 학생들의 번호가 담긴 배열 reserve가 매개변수로 주어질 때 체육수업을 들을 수 있는 학생의 최댓값을 return 하도록 solution 함수를 작성
제한조건
- 전체 학생의 수는 2명 이상 30명 이하
- 체육복을 도난당한 학생의 수는 1명 이상 n명 이하이고 중복되는 번호는 없음
- 여벌의 체육복을 가져온 학생의 수는 1명 이상 n명이하이고 중복되는 번호는 없음
- 여별 체육복이 있는 학생만 다른 학생에게 체육복을 빌려줄 수 있음
- 여벌 체육복을 가져온 학새이 체육복을 도난당했을 수 있으며 이 학생은 체육복을 하나만 도난당했다고 가정하며 남은 체육복이 하나이기에 다른 학생에게는 체육복을 빌려줄 수 없음
입출력 예시

풀이
class Solution {
public int solution(int n, int[] lost, int[] reserve) {
int[] students = new int [n];
int count = n;
for (int l : lost) {
students[l - 1]--;
}
for (int r : reserve) {
students[r - 1]++;
}
for (int i = 0; i < n; i++) {
if (students[i] == -1) {
if (i - 1 >= 0 && students[i - 1] == 1) {
students[i - 1]--;
students[i]++;
} else if (i + 1 < n && students[i + 1] == 1) {
students[i + 1]--;
students[i]++;
} else {
count--;
}
}
}
return count;
}
}- 처음에는 어떻게 접근해야할지 몰라 각 학생의 번호를 중복되지 않기 위해 Set 자료구조를 사용도해보고했지만 결국 올바른 접근 방법을 30분동안 찾지 못해서 결과지를 보면서 접근 방법을 터득했다.
- 전체 학생수만큼 학생을 뜻하는 배열을 생성하고, count = n을 통해 모든 학생이 체육복이 있다고 가정하고 시작한다 -> 이런 방법을 처음에는 생각하지 못했다
- 다음 lost, reserve 배열을 순회해면서 체육복을 잃어버린 학생의 값은 1 감소시키고, 여벌의 체육복을 가져온 학생은 1 증가시켜서 현재 학생의 체육복 유무 상태를 초기화 시킨다.
- 즉, 체육복을 잃어버린 학생의 값은 -1이되고, 여벌의 체육복을 가진 학생의 값은 1이 된다.
- 마지막 반복문과 조건문에서는 학생의 값이 -1인 경우에만 체육복을 빌릴 수 있는지 확인하고, 체육복이 있는 경우에는 해당 조건문은 실행되지 않는다.
- 체육복이 없는 학생이 여벌의 체육복이 있는 학생번호의 앞,뒤번호여야만 체육복을 빌려줄 수 있다
- 그렇기 때문에 if문과 else if문을 통해 체육복의 잃어버린 학생의 앞, 뒤 번호인 학생이 여벌 체육복이 있다면 빌려준 학생은 1을 감소시키고 빌린 학생은 1을 증가시키는 로직을 구현한다.
- 만약 체육복을 빌리지 못햇다면 count을 1 감소시켜서 체육수업을 들을 수 있는 학생 수를 감소시킨다.
- 여기서 각 조건문에 i - 1 >= 0과 i + 1 < n의 조건이 들어가 있는데 체육복을 빌릴 때 student 배열 범위내에서만 빌려야 하므로 해당 조건이 없으면 인덱스 범위가 벗어났다는 오류가 발생한다.
- 즉, 첫 번째 학생, 마지막 학생이 체육복이 없다면 students[i - 1] == 1과 students[i + 1] == 1 조건을 실행할 때 오류가 발생하기 때문이다.
- 해당 조건을 모두 반복하면 문제를 해결할 수 있다.
