
- 분류 전체보기 (358)

- 프로젝트 회고 (4)
- 개발 공부 복습 (0)
- 인프런 - 스프링 완전정복 코스 로드맵 (98)
- 인프런 - 스프링부트와 JPA실무 로드맵 (30)
- 인프런 - 실전 자바 로드맵 (21)
- 책 공부 (3)
- 유튜브 공부 (75)
- 2024정보처리기사 준비 정리(필기 - 시나공, 실기 - 수제비) (127)
- 필기 1강 - 소프트웨어 설계 (17)
- 필기 2강 - 소프트웨어 개발 (16)
- 필기 3강 - 데이터베이스 구축 (13)
- 필기 4강 - 프로그래밍 언어 활용 (8)
- 필기 5강 - 정보시스템 구축 관리 (13)
- 실기 6강 - 프로그래밍 언어 활용 (22)
- 실기 1강 - 요구사항 확인(일부분), 2강 - 화면설계(일부분) (3)
- 실기 3강 - 데이터 입출력 구현 (5)
- 실기 7강 - SQL 응용 (7)
- 실기 9강 - 소프트웨어 개발 보안 구축 (8)
- 실기 10강 - 애플리케이션 테스트 관리 (5)
- 실기 11강 - 응용 SW 기초 기술 활용 (10)
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 자바의 정석 기초편 ch2
- @Aspect
- 2024 정보처리기사 수제비 실기
- 자바의 정석 기초편 ch7
- 스프링 mvc2 - 타임리프
- 스프링 db1 - 스프링과 문제 해결
- 자바의 정석 기초편 ch3
- 자바의 정석 기초편 ch12
- 스프링 mvc2 - 로그인 처리
- 스프링 입문(무료)
- 자바의 정석 기초편 ch9
- jpa - 객체지향 쿼리 언어
- 코드로 시작하는 자바 첫걸음
- 자바 기본편 - 다형성
- 게시글 목록 api
- 자바의 정석 기초편 ch8
- 2024 정보처리기사 시나공 필기
- jpa 활용2 - api 개발 고급
- 스프링 mvc1 - 스프링 mvc
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch1
- 자바의 정석 기초편 ch4
- 스프링 db2 - 데이터 접근 기술
- 자바의 정석 기초편 ch5
- 스프링 고급 - 스프링 aop
- 자바의 정석 기초편 ch13
- 스프링 mvc2 - 검증
- 자바의 정석 기초편 ch14
- 자바의 정석 기초편 ch6
- 스프링 mvc1 - 서블릿
Archives
- Today
- Total
나구리의 개발공부기록
자바의 정석 기초편 ch11 - 7 ~ 12 [ArrayList,JavaAPI소스보기, LinkdList] 본문
유튜브 공부/JAVA의 정석 기초편(유튜브)
자바의 정석 기초편 ch11 - 7 ~ 12 [ArrayList,JavaAPI소스보기, LinkdList]
소소한나구리 2023. 12. 8. 16:531) ArrayList
- 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
- Vector = 동기화 처리 되어있음, ArrayList = 동기화 처리가 되어있지 않음
- List인터페이스를 구현 -> 저장 순서유지 , 중복 허용
- 데이터의 저장공간으로 배열을 사용
public class Vector extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable {
...
