
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 스프링 입문(무료)
- 자바의 정석 기초편 ch9
- 자바 기초
- 자바 중급2편 - 컬렉션 프레임워크
- 자바로 계산기 만들기
- 자바 고급2편 - io
- 자바의 정석 기초편 ch4
- @Aspect
- 자바로 키오스크 만들기
- 자바의 정석 기초편 ch5
- 자바의 정석 기초편 ch6
- 자바 중급1편 - 날짜와 시간
- 스프링 mvc2 - 검증
- 2024 정보처리기사 수제비 실기
- 스프링 mvc2 - 타임리프
- 자바의 정석 기초편 ch7
- 스프링 트랜잭션
- 자바의 정석 기초편 ch11
- 자바의 정석 기초편 ch2
- 데이터 접근 기술
- 자바의 정석 기초편 ch13
- 스프링 고급 - 스프링 aop
- 스프링 mvc2 - 로그인 처리
- 람다
- 자바의 정석 기초편 ch1
- 자바의 정석 기초편 ch12
- 2024 정보처리기사 시나공 필기
- 자바 고급2편 - 네트워크 프로그램
- 자바의 정석 기초편 ch14
- 스프링 mvc1 - 스프링 mvc
- Today
- Total
개발공부기록
컬렉션 프레임워크 - Map, Stack, Queue, 컬렉션 프레임워크 - Map(소개, 구현체), 스택 자료 구조, 큐 자료 구조, Deque 자료 구조, Deque와 Stack, Queue 본문
컬렉션 프레임워크 - Map, Stack, Queue, 컬렉션 프레임워크 - Map(소개, 구현체), 스택 자료 구조, 큐 자료 구조, Deque 자료 구조, Deque와 Stack, Queue
소소한나구리 2025. 2. 7. 18:24출처 : 인프런 - 김영한의 실전 자바 - 중급2편 (유료) / 김영한님
유료 강의이므로 정리에 초점을 두고 코드는 일부만 인용
1. 컬렉션 프레임워크 - Map
1) 소개
(1) Map
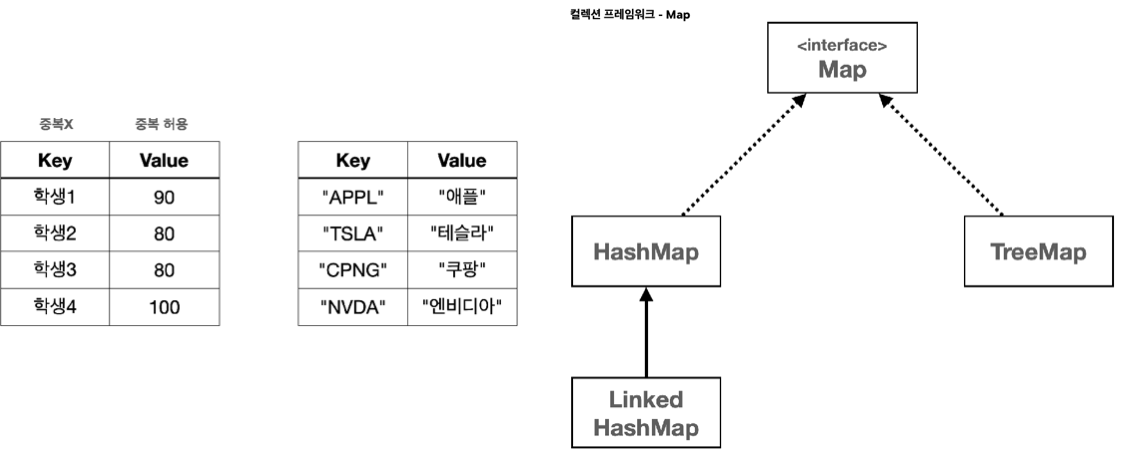
- Map은 키-값의 쌍을 저장하는 자료구조임
- 키는 맵 내에서 유일해야 하며 키를 통해 값을 빠르게 검색할 수 있음
- 키는 중복될 수 없지만 값은 중복될 수 있으며 Map은 순서를 유지하지 않음
- HashMap, TreeMap, LinkedHashMap 등 다양한 Map 구현체를 제공하며 각 구현체마다 다른 특성과 성능 특징을 가지고 있으며 이 중에서 HashMap을 가장 많이 사용함
(2) Map 인터페이스의 주요 메서드
| 메서드 | 설명 |
| put(K key, V value) | 지정된 키와 값을 맵에 저장(같은 키가 있으면 값을 변경) |
| putAll(Map<? extends K,? extends V> m) | 지정된 맵의 모든 매핑을 현재 맵에 복사 |
| putIfAbsent(K key, V value) | 지정된 키가 없는 경우에 키와 값을 맵에 저장 |
| get(Object key) | 지정된 키에 연결된 값을 반환 |
| getOrDefault(Object key, V defaultValue) | 지정된 키에 연결된 값을 반환, 키가 없는 경우 defaultValue로 지정한 값을 대신 반환 |
| remove(Object key) | 지정된 키와 그에 연결된 값을 맵에서 제거 |
| clear() | 맵에서 모든 키와 값을 제거 |
| containsKey(Object key) | 맵이 지정된 키를 포함하고 있는지 여부를 반환 O(1)의 성능으로 빠름 |
| containsValue(Object value) | 맵이 하나 이상의 키에 지정된 값을 연결하고 있는지 여부를 반환 찾는 값이 있는지 확인해야 하기 때문에 O(n)으로 성능이 좋지 않음 |
| keySet() | 맵의 키들을 Set 형태로 반환 |
| values() | 맵의 값들을 Collection 형태로 반환 |
| entrySet() | 맵의 키-값 쌍을 Set<Map.Entry<K,V>> 형태로 반환 |
| size() | 맵에 있는 키-값 쌍의 개수를 반환 |
| isEmpty() | 맵이 비어있는지 여부를 반환 |
(3-1) MapMain1
- Map의 기본 기능을 사용하는 코드
package collection.map;
public class MapMain1 {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
// 학생 성적 데이터 추가
studentMap.put("studentA", 90);
studentMap.put("studentB", 80);
studentMap.put("studentC", 80);
studentMap.put("studentD", 100);
System.out.println(studentMap);
// 특정 학생의 값 조회
Integer result = studentMap.get("studentD");
System.out.println("result = " + result);
System.out.println("KeySet 활용");
Set<String> keySet = studentMap.keySet();
for (String key : keySet) {
Integer value = studentMap.get(key);
System.out.println("key = " + key + ", value = " + value);
}
System.out.println("entrySet 활용");
Set<Map.Entry<String, Integer>> entries = studentMap.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("key = " + key + ", value = " + value);
}
System.out.println("values 활용");
Collection<Integer> values = studentMap.values();
for (Integer value : values) {
System.out.println("value = " + value);
}
}
}
/* 실행 결과
{studentB=80, studentA=90, studentD=100, studentC=80}
result = 100
KeySet 활용
key = studentB, value = 80
key = studentA, value = 90
key = studentD, value = 100
key = studentC, value = 80
entrySet 활용
key = studentB, value = 80
key = studentA, value = 90
key = studentD, value = 100
key = studentC, value = 80
values 활용