문자열 나누기
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/140108
- 문자열 s가 입력되었을 때 다음 규칙을 따라서 이 문자열을 여러 문자열로 분해하려고함
- 첫 글자를 읽음 -> 읽은 글자를 x라고 칭함
- 해당 문자열을 왼쪽에서 오른쪽으로 읽어나가면서 x와 x가 아니 다른 글자들이 나온 횟수를 각각셈
- 처음으로 두 횟수가 같아지는 순간 멈추고 지금까지 읽은 문자열을 분리함
- s에서 분리한 문자열을 빼고 남은 부분에 대해서 이 과정을 반복하며 남은 부분이 없다면 종료함
- 만약 두 횟수가 다른 상태에서 더 이상 읽을 글자가 없다면 역시 지금까지 읽은 문자열을 분리하고 종료함
- 문자열 s가 매개변수로 주어질 때 위 과정과 같이 문자열들로 분해하고, 분해한 문자열의 개수를 return 하는 함수 solution을 완성함
제한조건
- 1 <= s의 길이 <= 10,000
- s는 영어 소문자로만 이루어져 있음
입출력 예시

풀이
class Solution {
public int solution(String s) {
int answer = 0;
int i = 0;
while (i < s.length()) {
char x = s.charAt(i);
int xCount = 1;
int otherCount = 0;
int j = i + 1;
while (j < s.length()) {
if (s.charAt(j) == x) {
xCount++;
} else {
otherCount++;
}
if (xCount == otherCount) {
break;
}
j++;
}
answer++;
i = j + 1;
}
return answer;
}
}- 이 문제는 s의 문자열에서 단어를 뽑아서 비교해야하기 때문에 2차원 반복문을 사용할 수 밖에 없다고 생각하고 2중 for문으로 접근했었는데, 그 과정에서 제대로된 풀이를 접근하지 못해서 시간을 초과하여 정답중 하나를 보고 공부했다.
- 먼저 첫번째 반복문으로 s문자열의 길이만큼 반복하면서 s.charAt(i)를 통해 문자를 뺌과 동시에 x의 수를 센다.
- 그 다음 x와 비교한 다른 글자의 수를 세야하는 변수 otherCount를 0으로 선언하고, 다른 문자를 세야하는 index를 j = i + 1로 선언한다.
- 이 j의 값으로 다음 반복문을 j < s.length() 만큼 돌리면 문자 x 다음 문자를 순차적으로 비교할 수 있게 된다.
- j의 값을 1씩 증가 시키면서 해당 반복문을 반복하는데 s.charAt(j)를 통해 꺼낸 문자와 x가 같다면 xCount를 증가시키고 아니라면 다른 문자가 나온 것이므로 otherCount를 증가시킨다.
- 이렇게 계속 x의 문자의 개수, x와 다른 문자의 개수를 세면서 둘의 숫자가 같아지게되면 2번째 반복을 멈추고 answer++을 증가시켜서 실제 분해를 하진않지만 분해했다고 가정하고, i의 값을 j + 1을 적용시켜서 잘라진 문자는 건너뛰도록 한다.
- 이렇게 반복문을 계속 돌아서 최종적으로 분해한 문자열의 개수를 구할 수 있게 된다
대충 만든 자판
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/160586
- 휴대폰의 자판은 키 하나에 여러 문자를 할당할 수 있는데, 동일한 키를 연속해서 빠르게 누르면 할당된 순서대로 문자가 바뀐
- 1번 키에 "A", "B", "C" 순서대로 문자가 할당되어 있다면 1번 키를 한 번 누르면 "A", 두 번 누르면 "B", 세 번 누르면 "C"가 됨
- 같은 규칙을 적용하여 아무렇게나 만든 휴대폰 자판이 있을 때 해당 휴대폰은 키의 개수가 1개부터 최대 100까지 있을 수 있으며 특정 키를 눌렀을 때 입력되는 문자들도 무작위로 배열됨
- 같은 문자가 자판 전체에 여러 번 할당된 경우도 있고, 키 하나에 같은 문자가 여러 번 할당된 경우도 있으며 아예 할당되지 않은 경우도 있기 때문에 몇몇 문자열은 작성할 수 없을 수도 있음
- 1번 키부터 차례대로 할당된 문자들이 순서대로 담긴 문자열배열 keymap과 입력하려는 문자열들이 담긴 문자열 배열 targets가 주어질 때 각 문자열을 작성하기 위해 키를 최소 몇 번씩 눌러야하는지 순서대로 배열에 담아 return 하는 함수를 완성하고 목표 문자열을 작성할 수 없을 때는 -1을 저장함
제한조건
- 1 <= keymap의 길이 <= 100
- 1 <= keymap의 원소의 길이 <= 100
- keymap[i]는 i + 1번 키를 눌렀을 때 순서대로 바뀌는 문자를 의미함