protected Object[] elementData;
// Object[](객체배열 - 다형성) -> 모든 종류의 객체 저장 가능
...2) ArrayList의 메서드
(1) 생성자
- ArrayList() : 기본생성자, 초기용량의 기본값은 10
- ArrayList(Collection c) : 인수로 컬렉션을 주면 배열로 생성
- ArrayList(int initialCapacity) : 배열의 길이를 지정
(2) 메서드
- 추가
- boolean add(Object o) : 객체를 맨 뒤에 저장
- void add(int index, Object element) : 지정 위치에 객체 저장
- boolean addAll(Collection c) : 콜렉션을 맨 뒤에 저장
- boolean addAll(int index, Collection c) : 지정 위치에 콜렉션을 저장
- 삭제
- boolean remove(Object o) : 저장한 객체 삭제
- Object remove(int index) : 특정위치의 객체 삭제
- boolean removeAll(Collection c) : 저장한 콜렉션을 삭제
- void clear() : 모든객체삭제
- 검색
- int indexOf(Object o) : 객체가 몇번째 인덱스에 있는지 처음부터 검색, 못찾으면 -1반환
- int lastIndexOf(Object o) : indexOf의 기능을 맨끝에서부터 검색
- boolean contains(Object o) : 객체가 존재하는지 확인후 있으면 true, 없으면 false
- Object get(int index) : 특정위치의 객체를 읽기
- Object set(int index, Object element) : 특정 위치의 객체를 변경
- List subList(int fromIndex, int toIndex) : from ~ to사이에 있는 객체를 뽑아서 새로운List를 생성
- Object[] toArray() : ArrayList의객체 배열을 반환
- Object[] toArray(Object[] a) : 지정된 요소를 포함하는 배열을 반환
- boolean isEmpty() : 비어있는지 확인
- void trimToSize() : 빈공간 제거
- int size() : ArrayList에 저장된 객체의 개수 반환
(1) 예제
import java.util.*;
class Ex11_1 {
public static void main(String[] args) {
// 기본 길이(용량, capacity)가 10인 ArrayList를 생성
ArrayList list1 = new ArrayList(10);
// ArrayList에는 객체만 저장가능 -> 기본형을 넣어도 오토박싱을 통해 저장 됨
list1.add(5); // 우리는 이렇게 코딩
// list1.add(new Integer(5)); 이런방식은 Java9이후로 deprecated 되었으므로 기본값으로 저장
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
// ArrayList의 일부를 뽑아서 생성(1,4) -> 1 ~ 3까지
// List sub = list1.subList(1,4); sub = 읽기만 가능
// ArrayList list2 = new ArrayList(sub); sub와 같은 내용의 ArrayList를 생성(쓰기 위함)
ArrayList list2 = new ArrayList(list1.subList(1,4)); // 위의 두줄을 한줄로 작성
print(list1, list2);
// Collections 유틸리티 클래스를 활용하여 오름차순 정렬
Collections.sort(list1); // list1과 list2를 오름차순 정렬
Collections.sort(list2); // Collections.sort(List l)
print(list1, list2);
// list1이 list2의 요소를 모두 포함하고있는지 확인 -> 포함하면 true
System.out.println("list1.containsAll(list2):"
+ list1.containsAll(list2));
// list2의 마지막에 "B","C"를 추가(부담이 적음)
// list2의 인덱스3번째에 "A" 추가 -> 자리이동하여 공간을 확보 후 추가(부담이 가는 작업)
list2.add("B");
list2.add("C");
list2.add(3, "A");
print(list1, list2);
// 인덱스 3번째의 값을 "AA"로 변경
list2.set(3, "AA");
print(list1, list2);
// 인덱스 0번째의 값을 "1"(문자열)로 변경
list1.add(0, "1");
// indexOf("1") 문자열 1의 위치 인덱스를 반환, 못찾으면 -1
System.out.println("index="+ list1.indexOf("1"));
// indexOf(1) Integer 1의 위치 인덱스를 반환, 못찾으면 -1
System.out.println("index="+ list1.indexOf(1));
print(list1, list2);
// 인덱스 0번의 값을 삭제
list1.remove(0);
// list1.remove(new Integer(1)); Integer 1의 값을 삭제 -> deprecated된 방법
print(list1, list2);
// list1에서 list2와 겹치는 부분만 남기고 나머지는 삭제한다.
System.out.println("list1.retainAll(list2):" + list1.retainAll(list2));
print(list1, list2);
// list2에서 list1에 포함된 객체들을 삭제한다.