value = 80
value = 90
value = 100
value = 80
*/
(3-2) 키 목록 조회
- Map의 키는 중복을 허용하지 않으므로 Map의 모든 키 목록을 조회하는 keySet()을 호출하면 중복을 허용하지 않는 자료 구조인 Set을 반환함
(3-3) 키와 값 목록 조회
- Map은 키와 값을 보관하는 자료구조이기 때문에 키와 값을 하나로 묶을 수 있는 방법이 필요한데 이때 Entry를 사용함
- Entry는 키-값의 쌍으로 이루어진 간단한 객체로 Map 내부에서 키와 값을 함께 묶어서 저장할 때 사용함
- Map에 키와 값으로 데이터를 저장하면 Map은 내부에서 키와 값을 하나로 묶는 Entry객체를 만들어서 보관함
- 참고로 하나의 Map에 여러 Entry가 저장될 수 있으며, Entry는 Map 내부에 있는 인터페이스로 별도의 구현체가 있지만 보통 Entry 구현체를 사용함
(3-4) 값 목록 조회
- Map의 값은 중복을 허용하므로 중복을 허용하지 않는 Set으로 반환할 수 없고, 입력 순서를 보장하지 않기 때문에 순서를 보장하는 List로도 반환하기 애매함
- 따라서 단순히 값의 모음이라는 의미의 상위 인터페이스인 Collection으로 반환함
(4) MapMain2
- Map은 같은 키에 다른 값을 저장하면 기존 값을 교체함
- studentA=90에서 studentA=100으로 변경되는 것을 확인할 수 있음
package collection.map;
public class MapMain2 {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
// 학생 성적 데이터 추가
studentMap.put("studentA", 90);
System.out.println(studentMap);
studentMap.put("studentA", 100); // 같은 키에 저장시 기존 값 교체
System.out.println(studentMap);
boolean containsKey = studentMap.containsKey("studentA");
System.out.println("containsKey = " + containsKey);
// 특정 학생의 값 삭제
studentMap.remove("studentA");
System.out.println(studentMap);
}
}
/* 실행 결과
{studentA=90}
{studentA=100}
containsKey = true
{}
*/
(5) MapMain3
- 위의 예제처럼 같은 키를 저장하면 값을 덮어버리기 때문에 같은 학생이 Map에 없는 경우에만 데이터를 저장하도록 하려면 if문을 작성해서 조건을 거쳐서 값을 저장해야할 것임
- Map이 제공하는 putIfAbsent()메서드를 활용하면 간단하게 인자로 전달되는 키의 값이 없는 경우에만 값이 저장되도록 할 수 있음
package collection.map;
public class MapMain3 {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
// 학생 성적 데이터 추가
studentMap.put("studentA", 50);
System.out.println(studentMap);
// 학생이 없는 경우에만 추가1
if (!studentMap.containsKey("studentA")) {
studentMap.put("studentA", 100);
}
System.out.println(studentMap);
// 학생이 없는 경우에만 추가2
studentMap.putIfAbsent("studentA", 100);
studentMap.putIfAbsent("studentB", 100);
System.out.println(studentMap);
}
}
/* 실행 결과
{studentA=50}
{studentA=50}
{studentB=100, studentA=50}
*/2) 구현체
(1) Map vs Set
- Map의 키는 중복을 허용하지 않고 순서를 보장하지 않는데, Map의 키는 Set과 같은 구조임
- Map은 모든 것이 Key를 중심으로 동작하며 Value는 단순히 Key 옆에 따라 붙은 것임
- 즉, Key 옆에 Value만 하나 추가해주면 Map이 되는 것이기 때문에 Map과 Set은 구조가 거의 같으며 단지 Value를 가지고 있는가 없는가의 차이임
- 이런 이유로 Set과 Map의 구현체는 거의 같은데 실제로 자바HashSet의 구현은 대부분 HashMap의 구현을 가져다가 Map의 value를 비워두는 식으로 사용하고 있음
- HashSet -> HashMap
- LinkedHashSet -> LinkedHashMap
- TreeSet -> TreeMap
(2) HashSet
- 구조: HashMap은 해시를 사용해서 요소를 저장함, 키(key)값은 해시 함수를 통해 해시 코드로 변환되고 이 해시 코드는 데이터를 저장하고 검색하는데 사용됨
- 특징: 삽입, 삭제, 검색 작업은 해시 자료 구조를 사용하므로 일반적으로 O(1)의 시간 복잡도를 가짐
- 순서: 순서를 보장하지 않음
(3) LinkedHashMap
- 구조: LinkedHashMap은 HashMap과 유사하지만 연결 리스트를 사용하여 삽입 순서 또는 최근 접근 순서에 따라 요소를 유지함
- 특징: 입력 순서에 따라 순회가 가능하며 입력 순서를 링크로 유지해야하므로 HashMap보다 조금 더 무거움
- 성능: 대부분의 작업이 O(1)의 시간 복잡도를 가짐
- 순서: 입력 순서를 보장함
(4) TreeMap
- 구조: 레드-블랙 트리를 기반으로 한 구현임
- 특징: 모든 키는 자연 순서 또는 생성자에 제공된 Comparator에 의해 정렬됨
- 성능: get, put, remove와 같은 주요 작업들인 O(log n)의 시간 복잡도를 가짐
- 순서: 키는 정렬된 순서로 저장됨
(5) JavaMapMain
- 각 구현체를 다형성을 통해 동일한 코드를 실행해보면 특징에 따라 실행결과가 다르게 출력되는 것을 확인할 수 있음
- HashMap: 입력한 순서를 보장하지 않음
- LinkedHashMap: 키를 기준으로 입력한 순서를 보장함
- TreeMap: 키 자체의 데이터 값을 기준으로 정렬함
package collection.map;
public class JavaMapMain {
public static void main(String[] args) {
run(new HashMap<>());
run(new LinkedHashMap<>());
run(new TreeMap<>());
}
private static void run(Map<String, Integer> map) {