- keymap의 원소의 길이는 서로 다를 수 있으며 알파벳 대문자로만 이루어져 있음
- 1 <= target의 길이 <= 100
- 1 <= target의 원소의 길이 <= 100
- targets의 원소는 알파벳 대문자로만 이루어져 있음
입출력 예시

풀이
import java.util.*;
class Solution {
public int[] solution(String[] keymap, String[] targets) {
Map<Character, Integer> charMinPressMap = new HashMap<>();
for (String key : keymap) {
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
int pressCount = i + 1;
if (!charMinPressMap.containsKey(c)) {
charMinPressMap.put(c, pressCount);
} else {
charMinPressMap.put(c, Math.min(charMinPressMap.get(c), pressCount));
}
}
}
int[] answer = new int[targets.length];
for (int i = 0; i < targets.length; i++) {
String target = targets[i];
int totalPress = 0;
for (int j = 0; j < target.length(); j++) {
char c = target.charAt(j);
if (charMinPressMap.containsKey(c)) {
totalPress += charMinPressMap.get(c);
} else {
totalPress = -1;
break;
}
}
answer[i] = totalPress;
}
return answer;
}
}- 처음에는 반복문만을 사용해서 문제를 해결해보려다가 점점 쌓여가는 반복문을보고 4중 반복문을 쌓다가 이렇게 구현하다가는 제대로구현도 되지 않을 것 같고 너무 고려해야할게 많아지는 것 같았다
- 시간이 30분을 넘기게 되어 효율적으로 구현하고자 하는 방법을 찾아보았고 이런 문제에는 Map 자료구조를 사용하면 효율적으로 해결할 수 있다는 것을 알게 되었다
- (물론 배열을 최대값으로 초기화한 뒤, 각 값을 비교하며 최소값을 갱신하는 방식처럼 다른 방법도 있을 수 있다.)
- Map 채우기
- 먼저 Map<Character, Integer> charMinPressMap = new HashMap<>();을 통해 해당 key의 문자를 누를때 최소로 눌러야할 횟수를 값으로 담긴 HashMap 자료구조를 생성했다.
- 그다음 랜덤자판인 keymap을 반복문으로 순회하고, 한 번더 반복문을 통해 keymap에서 꺼낸 문자열을 charAt()으로 문자를 하나씩 꺼낸다.
- 이때 자판을 눌러서 다음 문자로 넘어간다는 것을 표현하기 위해 pressCount라는 변수를 선언하고 반복문 변수인 i가 0부터 시작되기 때문에 i + 1로 누른 횟수를 저장한다.
- 문자열에서 꺼낸 문자가 charMinPressMap에 저장되어있지 않다면 해당 문자를 key로 누를 횟수를 값으로 하여 Map에 저장한다.
- 이미 맵에 저장되어 있다면 Math.min()함수를 통해서 key값의 문자를 더 적게 눌러서 출력할 수 있는 횟수를 값으로 다시 저장한다.
- 이때 get(c)로 key에 대응되는 값을 조회해서 새롭게 비교되는 pressCount와 비교하여 더 작은 숫자를 다시 Map에 저장한다.
- 반복문이 끝나면 key에따라 최소한으로 눌러야하는 횟수가 Map에 모두 저장되게 된다
- 완성된 Map으로 targets의 문자열을 표현하기 위한 누른 횟수를 구하기
- 표현해야할 문자열이 담긴 targets의 갯수만큼 int[] 배열을 생성하여 문자열을 만들기 위해 눌러야할 횟수를 저장한다.
- 반복문을 통해 targets에서 표현해야할 문자열을 꺼내고, 전체 누른 횟수를 저장하는 totalPress 변수를 선언하고 다음 반복문을 통해 표현해야할 문자열을 charAt()으로 하나씩 문자로 꺼낸다.
- 그다음 조건문을 통해서 꺼낸 문자가 charMinPressMap의 key에 존재한다면 key에 대응되는 값을 꺼내서 totalPress에 누적 연산을하여 문자열을 구현하기 위해 버튼을 눌러야할 횟수를 구한다
- 만약 Map에 문자가 포함되어있지 않다면 바로 해당 문자열은 표현할 수 없다는 뜻이므로 -1을 저장하고 break를 통해 반복문을 빠져나가 다음 문자열을 비교한다.