for(int i= list2.size()-1; i >= 0; i--) {
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
} // main의 끝
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
} // class
/*
출력결과
list1:[5, 4, 2, 0, 1, 3]
list2:[4, 2, 0]
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4]
list1.containsAll(list2):true
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, A, B, C]
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, AA, B, C]
index=0
index=2
list1:[1, 0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, AA, B, C]
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, AA, B, C]
list1.retainAll(list2):true
list1:[0, 2, 4]
list2:[0, 2, 4, AA, B, C]
list1:[0, 2, 4]
list2:[AA, B, C]
*/3) ArrayList에 저장된 객체의 삭제과정
(1) ArrayList에 저장된 중간의 데이터를 삭제할 경우 메커니즘
- 삭제할 데이터를 기준으로 다음 인덱스 번호의 값들을 복사하여 삭제 대상의 인덱스 위치에 덮어쓰기를 하여 삭제 대상을 삭제
- 삭제 대상의 위치에서 덮어쓰기를 하였기 때문에 마지막 값을 null로 변경해줌
- 데이터가 삭제되어 데이터의 개수가 줄었으므로 size의 값을 감소시킴
- 마지막 데이터를 삭제하는 경우 배열의 복사 과정이 없음
- 배열 복사 과정이 부담이 많이 가는 작업이므로 되도록이면 발생하지 않도록 뒤에서부터 삭제하는 것을 권장함