System.out.println("map = " + map.getClass());
map.put("C", 10);
map.put("B", 20);
map.put("ㅋ", 10);
map.put("4", 30);
map.put("2", 40);
map.put("D", 60);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.print(key + "=" + map.get(key) + " ");
}
System.out.println();
}
}
/* 실행 결과
map = class java.util.HashMap
B=20 2=40 C=10 4=30 D=60 ㅋ=10
map = class java.util.LinkedHashMap
C=10 B=20 ㅋ=10 4=30 2=40 D=60
map = class java.util.TreeMap
2=40 4=30 B=20 C=10 D=60 ㅋ=10
*/
(6) 자바 HashMap 작동 원리

- 자바의 HashMap은 HashSet과 기본적으로 작동원리가 같음
- Key를 사용하여 해시 코드를 생성하고 Entry를 사용하여 Key, Value를 하나로 묶어서 저장하는 정도의 차이가 있음
- 이렇게 해시를 사용해서 키와 값을 저장하는 자료 구조를 일반적으로 해시 테이블이라 함
- HashSet은 해시 테이블의 주요 원리를 사용하여 키-값이 아니라 키만 저장하는 특수한 형태의 해시 테이블이라고 이해하면 됨
** 주의!
- 해시를 사용하므로 Map의 Key로 사용되는 객체는 hashCode(), equals()를 반드시 구현해야 함
(7) 정리
- 실무에서는 Map이 필요한 경우 HashMap을 가장 많이 사용하며 순서 유지, 정렬의 필요에 따라서 LinkedHashMap, TreeMap을 선택하면 됨
2. 스택 자료 구조
1) 스택(Stack)
(1) 구조

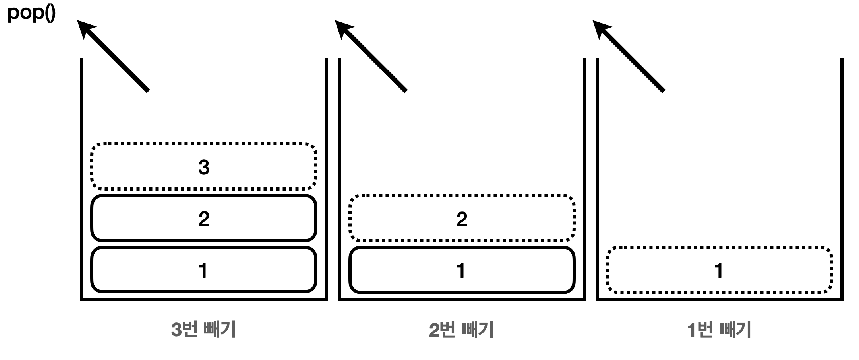
- 1, 2, 3 이름표가 붙은 블록이 있다고 가정하여 그림 처럼 아래는 막혀있고 위만 열려있는 통에 이 박스를 넣는다고 가정해보면 위쪽만 열려있기 때문에 위쪽으로 블록을 넣고 위쪽으로 블록을 빼야함
- 즉, 넣는 곳과 빼는 곳이 같음
- 블록을 넣으려면 1 -> 2 -> 3 의 순서로 들어가고 블록을 빼려면 반대로 3-> 2-> 1의 순서로 뺄 수 있음
- 후입 선출(LIFO, Last In First Out): 가장 마지막에 넣은 3번이 가장 먼저나오는 것을 후입 선출이라 하고 이런 자료구조를 스택이라고 함
- 전통적으로 스택에 값을 넣는 것을 push라고 하며 스택에서 값을 꺼내는 것을 pop이라고함
(2) StackMain
- 실행 결과를 보면 1, 2, 3으로 데이터를 입력했지만 3, 2, 1 로 출력되는 것을 확인할 수 있음
package collection.deque;
public class StackMain {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println(stack);
// 다음 꺼낼 요소 확인(꺼내지 않고 단순히 조회만)
System.out.println("stack.peek() = " + stack.peek());
// 스택 요소 꺼내기
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
}
}
/* 실행 결과
[1, 2, 3]
stack.peek() = 3
stack.pop() = 3
stack.pop() = 2
stack.pop() = 1
*/
** 주의! - Stack 클래스는 사용하지 말자
- 자바의 Stack 클래스는 내부에서 Vector라는 자료 구조를 사용하는데, 이 자료 구조는 자바 1.0에 개발되으며 지금은 사용되지 않고 하위 호환을 위해 존재함
- 지금은 더 빠른 좋은 자료 구조가 많기 때문에 Vector를 사용하는 Stack도 사용하지 않는 것을 권장하며 대신 이후에 설명할 Deque를 사용하는 것이 좋음
3. 큐 자료 구조
2) 큐(Queue)
(1) 구조


- 선입 선출(FIFO, First In First Out): 후입 선출과 반대로 가장 먼저 넣은 것이 가장 먼저 나오는 것을 선입 선출이라 하며 이런 자료구조를 큐(Queue)라고 함
- 1(입력) -> 2(입력) -> 3(입력) -> 1(빼기) -> 2(빼기) -> 3(빼기)와 같이 동작함
- 전통적으로 큐에 값을 넣는 것을 offer라고 하고 큐에서 값을 꺼내는 것을 poll이라고 함
- Queue인터페이스는 List,Set과 같이 Collection의 자식이며 대표적인 구현체는 ArrayDeque, LinkedList가 있음
** 참고
- LinkedList는 Deque와 List 인터페이스를 모두 구현함
(2) QueueMain
- 실행 결과를 보면 먼저 입력한 값이 먼저 출력되는것을 확인할 수 있음
package collection.deque;
public class QueueMain {
public static void main(String[] args) {
Queue<Integer> queue = new ArrayDeque<>();
// Queue<Integer> queue = new LinkedList<>(); // LinkedList도 사용가능하지만 ArrayDeque가 더 빠름
queue.offer(1);
queue.offer(2);
queue.offer(3);
System.out.println(queue);
// 다음 꺼낼 데이터 확인(꺼내지 않고 단순 조회만)
System.out.println("queue.peek() = " + queue.peek());
// 데이터 꺼내기
System.out.println("queue.poll() = " + queue.poll());
System.out.println("queue.poll() = " + queue.poll());
System.out.println("queue.poll() = " + queue.poll());
System.out.println(queue);
}
}
/* 실행 결과
[1, 2, 3]
queue.peek() = 1
queue.poll() = 1
queue.poll() = 2
queue.poll() = 3
[]
*/4. Deque 자료 구조
1) Deque
(1) 구조

- Double Ended Queue의 약자로 양쪽 끝에서 요소를 추가하거나 제거할 수 있음
- 일반적인 큐와 스택의 기능을 모두 포함하고 있어 매우 유연한 자료 구조이며 데크, 덱 등으로 부름
- Deque의 대표적인 구현체는 ArrayDeque와 LinkedList가 있음
- offerFirst(): 앞에 추가