- 2중 반복문이 끝날때마다 생성해둔 int[]배열에 totalPress의 값을 저장하여 문자열을 표현하기위해 눌러야할 횟수를 순서대로 저장후 반환하고 문제를 해결한다.
- Map이 아닌 최대값으로 초기화 하고 최소값을 갱신하는 방식의 코드
int[] press = new int[26];
Arrays.fill(press, Integer.MAX_VALUE); // '최대값'으로 초기화
for (String key : keymap) {
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
int idx = c - 'A';
press[idx] = Math.min(press[idx], i + 1); // 최소값 갱신
}
}
둘만의 암호
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/155652
- 두 문자열 s와 skip, 그리고 자연수 index가 주어질 때 다음 규칙에 따라 문자열을 만들어야 함
- 문자열 s의 각 알파벳을 index만큼 뒤의 알파벳으로 바꿔줌
- index만큼의 뒤의 알파벳이 z를 넘어갈 경우 다시 a로 돌아감
- skip에 있는 아파벳은 제외하고 건너뜀
- 예를 들어 s = "aukks", skip = "wbqd", index = 5 일때 a에서 5만큼 뒤에 있는 알파벳은 f지만 b,c,d,e,f에서 b와 d는 skip에 포함되므로 세지 않고 b, d를 제외하고 a에서 5만큼 뒤에 잇는 알파벳은 c,e,f,g,h 순서에 의해 h가 됨
- 나머지 문자들도 규칙대로 바꾸면 최종적으로 happy가 됨
- 두 문자열 s와 skip, 자연수 index가 매개변수로 주어질 때 위 규칙대로 s를 변환한 결과를 return 하도록 함수를 완성
제한조건
- 5 <= s의 길이 <= 50
- 1 <= skip의 길이 <= 10
- s와 skip은 알파벳 소문자로만 이루어져 있으며 skip에 포함되는 알파벳은 s에 포함되지 않음
- i <= skip <= 20
입출력 예시

풀이
class Solution {
public String solution(String s, String skip, int index) {
char[] cArr = s.toCharArray();
StringBuilder sb = new StringBuilder();
for (char c : cArr) {
int count = 0;
while (count < index) {
c++;
if (c > 'z') {
c = 'a';
}
if (!skip.contains(c + "")) {
count++;
}
}
sb.append(c);
}
return sb.toString();
}
}- 이 문제는 문자열을 문자 배열로 만들고 2중 반복문으로 문자 배열의 문자를 하나씩 꺼내서 skip의 문자랑 비교하는 과정까지는 진행했으나, index의 증가와 내부 알고리즘을 설계하는데 한계를 느끼고 1시간 내에 풀지를 못했다.
- 일단 문자 배열을 순회하여 문자를 하나씩 뽑는것 까지는 같았으나 내부 반복문에서 나는 for문을 썼는데 여기서는 while로 진행되었으므로 반복문의 조건을 세기 위한 count 변수가 하나 선언되었다
- 내부 반복문에서 주어진 index만큼 반복하고 문자를 c++로 반복한 횟수만큼 1씩 증가시킨다
- 이때 조건문을 통해서 c가 'z'를 넘어가면 'a'로 바꿔서 a부터 다시 증가되도록 조건문을 추가하고, !skip.contains(c+ "")를 통해 c가 skip에 포함되지 않았을 때만 count++로 반복문의 횟수가 증가되도록 한다.
- !skip.contains(c + "") 조건이 없이 그냥 count++을 해버리면 skip에 문자가 있든 없든 상관없이 index만큼만 반복되기 때문이다.
- 해당 조건이 모두 통과되어 내부 반복문이 끝나면 문자 c를 생성해둔 StringBuilder에 append를 하여 하나씩 추가하여 변경된 문자열을 만들고 toString()으로 변환하여 반환한다.
최적화 버전
import java.util.*;
class Solution {
public String solution(String s, String skip, int index) {
Set<Character> skipSet = new HashSet<>();
for (char ch : skip.toCharArray()) {
skipSet.add(ch);
}
StringBuilder sb = new StringBuilder();
for (char c : s.toCharArray()) {
int count = 0;
while (count < index) {
c++;
if (c > 'z') c = 'a';
if (!skipSet.contains(c)) count++;
}
sb.append(c);
}
return sb.toString();
}
}- 문자열.contains()은 처음부터 인자의 값을 하나씩 다 비교해야 하기 때문에O(n)의 성능을 보여주기 때문에 양이 많아지면 느릴 수 있는데 이를 Set 자료구조로 변환하면 성능 최적화를 할 수 있다고 한다.