| index | data[0] | data[1] | data[2] | data[3] | data[4] | data[5] | data[6] |
| 객체(값) | 0 | 1 | 2(삭제대상) | 3(복사대상) | 4(복사대상) | null | null |
| index | data[0] | data[1] | data[2] | data[3] | data[4] | data[5] | data[6] |
| 객체(값) | 0 | 1 | 3(덮어쓰기) | 4(덮어쓰기) | 4 | null | null |
| index | data[0] | data[1] | data[2] | data[3] | data[4] | data[5] | data[6] |
| 객체(값) | 0 | 1 | 3 | 4 | null | null | null |
(2) 삽입할 경우 반대로 진행
- size값을 증가 시킴
- 삽입하고자 할 위치부터 배열 끝까지의 데이터를 복사해서 그 다음 인덱스의 위치에 복사 후 삽입할 위치의 값은 null로 변경
- 삽입할 인덱스의 위치에 값을 저장
(3) ArrayList의 저장된 객체를 전부 삭제
- 첫 번재 객체부터 삭제하는 경우 배열 복사가 발생 됨 - 권장하지 않음
- data[0]에 data[1]의 객체가 data[1]에는 data[2]의 객체가 순차적으로 복사됨
- data[0]에 객체가 남아있는 상태에서 반복문에 의해 data[1]의 객체가 삭제됨 ... 반복 -> 데이터가 남아있게 됨
for(int i=0; i<list.size(); i++)
list.remove(i);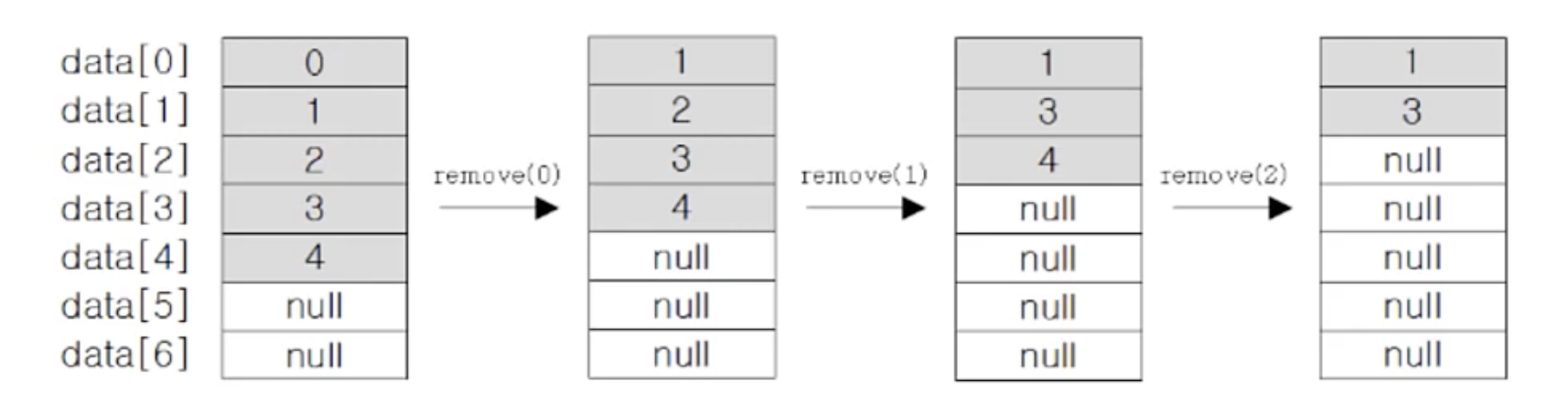
- 마지막 객체부터 삭제하는 경우(모든 객체가 삭제 됨) - 권장
for(int i=list.length()-1; i >=0; i--)
list.remove(i);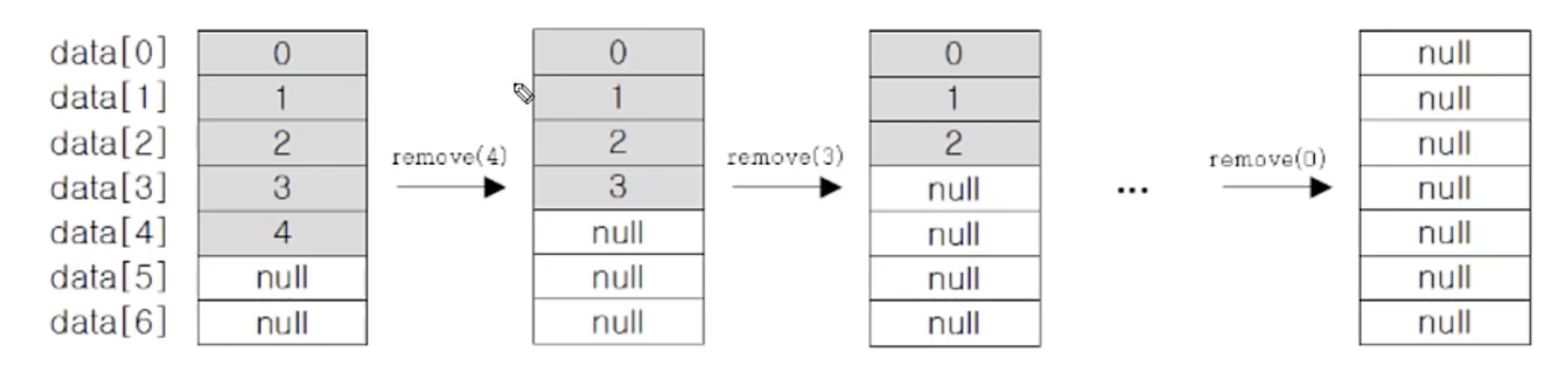
4) JavaAPI 소스보기
- eclipse에서 원하는 클래스나 메서드에서 우클릭 -> Open Decalration을 클릭