- offerLast(): 뒤에 추가
- pollFirst(): 앞에서 꺼냄
- pollLast(): 뒤에서 꺼냄
(2) DequeMain
- pollFirst()메서드는 데이터를 앞에서 추가하고 offerLast()는 기존 데이터의 뒤에 데이터를 추가하는 것을 확인할 수 있음
- pollFirst()도 데이터의 앞에서 값을 꺼내므로 가장 먼저 2가 꺼내지고 pollLast()는 데이터의 뒤에서 값을 꺼내므로 먼저 4가 꺼내지는 것을 확인할 수 있음
package collection.deque;
public class DequeMain {
public static void main(String[] args) {
Deque<Integer> deque = new ArrayDeque<>();
// Deque<Integer> deque = new LinkedList<>(); // LinkedList도 사용가능하지만 ArrayDeque가 더 빠름
deque.offerFirst(1);
System.out.println(deque);
deque.offerFirst(2);
System.out.println(deque);
deque.offerLast(3);
System.out.println(deque);
deque.offerLast(4);
System.out.println(deque);
// 다음 꺼낼 데이터 확인(꺼내지 않고 단순 조회만)
System.out.println("deque.peekFirst() = " + deque.peekFirst());
System.out.println("deque.peekLast() = " + deque.peekLast());
// 데이터 꺼내기
System.out.println("deque.pollFirst() = " + deque.pollFirst());
System.out.println("deque.pollFirst() = " + deque.pollFirst());
System.out.println("deque.pollLast() = " + deque.pollLast());
System.out.println("deque.pollLast() = " + deque.pollLast());
}
}
/* 실행 결과
[1]
[2, 1]
[2, 1, 3]
[2, 1, 3, 4]
deque.peekFirst() = 2
deque.peekLast() = 4
deque.pollFirst() = 2
deque.pollFirst() = 1
deque.pollLast() = 4
deque.pollLast() = 3
*/
(3) Deque 구현체와 성능 테스트
- Deque의 대표적인 구현체로는 ArrayDeque와 LinkedList가 있는데 둘중에서는 ArrayDeque가 모든 면에서 빠름
- 둘의 차이는 ArrayDeque는 배열을 사용하고 LinkedList는 동적 노드 링크를 사용하기 때문에 ArrayList와 LinkedList의 차이와 비슷함
- ArrayDeque는 추가로 특별한 원형 큐 자료 구조를 사용하는 덕분에 앞, 뒤 입력 모두O(1)의 성능을 제공하며 LinkedList도 앞, 뒤 입력 모두 O(1)의 성능을 제공함
- 그러나 앞에서 ArrayList와 LinkedList의 성능 비교에서 다루었듯이 현대 컴퓨터 시스템의 메모리 접근 패턴이나 CPU 캐시 최적화등을 고려할 때 배열을 사용하는 ArrayDeque가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많음
강의에서의 자료
- 100만 건 입력(앞, 뒤 평균)
- ArrayDeque: 110ms
- LinkedList: 480ms
- 100만 건 조회(앞, 뒤 평균)
- ArrayDeque: 9ms
- LinkedList: 20ms
실제로 성능 테스트를 해본 코드(천만건)
- 실행 결과
- java.util.ArrayDeque, 10000000건 입력 시간: 287ms
- java.util.LinkedList, 10000000건 입력 시간: 1052ms
- java.util.ArrayDeque, 10000000건 출력 시간: 100ms
- java.util.LinkedList, 10000000건 출력 시간: 138ms
package collection.deque;
public class DequeTest {
private static final int VALUE = 10_000_000;
public static void main(String[] args) {
Deque<Integer> arrayDeque = offerDeque(new ArrayDeque<>());
Deque<Integer> linkedList = offerDeque(new LinkedList<>());
pollDeque(arrayDeque);
pollDeque(linkedList);
}
static Deque<Integer> offerDeque(Deque<Integer> deque) {
long startTime = System.currentTimeMillis();
Random random = new Random();
for (int i = 0; i < VALUE; i++) {
int hashIndex = random.nextInt(2);
if (hashIndex == 1) {
deque.addFirst(i);
} else {
deque.addLast(i);
}
}
long endTime = System.currentTimeMillis();
System.out.println(deque.getClass().getName() + ", " + VALUE + "건 입력 시간: " + (endTime - startTime) + "ms");
return deque;
}
static void pollDeque(Deque<Integer> deque) {
long startTime = System.currentTimeMillis();
Random random = new Random();
for (int i = 0; i < VALUE; i++) {
int hashIndex = random.nextInt(2);
if (hashIndex == 1) {
deque.pollFirst();
} else {
deque.pollLast();
}
}
long endTime = System.currentTimeMillis();
System.out.println(deque.getClass().getName() + ", " + VALUE + "건 출력 시간: " + (endTime - startTime) + "ms");
}
}5. Deque와 Stack, Queue
1) Deque, Stack, Queue
(1) Deque 활용