- contaSet자료구조로 만든 skipSet.contions(c)은 중복이 없고 HashSet은 해싱을 사용한 자료구조이므로 바로 원하는 값을 찾을 수 있어 O(1)의 빠른 성능을 보일 수 있다
햄버거 만들기
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/133502
- 햄버거를 만들 때 빵 - 야채 - 고기 - 빵으로 쌓인 햄버거만 포장해야 함
- 포장하는 동안 속 재료가 추가적으로 들어오는 일과 재료의 높이를 무시하여 재료가 높이 쌓여서 일이 힘들어지는 경우도 없다고 가정
- 쌓인 재료가 야채, 빵, 빵, 야채, 고기, 빵, 야채, 고기, 빵일 때 예시
- 여섯 번째 재료가 쌓였을 때 세 번째 재료부터 여섯 번째 재료를 이용하여 햄버거를 포장
- 아홉 번째 재료가 쌓였을 때 두 번째 재료와 일곱 번째 재료부터 아홉 번째 재료를 이용하여 햄버거를 포장함
- 총 2개의 햄버거를 포장할 수 있음
- 상수에게 전해지는 재료의 정보를 나타내는 정수 배열 ingrediendt 가 주어졌을 때 상수가 포장하는 햄버거의 개수를 return 하는 함수를 완성
제한조건
- 1 <= ingredient 의 길이 <= 1,000,000
- ingredient의 원소는 1, 2, 3중 하나의 값이며 순서대로 빵, 야채, 고기를 의미함
입출력 예시

풀이
stack 대신 List,ArrayList를 stack 처럼 사용
import java.util.ArrayList;
import java.util.List;
class Solution {
public int solution(int[] ingredient) {
List<Integer> buffer = new ArrayList<>();
int answer = 0;
for (int i : ingredient) {
buffer.add(i);
int size = buffer.size();
if (size >= 4 &&
buffer.get(size - 4) == 1 &&
buffer.get(size - 3) == 2 &&
buffer.get(size - 2) == 3 &&
buffer.get(size - 1) == 1) {
for (int j = 0; j < 4; j++) {
buffer.remove(buffer.size() - 1);
}
answer++;
}
}
return answer;
}
}- 이 문제는 전통적으로 스택자료구조를 활용하기 위한 문제라고 한다.
- 나는 처음부터 알고리즘 공부를 해본적이 없기 때문에 배열로만 접근했었다가 문제를 실패했었고, 답지를 보고 Stack을 활용하는 문제라는 것을 알았다.
- 그러나 나는 Stack은 Vector로 만들어졌고 Vector는 synchronized가 모두 붙어있기 때문에 불필요한 동기화 비용이 발생하여 자바에서도 잘못 상속을 적용한 예시로 많이 알려져있다
- 결국 다른 방법을 찾다가 List,ArrayList를 Stack처럼 활용하는 풀이를 보았고 내부적으로 사용되는 코드가 Stack을 사용한 코드와 똑같이 사용할 수 있어 해당 방법을 풀이로 가져왔다.
- 먼저 햄버거의 재료를 순서대로 담을 buffer를 List, ArrayList로 구현하고 첫번째 반복문으로 주어진 재료를 하나씩 꺼내서 buffer에 추가한다.
- 그 다음 완성된 햄버거의 재료의 숫자가 4개이고, 순서가 고정되어있으므로 해당 조건을 조건문으로 구성하여 조건에 맞는다면 buffer에서 하나씩 사용된 재료들을 제거하고 햄버거를 만든 개수를 1 증가시킨다.
- 즉, 핵심 조건이 버퍼의 사이즈를 구한 후 재료가 4개이상 쌓이고 size - 4 == 1, size - 3 ... 과 같이 하드코딩이지만 원하는 햄버거의 순서가 buffer에 쌓여있다면 추가적인 반복문을 통해 마지막으로 쌓인 buffer에서부터 재료를 제거하는것이다.