- Intellij에서는 쉬프트를 2번클릭하여 원하는 클래스나 메서드를 검색 후 컨트롤 + j를 하면 공식 문서를 볼 수 있음
5) 배열의 장단점
(1) 장점
- 구조가 간단함
- 데이터를 읽는데 걸리는 시간이 짧음(접근시간, access time)
- (배열주소 + 데이터 타입의 크기) x index번호 = n+1번째 요소의 주소를 알 수 있음 -> 이런 계산에 걸리는 시간이 빠름
(2) 단점
- 실행 중에 크기를 변경할 수 없음
- 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터 복사(더 큰 배열생성 -> 값복사 -> 참조변경)
- 크기 변경을 피하기 위해 충분한 크기의 배열을 생성하면 메모리가 낭비 됨
- 비순차적인 데이터의 추가, 삭제에 시간이 많이 걸림 (배열 중간의 데이터의 추가, 삭제)
6) LinkedList
class Node { // 객체(주소)하나하나를 Node라고 부름
Node next; // 다음 Node로 넘어가는 참조변수 next를 가지고 있음
Object obj; // Node에 저장된 데이터
}- 크기 변경이 불가하고 추가,삭제 시 시간이 많이 걸리는 배열의 단점을 보완
- 배열과 달리 불연속적으로 존재할 수 있는 데이터를 연결(link)
- 각 Node는 불연속적으로 여기저기에 저장(바로 옆에 있을 수도, 떨어져있을 수도 있음)되며 해당 Node들을 연결하여 List를 구성함
(1) 데이터의 삭제
- 단 한번의 참조변경만으로 가능
- 0x350 주소를 가진 Node를 삭제하고자 하면 해당 주소의 node의 연결자체를 끊어버리고 그 다음 노드로 연결하고 끊어진 노드는 가비지 컬렉터에의해서 삭제됨
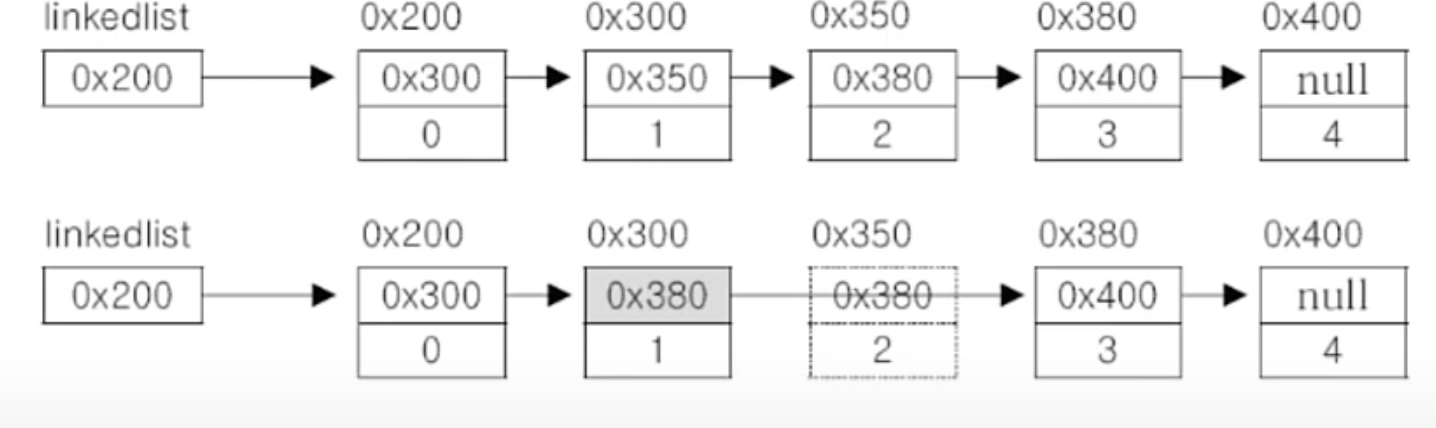
(2) 데이터의 추가
- 한번의 Node객체 생성과 두 번의 참조 변경으로 가능
- 0x500의 Node객체를 추가하고자 할 때 하면 Node객체를 생성 후 추가하고자 하는 Node들의 사이에 연결(이때 참조변경이 2번 일어남)
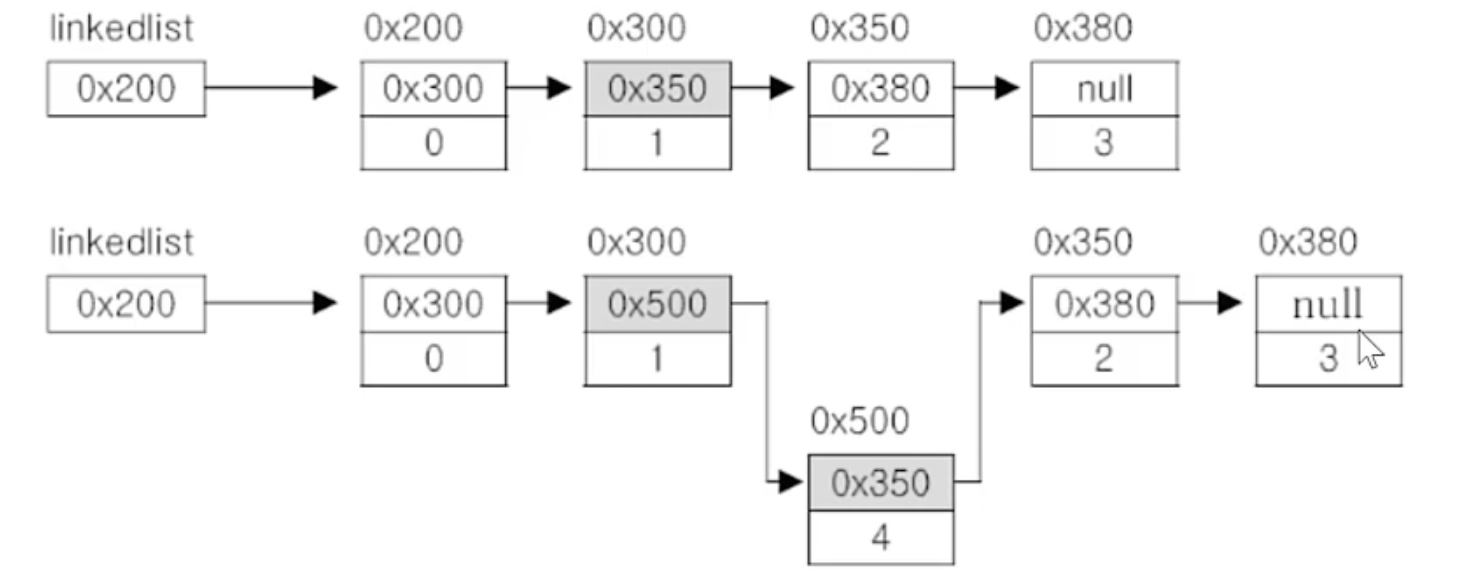