- Deque는 양쪽으로 데이터를 입력하고 출력할 수 있으므로 스택과 큐의 역할을 모두 수행할 수 있으며 Deque를 Stack과 Queue로 사용하기위한 메서드 이름까지 제공함
- 즉, Stack에서 사용하는 push(), pop()과 Queue에서 사용하는 offer()와 poll()을 모두 사용할 수 있음
(2) DequeStackMain
- Deque에서 Stack을 위한 메서드이름을 제공하고 있으며 실행 결과를 보면 Stack 처럼 동작한 결과를 확인할 수 있음
- Stack 클래스는 성능이 좋지 않기 때문에 Stack 자료 구조가 필요하다면 Deque에 ArrayDeque 구현체를 사용하면 됨
package collection.deque;
public class DequeStackMain {
public static void main(String[] args) {
Deque<Integer> deque = new ArrayDeque<>();
deque.push(1);
deque.push(2);
deque.push(3);
System.out.println(deque);
// 다음 꺼낼 데이터 확인(조회만)
System.out.println("deque.peek() = " + deque.peek());
System.out.println("deque.pop() = " + deque.pop());
System.out.println("deque.pop() = " + deque.pop());
System.out.println("deque.pop() = " + deque.pop());
}
}
/* 실행 결과
[3, 2, 1]
deque.peek() = 3
deque.pop() = 3
deque.pop() = 2
deque.pop() = 1
*/
(3) DequeQueueMain
- Deque에서 Queue를 위한 메서드 이름을 제공하고 있으며 실행 결과를보면 Queue처럼 동작하고 있는것을 확인할 수 있음
- Deque 인터페이스는 Queue 인터페이스의 자식이기 때문에 단순히 Queue의 기능만 필요하면 Queue 인터페이스를 사용하고 더 많은 기능이 필요할 때 Deque 인터페이스를 사용하면되며 구현체로 성능이빠른 ArrayDeque를 사용하면 됨
package collection.deque;
public class DequeQueueMain {
public static void main(String[] args) {
Deque<Integer> deque = new ArrayDeque<>();
deque.offer(1);
deque.offer(2);
deque.offer(3);
System.out.println(deque);
// 다음 꺼낼 데이터 확인(조회만)
System.out.println("deque.peek() = " + deque.peek());
System.out.println("deque.pop() = " + deque.poll());
System.out.println("deque.pop() = " + deque.poll());
System.out.println("deque.pop() = " + deque.poll());
}
}
/* 실행 결과
[1, 2, 3]
deque.peek() = 1
deque.pop() = 1
deque.pop() = 2
deque.pop() = 3
*/
6. 문제와 풀이
1) Map1 - 배열을 맵으로 전환
(1) 문제 설명
- 상품의 이름과 가격이 2차원 배열로 제공되며 예제를 참고하여 2차원 배열의 데이터를 Map<String, Integer>로 변경
- 실행 결과를 참고하여 Map을 출력, 출력 순서는 상관 없음
package collection.map.test;
public class ArrayToMapTest {
public static void main(String[] args) {
String[][] productArr = {{"Java", "10000"}, {"Spring", "20000"}, {"JPA", "30000"}};
// 주어진 배열로부터 Map 생성 - 코드 작성
// Map의 모든 데이터 출력 - 코드 작성
}
}
실행 결과
제품: Java, 가격: 10000
제품: JPA, 가격: 30000
제품: Spring, 가격: 20000
(2) 정답
package collection.map.test;
public class ArrayToMapTest {
public static void main(String[] args) {
String[][] productArr = {{"Java", "10000"}, {"Spring", "20000"}, {"JPA", "30000"}};
Map<String, Integer> map = new HashMap<>();
for (String[] product : productArr) {
map.put(product[0], Integer.parseInt(product[1]));
}
for (String key : map.keySet()) {
System.out.println("제품: " + key + ", 가격: " + map.get(key));
}
}
}2) Map2 - 공통의 합
(1) 문제 설명
- 실행 결과를 참고하여 map1과 map2에 공통으로 들어가는 키를 찾고 그 값의 합을 구하기
package collection.map.test;
public class CommonKeyValueSum1 {
public static void main(String[] args) {
Map<String, Integer> map1 = new HashMap<>();
map1.put("A", 1);
map1.put("B", 2);
map1.put("C", 3);
Map<String, Integer> map2 = new HashMap<>();
map2.put("B", 4);
map2.put("C", 5);
map2.put("D", 6);
// 코드 작성
}
}
실행 결과
{B=6, C=8}
(2) 정답
교안 버전
package collection.map.test;
public class CommonKeyValueSum1 {
public static void main(String[] args) {
Map<String, Integer> map1 = new HashMap<>();
map1.put("A", 1);
map1.put("B", 2);
map1.put("C", 3);
Map<String, Integer> map2 = new HashMap<>();
map2.put("B", 4);
map2.put("C", 5);
map2.put("D", 6);