- 물론 여기서 Stack을 대신하는 자료구조는 Deque<Integer> stack = new ArrayDeque<>()로 코드를 작성하는 것이 훨씬 빠르고 유연하겠지만 작성되는 코드가 달라지므로 실전에서 이런 문제를 접하게 된다면 그때 Deque를 활용해보면 좋을 것 같다
전통적인 풀이
stack 사용
import java.util.Stack;
class Solution {
public int solution(int[] ingredient) {
Stack<Integer> buffer = new Stack<>();
int answer = 0;
for (int i : ingredient) {
buffer.add(i);
int size = buffer.size();
if (size >= 4 &&
buffer.get(size - 4) == 1 &&
buffer.get(size - 3) == 2 &&
buffer.get(size - 2) == 3 &&
buffer.get(size - 1) == 1) {
for (int j = 0; j < 4; j++) {
buffer.remove(buffer.size() - 1);
}
answer++;
}
}
return answer;
}
}- 방식도 똑같고 구현도 똑같은데, 이 문제가 스택 구조를 어떻게 푸느냐라는 문제이므로 보통 Stack구조로 푸는 경우가 많다고 한다.
- 하지만 ArrayList로도 똑같이 구현할 수 있기 때문에 알고리즘 푸는 문제라고해도 굳이 Stack을 사용할 필요는 없는 것 같다
성격 유형 검사하기
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/118666
- 나만의 카카오 성격 유형 검사지를 아래와 같이 만들려고 할 때 4개의 지표가 있으므로 성격 유형은 총 16가지가 나올 수 있음
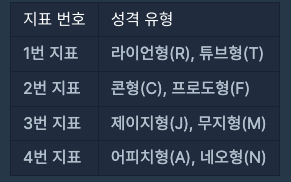
- 검사지에는 총 n개의 질문이 있고 각 질문에는 아래와 같은 선택지가 있으며 각 질문은 1가지 지표로 성격 유형 점수를 판단함
- 예를들어 한 질문에서 4번 지표로 아래 표처럼 점수를 매길 수 있음

- 이때 검사자가 질문에서 약간 동의 선택지를 선택하면 어피치형(A) 성격 유형 1점을 받게 되고 만약 검사자가 매우 비동의 선택지를 선택할 경우 네오형(N) 성격 유형 3점을 받게 됨
- 질문에 따라 어피치 형이 동의일 수도 있고, 네오형이 동의일 수도 있으며 각 선택지는 고정적인 점수를 가지고 있음
- 질문마다 판단하는 지표를 담은 1차원 무자열 배열 survey와 검사자가 각 질문마다 선택한 선택지를 담은 1차원 정수 배열 choices가 매개변수로 주어질 때 검사자의 성격 유형 검사 결과를 지표 번호 순서대로 return 하도록 하는 함수를 완성

제한조건
- 1 <= survey 의 길이 (=n) <= 1,000
- survey의 원소는 "RT", "TR", "FC", "CF", "MJ", "JM", "AN", "NA" 중 하나임
- survey[i]의 첫 번째 캐릭터는 i+1번 질문의 비동의 관련 선택지를, 두 번째 캐릭터는 동의 관련 선택지를 선택하면 받는 성격 유형을 의미함
- choice의 길이 = survey의 길이와 같음
- choices[i]는 검사자가 선택한 i+1번째 질문의 선택지를 의미함
- 1 <= choices의 원소 <= 7
입출력 예시

풀이
import java.util.*;
class Solution {
public String solution(String[] survey, int[] choices) {
Map<Character, Integer> scoreMap = new HashMap<>();
char[][] indicators = {
{'R', 'T'},
{'C', 'F'},
{'J', 'M'},
{'A', 'N'}
};
for (int i = 0; i < survey.length; i++) {
String type = survey[i];
int choice = choices[i];
char disagree = type.charAt(0);
char agree = type.charAt(1);
if (choice < 4) {
scoreMap.put(disagree, scoreMap.getOrDefault(disagree, 0) + (4 - choice));
} else if (choice > 4) {
scoreMap.put(agree, scoreMap.getOrDefault(agree, 0) + (choice - 4));
}
}
StringBuilder result = new StringBuilder();
for (char[] pair : indicators) {
char first = pair[0];
char second = pair[1];
int firstScore = scoreMap.getOrDefault(first, 0);
int secondScore = scoreMap.getOrDefault(second, 0);
if (firstScore >= secondScore) {
result.append(first);
} else {
result.append(second);
}
}
return result.toString();
}
}- 이문제는 코드는 쓰지도 못하고 어떻게 접근하면 좋을까 고민만 하다가 시간을 너무 써서 정답에 접근하지 못하고 실패했다
- survey를 반복문으로 뽑아서 choices와 대응하는 방식으로 했는데 조건이 너무 뒤바뀌어서 정렬를 해야할까? 고민하고, 점수계산을 하려면 또 반복문이 필요하다는 조건에 막혀서 정답을 찾아보게 되었다
- 그러다 Map과 getOrDefault를 사용하여 누적 연산을 하고, 이미 성격 유형을 분리해서 배열로 선언해놓고 문제를 푸는 방법이 너무 좋아보여서 가져왔다.