(3) 단점
- 접근성이 나쁨
- 한 번에 여러 Node를 건너뛰면서 접근이 불가능하고 항상 다음 Node로만 이동이 가능
- 0x200 -> 0x380 으로 한 번에 이동 불가

(4) Java에서 구현된 LinkedList
- doubly linked list(이중 연결 리스트)로 구현되어 있음
- Node를 앞뒤로 이동 할 수 있게 변경된 LinkedList로 접근성이 향상됨
- 연결이 앞의 Node와 뒤의 Node 2개로 되어있음
- 단, 데이터 삭제, 추가 시 두개의 연결을 맺고 끊어줘야 하고 여전히 한 번에 여러 Node를 건너뛰는 접근은 불가능함
class Node {
Node next; // 다음 Node
Node previous; // 이전 Node
Object obj;
}
(5) 더블리 써큘러 링크드 리스트(doubly circular linked list; 이중 원형 연결리스트)
- 맨뒤의 Node와 맨 앞의 Node를 연결하여 Circle 화함
- 맨 앞에서 맨 뒤로 접근할 수 있고, 맨 뒤에서 맨 앞으로 접근할 수 있는 LinkedList도 있음

(6) ArrayList vs LinkedList - 성능비교
- 순차적으로 데이터를 추가/삭제 -> ArrayList가 빠름
- 비순차적으로 데이터를 추가/삭제 -> LinkedList가 빠름
- 조회 시간(access time) -> ArrayList가 빠름
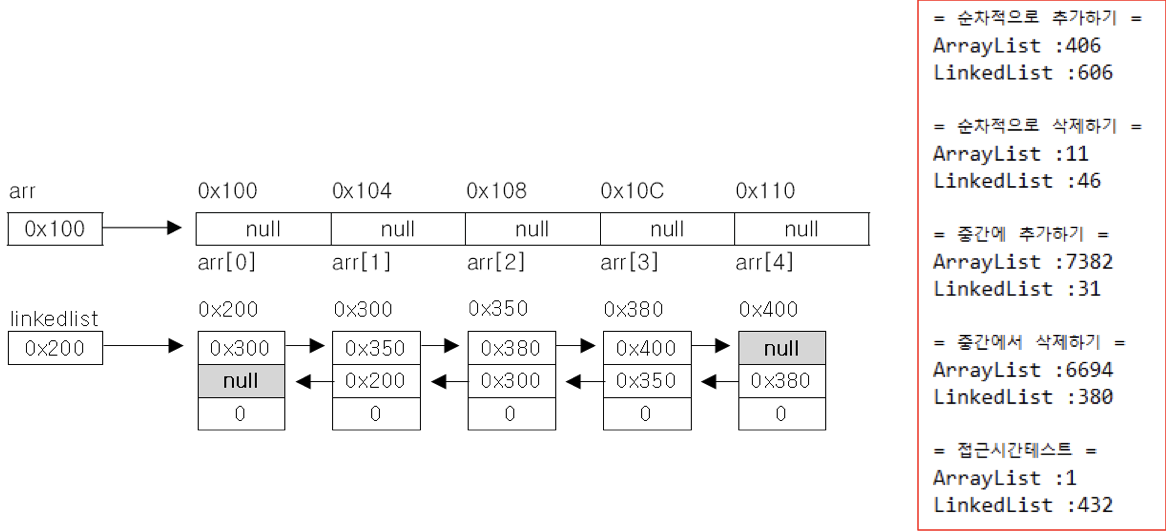
- ArrayList가 순차적인 데이터 추가, 삭제, 조회는 빠르지만 비효율적인 메모리의 사용과 순차적이지 않은 데이터의 추가 삭제는 속도가 느림
- LinkedList는 조회는 느리지만 비순차적인 데이터의 추가 삭제는 빠름 그러나 데이터가 많은수록 접근성이 떨어짐
** 출처 : 남궁성의 정석코딩_자바의정석_기초편 유튜브 강의
'유튜브 공부 > JAVA의 정석 기초편(유튜브)' 카테고리의 다른 글
'유튜브 공부/JAVA의 정석 기초편(유튜브)' Related Articles
more