Map<String, Integer> result = new HashMap<>();
for (String key : map1.keySet()) {
if (map2.containsKey(key)) {
result.put(key, map1.get(key) + map2.get(key));
}
}
System.out.println(result);
}
}
직접 푼 버전
package collection.map.test;
public class CommonKeyValueSum1 {
public static void main(String[] args) {
Map<String, Integer> map1 = new HashMap<>();
map1.put("A", 1);
map1.put("B", 2);
map1.put("C", 3);
Map<String, Integer> map2 = new HashMap<>();
map2.put("B", 4);
map2.put("C", 5);
map2.put("D", 6);
map1.keySet().retainAll(map2.keySet());
for (String key : map1.keySet()) {
map1.put(key, map1.get(key) + map2.get(key));
}
System.out.println(map1);
}
}
** 참고
- Map을 생성할 때 Map.of()를 사용하면 편리하게 Map을 생성할 수 있음
- Map.of()를 통해 생성한 Map은 불변이므로 내용을 변경할 수 없음
Map<String, Integer> map1 = Map.of("A", 1, "B", 2, "C", 3);
Map<String, Integer> map2 = Map.of("B", 4, "C", 5, "D", 6);3) Map3 - 같은 단어가 나타난 수
(1) 문제 설명
- 실행 결과를 참고하여 각각의 단어가 나타난 수를 출력
package collection.map.test;
public class WordFrequencyTest1 {
public static void main(String[] args) {
String text = "orange banana apple apple banana apple";
// 코드 작성
}
}
실행 결과
{orange=1, banana=2, apple=3}
(2) 정답
방법1
package collection.map.test;
public class WordFrequencyTest1 {
public static void main(String[] args) {
String text = "orange banana apple apple banana apple";
Map<String, Integer> map = new HashMap<>();
String[] wordArr = text.split(" ");
for (String word : wordArr) {
Integer count = map.get(word);
if (count == null) {
count = 0;
}
count++;
map.put(word, count);
}
System.out.println(map);
}
}
방법2
- getOrDefault()메서드를 사용하면 키가 없는 경우 대신 사용할 기본 값을 지정할 수 있음
package collection.map.test;
public class WordFrequencyTest2 {
public static void main(String[] args) {
String text = "orange banana apple apple banana apple";
Map<String, Integer> map = new HashMap<>();
String[] wordArr = text.split(" ");
for (String word : wordArr) {
map.put(word, map.getOrDefault(word, 0) + 1);
}
System.out.println(map);
}
}4) Map4 - 값으로 검색
(1) 문제 설명
- 실행결과를 참고하여 다음 예제에서 Map에 들어있는 데이터 중에 값이 1000원인 모든 상품을 출력
package collection.map.test;
import java.util.*;
public class ItemPriceTest {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("사과", 500);
map.put("바나나", 500);
map.put("망고", 1000);
map.put("딸기", 1000);
// 코드 작성
}
}
실행 결과
[망고, 딸기]
(2) 정답
직접 푼 버전 - keySet 사용
package collection.map.test;
public class ItemPriceTest {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("사과", 500);
map.put("바나나", 500);
map.put("망고", 1000);
map.put("딸기", 1000);
List<String> result = new ArrayList<>();
for (String key : map.keySet()) {
if (1000 == map.get(key)) {
result.add(key);
}
}
System.out.println(result);
}
}
강의 버전 - entrySet 사용
List<String> list = new ArrayList<>();
for (Map.Entry<String, Integer> entry : map.entrySet()) {
if (entry.getValue().equals(1000)) {
list.add(entry.getKey());
}
}
System.out.println(list);5) Map - 영어 사전 만들기
(1) 문제 설명
- 영어 단어를 입력하면 한글 단어를 찾아주는 영어 사전을 만들기
- 먼저 영어 단어와 한글 단어를 사전에 저장하는 단계를 거친 후 단어를 검색
- 실행결과를 참고하여 DictionayTest에 코드를 완성
실행결과
==단어 입력 단계==
영어 단어를 입력하세요 (종료는 'q'): apple
한글 뜻을 입력하세요: 사과
영어 단어를 입력하세요 (종료는 'q'): banana
한글 뜻을 입력하세요: 바나나
영어 단어를 입력하세요 (종료는 'q'): q
==단어 검색 단계==
찾을 영어 단어를 입력하세요 (종료는 'q'): apple
apple의 뜻: 사과
찾을 영어 단어를 입력하세요 (종료는 'q'): banana
banana의 뜻: 바나나
찾을 영어 단어를 입력하세요 (종료는 'q'): hello
hello은(는) 사전에 없는 단어입니다.