- 구조를 보면 두개의 반복문이 있는데, 처음 반복문은 survey와 choices를 뽑아서 선언해둔 scoreMap을 채우는 반복문이고 그 다음 반복문은 구해진 scoreMap을 활용하여 누적 점수를 계산하고 구해진 성격 유형을 하나씩 StringBuilder에 누적하는 반복문이다.
- 처음 반복문
- 처음 반복문을 보면 survey와 choices의 길이는 같기 때문에 하나의 반복문으로 survey와 choices의 요소를 하나씩 꺼낸다
- 그 다음 꺼내진 survey의 유형인 문자열을 charAt()으로 처음 것은 비동의, 두 번째 것은 동의로 분리한다.
- 조건문을 통해 사용자가 선택한 choice가 4 미만이면 scoreMap에 비동의문자를 key로 하여 값을 저장하는데, 이때 getOrDefault()를 활용하여 값이 없으면 0 + 4 - choice를, 값이 있으면 해당 값에 4 - choice를 한다.
- choice가 4 초과면 동의문자를 key하여 똑같이 getOrDefault()를 활용하는데 이때는 choice가 더 크기 때문에 choice - 4를 추갛하여 계산한다.
- 해당 반복문이 끝나면 모든 survey를 분리하여 각 유형마다 누적된 총 합이 값으로 작성된 scoreMap이 완성된다
- 두 번째 반복문
- 먼저 최종 성격 유형을 담을 StringBuilder을 선언해주고 반복문을 시작하는데 이때 사전에 모든 성격 유형을 선언해둔 2차원 배열인 indicators를 활용한다.
- 2차원 배열이라는 것만 다르고 성격 유형을 꺼내는 방식은 첫 번째 반복문에서 유형을 분리하는 것과 동일하다.
- 분리한 성격 유형을 통해 scoreMap에서 getOfDefault로 꺼내서 키가 있다면 해당되는 값을, 없다면 0을 꺼내서 점수를 각 변수에 저장한다.
- 꺼내진 점수를 비교하여 큰 값을 StringBuilder에 저장하고 모든 반복문을 거치면 모든 성격유형을 scoreMap에서 꺼내서 비교하여 최종 결정된 성격 유형이 StringBuilder에 완성된다.