찾을 영어 단어를 입력하세요 (종료는 'q'): q
(2) 정답
직접 푼 버전
package collection.map.test;
public class DictionaryTest {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
Map<String, String> dictionary = new HashMap<>();
System.out.println("== 단어 입력 단계==");
while (true) {
System.out.print("영어 단어를 입력하세요(종료는 'q'): ");
String englishWord = scanner.nextLine();
if(englishWord.equalsIgnoreCase("q")) break;
System.out.print("한글 뜻을 입력하세요: ");
String koreanMeaning = scanner.nextLine();
dictionary.put(englishWord, koreanMeaning);
}
System.out.println("== 단어 검색 단계==");
while (true) {
System.out.print("찾을 영어 단어를 입력하세요(종료는 'q'): ");
String searchWord = scanner.nextLine();
if(searchWord.equalsIgnoreCase("q")) break;
String getMean = dictionary.get(searchWord);
if (getMean == null) {
System.out.println(searchWord + "은(는) 사전에 없는 단어입니다.");
continue;
}
System.out.println(searchWord + "의 뜻: " + getMean);
}
}
}
강의 버전 - 단어 검색 단계의 구현이 조금 다름
package collection.map.test;
public class DictionaryTest2 {
public static void main(String[] args) {
// 동일 코드 생략
System.out.println("== 단어 검색 단계==");
while (true) {
System.out.print("찾을 영어 단어를 입력하세요(종료는 'q'): ");
String searchWord = scanner.nextLine();
if(searchWord.equalsIgnoreCase("q")) break;
String getMean = dictionary.get(searchWord);
if (dictionary.containsKey(searchWord)) {
String koreanMeaning = dictionary.get(searchWord);
System.out.println(searchWord + "의 뜻: " + koreanMeaning);
} else {
System.out.println(searchWord + "은(는) 사전에 없는 단어입니다.");
}
}
}
}ㅁ
6) Map6 - 회원 관리 저장소
(1) 문제 설명
- Map을 사용해서 회원을 저장하고 관리하는 MemberRepository 코드를 완성
- Member, MemberRepositoryMain 코드와 실행 결과를 참고
Member
package collection.map.test.member;
public class Member {
private String id;
private String name;
public Member(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Member{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
'}';
}
}
MemberRepositoryMain
package collection.map.test.member;
public class MemberRepositoryMain {
public static void main(String[] args) {
Member member1 = new Member("id1", "회원1");
Member member2 = new Member("id2", "회원2");
Member member3 = new Member("id3", "회원3");
// 회원 저장
MemberRepository repository = new MemberRepository();
repository.save(member1);
repository.save(member2);
repository.save(member3);
// 회원 조회
Member findMember1 = repository.findById("id1");
System.out.println("findMember1 = " + findMember1);
Member findMember3 = repository.findByName("회원3");
System.out.println("findMember3 = " + findMember3);
// 회원 삭제
repository.remove("id1");
Member removedMember1 = repository.findById("id1");
System.out.println("removedMember1 = " + removedMember1);
}
}
MemberRepository
public class MemberRepository {
private Map<String, String> memberMap = new HashMap<>();
public void save(Member member) {
// 코드 작성
}
public void remove(String id) {
// 코드 작성
}
public Member findById(String id) {
// 코드 작성
}
public Member findByName(String name) {
// 코드 작성
}
}실행 결과
findMember1 = Member{id='id1', name='회원1'}
findMember3 = Member{id='id3', name='회원3'}
removedMember1 = null
(2) 정답
package collection.map.test.member;
public class MemberRepository {
private Map<String, Member> memberMap = new HashMap<>();
public void save(Member member) {
memberMap.put(member.getId(), member);
}
public void remove(String id) {
memberMap.remove(id);
}
public Member findById(String id) {
return memberMap.get(id);
}
public Member findByName(String name) {
for (Member member : memberMap.values()) {
if (member.getName().equals(name)) {
return member;
}
}
return null;
}
}7) Map7 - 장바구니
(1) 문제 설명
- 장바구니 추가 - add()
- 장바구니에 상품과 수량을 담음, 상품의 이름과 가격이 같으면 같은 상품임
- 장바구니에 이름과 가격이 같은 상품을 추가하면 기존에 담긴 상품에 수량만 추가됨
- 장바구니에 이름과 가격이 다른 상품을 추가하면 새로운 상품이 추가됨
- 장바구니 제거 - minus()
- 장바구니에 담긴 상품의 수량을 줄일 수 있음, 만약 수량이 0보다 작다면 상품이 장바구니에서 제거됨
- CartMain과 실행 결과를 참고하여 Product, Cart 클래스를 완성
- Cart 클래스는 Map을 통해 상품을 장바구니에 보관함
- Map의 Key는 Product가 사용되고 Value는 장바구니에 담은 수량이 사용됨
CartMain
package collection.map.test.cart;
public class CartMain {
public static void main(String[] args) {
Cart cart = new Cart();
cart.add(new Product("사과", 1000), 1);
cart.add(new Product("바나나", 500), 1);
cart.printAll();
cart.add(new Product("사과", 1000), 2);
cart.printAll();
cart.minus(new Product("사과", 1000), 3);
cart.printAll();
}
}
Product, Cart
package collection.map.test.cart;
public class Product {
private String name;
private int price;
// 코드 작성
}
package collection.map.test.cart;
public class Cart {
private Map<Product, Integer> cartMap = new HashMap<>();
// 코드 작성
}
실행 결과
==모든 상품 출력==
상품: Product{name='사과', price=1000} 수량: 1
상품: Product{name='바나나', price=500} 수량: 1
==모든 상품 출력==
상품: Product{name='사과', price=1000} 수량: 3
상품: Product{name='바나나', price=500} 수량: 1
==모든 상품 출력==
상품: Product{name='바나나', price=500} 수량: 1
(2) 정답
Product
- Map의 Key로 Product가 사용되기 때문에 반드시 hashCode()와 equals()를 재정의해야함
package collection.map.test.cart;
public class Product {
private String name;
private int price;
public Product(String name, int price) {
this.name = name;
this.price = price;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Product product = (Product) o;
return price == product.price && Objects.equals(name, product.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
@Override
public String toString() {
return "Product{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
Cart
package collection.map.test.cart;