- 이때 동점이라면 첫 번재 문자가 성격유형으로 반영되도록 되어있는데 이미 사전에 정의한 성격유형인 2차원 배열을 작성할 때 사전순으로 빠른 문자부터 정의했기 때문에 이런 조건으로 문제를 해결할 수 있다
- 완성된 SringBuilder를 toString()을 통해 스트링으로 변환하여 문제를 해결한다
바탕화면 정리
문제
- 프로그래머스 - https://school.programmers.co.kr/learn/courses/30/lessons/161990
- 컴퓨터 바탕화면은 각 칸이 정사각형인 격자판이며, 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어짐
- 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현함
- 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가지며 드래그를 하면 파일들을 선택할 수 있고 선택된 파일들을 삭제할 수 있음
- 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 할 때 드래그로 파일을 선택하는 방법은 아래와 같음
- 드래그는 바탕화면의 격자점 S(lux, luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx, rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동임
- 이때 점 S에서 점 E로 드래그 한다라고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현함
- 점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됨
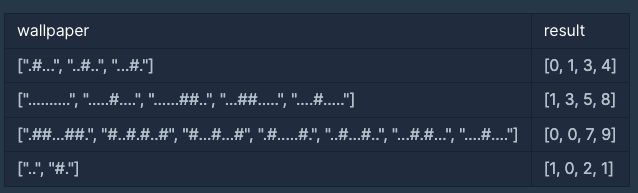
- 예시 - wallpaper가 [".#...", "..#..", "...#."]인 바탕화면을 그림으로 표현하면 아래와 같음
- 바탕화면에서 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그한 거리 (3 - 0) + (4 - 1) 6을 최솟값으로 모든 파일을 선택가능함
- (0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어남


- 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝남을 담은 정수 배열을 반환하는 함수를 작성
- 드래그의 시작 점이 (lux, luy), 끝점이 (rdx,rdy) 라면 정수 배열은 [lux, luy, rdx, rdy]를 리턴하면 됨
제한조건
- 1 <= wallpaper 의 길이 <= 50
- 1 <= walpaper[i] 의 길이 <= 50 이며 wallpaper의 모든 원소의 길이는 동일함
- wallpaper[i][j]는 바탕화면에서 i + 1행 j + 1열에 해당하는 칸의 상태를 나타내며 "#" 또는 "."의 값만 가짐
- 바탕화면에는 적어도 하나의 파일이 있음
- 드래그 시작점과 끝점은 lux < rdx, luy < rdy를 만족해야 함
입출력 예시
풀이
class Solution {
public int[] solution(String[] wallpaper) {
int lux = Integer.MAX_VALUE;
int luy = Integer.MAX_VALUE;
int rdx = Integer.MIN_VALUE;
int rdy = Integer.MIN_VALUE;
for (int i = 0; i < wallpaper.length; i++) {
for (int j = 0; j < wallpaper[i].length(); j++) {
if (wallpaper[i].charAt(j) == '#') {
lux = Math.min(lux, i);
luy = Math.min(luy, j);
rdx = Math.max(rdx, i + 1);
rdy = Math.max(rdy, j + 1);
}
}
}
int[] answer = {lux, luy, rdx, rdy};
return answer;
}
}- 이 문제는 2중 반복문을 사용하여 wallpaper의 요소를 꺼내고, 꺼낸 요소에서 '#'을 찾아서 조작하는 방식으로 접근했지만, lux, luy, rdx, rdy를 구하는 것에서 시간을 넘겨서 결국 올바른 접근 방법을 확인하기 위해 풀이를 찾았다
- 근데 여기서 MAX_VALUE, MIN_VALUE로 값을 초기화 해두고 이를 min, max를 통해 값을 비교하여 최종적으로 값을 구하는 방식을 알게 되었다.
- 먼저 lux, luy, rdx, rdy를 0이 아니라 lux, luy는 정수의 최대값, rdx, rdy는 최소값으로 초기화 해둔다
- 이렇게 초기화하는 이유는, lux, luy는 드래그의 시작점이자 가장 작은 좌표를 찾아야 하므로 Math.min()을 사용할 것이고, 처음 값을 일부러 가장 큰 값으로 잡아놔야 실제 값과 비교하면서 갱신이 되기 때문이다.
- rdx, rdy도 반대 개념으로, 드래그의 끝점인 최대 좌표를 구해야 하므로 처음에는 정수의 최소값으로 설정하고, 이후 반복문 안에서 Math.max()를 통해 계속 큰 값으로 갱신해 나간다.
- 이렇게 min()과 max()를 활용하려면 처음 초기값을 0이나 999999처럼 임의의 숫자(매직 넘버)로 넣는 것보다 Integer.MAX_VALUE, Integer.MIN_VALUE를 사용하는 것이 가독성과 안정성 면에서 훨씬 좋다.
- 이후 2중 반복문으로 '#'이 들어있는 index번호를 min() 함수를 통해 lux와 luy의 값을 구하고 max함수를 통해 rdx, rdy를 구한다
- 이때 드래그의 끝점은 파일이 위치한 지점보다 1칸 앞으로 가야 파일을 드래그할 수 있으므로 +1을 하여 rdx, rdy를 구한다
- 이렇게 구해진 값을 배열에 담아서 반환하면 문제를 깔끔하게 해결할 수 있다
728x90
'기타 개발 공부 > 온라인 코딩 테스트 회고' 카테고리의 다른 글
'기타 개발 공부/온라인 코딩 테스트 회고' Related Articles
more