public class Cart {
private Map<Product, Integer> cartMap = new HashMap<>();
public void add(Product product, int quantity) {
Integer existingQuantity = cartMap.getOrDefault(product, 0);
cartMap.put(product, existingQuantity + quantity);
}
public void minus(Product product, int quantity) {
Integer existingQuantity = cartMap.getOrDefault(product, 0);
int newQuantity = existingQuantity - quantity;
if (newQuantity <= 0) {
cartMap.remove(product);
return;
}
cartMap.put(product, newQuantity);
}
public void printAll() {
System.out.println("==모든 상품 출력==");
for (Map.Entry<Product, Integer> entry : cartMap.entrySet()) {
System.out.println("상품: " + entry.getKey() + " 수량: " + entry.getValue());
}
}
}8) Stack1 - 간단한 히스토리 확인
(1) 문제 설명
- 스택에 push()를 통해서 다음 데이터를 순서대로 입력
- "youtube.com"
- "google.com"
- "facebook.com"
- 스택에 pop()을 통해서 데이터를 꺼내고, 꺼낸 순서대로 출력
- "facebook.com"
- "google.com"
- "youtube.com"
- 가장 마지막에 입력한 데이터가 가장 먼저 출력됨
package collection.deque.test.stack;
public class SimpleHistoryTest {
public static void main(String[] args) {
Deque<String> stack = new ArrayDeque<>();
// 코드 작성
}
}- Stack을 사용해도 되지만 Deque 인터페이스에 ArrayDeque 구현체를 사용하는 것이 성능상 더 나은 선택임
실행 결과
facebook.com
google.com
youtube.com
(2) 정답
package collection.deque.test.stack;
public class SimpleHistoryTest {
public static void main(String[] args) {
Deque<String> stack = new ArrayDeque<>();
stack.push("youtube.com");
stack.push("google.com");
stack.push("facebook.com");
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
}
}9) Stack2 - 브라우저 히스토리 관리
(1) 문제 설명
- BrowserHistoryTest와 실행 결과를 참고하여 BrowserHistory클래스를 완성하여 브라우저의 방문 기록 관리 기능을 개발
- visitPage(): 특정 페이지 방문
- goBack(): 뒤로가기
- 뒤로가기는 가장 나중에 넣은 데이터가 먼저 나오기 때문에 스택 구조를 고려하는 것이 좋음
package collection.deque.test.stack;
public class BrowserHistoryTest {
public static void main(String[] args) {
BrowserHistory browser = new BrowserHistory();
// 사용자가 웹페이지를 방문하는 시나리오
browser.visitPage("youtube.com");
browser.visitPage("google.com");
browser.visitPage("facebook.com");
// 뒤로 가기 기능을 사용하는 시나리오
String currentPage1 = browser.goBack();
System.out.println("currentPage1 = " + currentPage1);
String currentPage2 = browser.goBack();
System.out.println("currentPage2 = " + currentPage2);
}
}
실행 결과
방문: youtube.com
방문: google.com
방문: facebook.com
뒤로 가기: google.com
currentPage1 = google.com
뒤로 가기: youtube.com
currentPage2 = youtube.com
(2) 정답
package collection.deque.test.stack;
public class BrowserHistory {
private Deque<String> history = new ArrayDeque<>();
private String currentPage = null;
public void visitPage(String url) {
if (currentPage != null) {
history.push(currentPage);
}
currentPage = url;
System.out.println("방문: " + url);
}
public String goBack() {
if (!history.isEmpty()) {
String currentPage = history.pop();
System.out.println("뒤로 가기: " + currentPage);
return currentPage;
}
return null;
}
}10) Queue1 - 프린터 대기
(1) 문제 설명
- 프린터에 여러 문서의 출력을 요청하면 한번에 모든 문서를 출력할 수 없으므로 순서대로 출력해야 함
- 문서가 대기할 수 있도록 큐 구조를 사용
- 실행 결과를 참고하여 "doc1", "doc2", "doc3" 문서를 순서대로 입력하고 입력된 순서대로 출력
package collection.deque.test.queue;
public class PrinterQueueTest {
public static void main(String[] args) {
Queue<String> printQueue = new ArrayDeque<>();
// 코드 작성
}
}
실행 결과
출력: doc1
출력: doc2
출력: doc3
(2) 정답
package collection.deque.test.queue;
public class PrinterQueueTest {
public static void main(String[] args) {
Queue<String> printQueue = new ArrayDeque<>();
printQueue.offer("doc1");
printQueue.offer("doc2");
printQueue.offer("doc3");
System.out.println("출력: " + printQueue.poll());
System.out.println("출력: " + printQueue.poll());
System.out.println("출력: " + printQueue.poll());
}
}11) Queue2 - 작업 예약
(1) 문제 설명
- 서비스를 운영 중인데 낮 시간에는 사용자가 많아서 서버에서 무거운 작업을 하기 부담스러워 무거운 작업을 예약해두고 사용자가 없는 새벽에 실행하도록 개발
- 다양한 무거운 작업을 새벽에 실행한다고 가정하며 작업은 자유롭게 구현하고 자유롭게 예약할 수 있어야 함
- 다음 예제 코드와 실행 결과를 참고하여 TaskScheduler 클래스를 완성
Task
package collection.deque.test.queue;
public interface Task {
void execute();
}
CompressionTask
package collection.deque.test.queue;
public class CompressionTask implements Task{
@Override
public void execute() {
System.out.println("데이터 압축...");
}
}
BackupTask
package collection.deque.test.queue;
public class BackupTask implements Task{
@Override
public void execute() {
System.out.println("자료 백업...");
}
}
CleanTask
package collection.deque.test.queue;
public class CleanTask implements Task{
@Override
public void execute() {
System.out.println("사용하지 않는 자원 정리...");
}
}
SchedulerTest
package collection.deque.test.queue;
public class SchedulerTest {
public static void main(String[] args) {
// 낮에 작업을 저장
TaskScheduler scheduler = new TaskScheduler();
scheduler.addTask(new CompressionTask());
scheduler.addTask(new BackupTask());
scheduler.addTask(new CleanTask());
// 새벽 시간에 실행
System.out.println("작업 시작");
run(scheduler);
System.out.println("작업 완료");
}
private static void run(TaskScheduler scheduler) {
while(scheduler.getRemainingTasks() > 0) {
scheduler.processNextTask();
}
}
}
실행 결과
작업 시작
데이터 압축...
자료 백업...
사용하지 않는 자원 정리...
작업 완료
(2) 정답
package collection.deque.test.queue;
public class TaskScheduler {
private Queue<Task> tasks = new ArrayDeque<>();
public void addTask(Task task) {
tasks.offer(task);
}
public int getRemainingTasks() {
return tasks.size();
}
public void processNextTask() {
Task task = tasks.poll();
if (task != null) {
task.execute();
}
}
}


